
Augmentarea setului de date: crearea datelor artificiale [explicat simplu]
Publicat: 2020-12-07Cuprins
Introducere
Când proiectați orice algoritm de învățare automată, trebuie întotdeauna să mențineți compromisul între optimizare și generalizare . Aceste cuvinte pot părea prea complicate pentru începători, dar cunoașterea diferenței dintre ele într-un stadiu incipient în timpul călătoriei lor către stăpânirea învățării automate îi va ajuta cu siguranță să înțeleagă funcționarea de bază a motivului pentru care modelul lor se comportă într-un anumit mod.
Aspectul de optimizare se referă la reglarea modelului astfel încât performanța acestuia asupra datelor de antrenament să fie la apogeu. Pe de altă parte, generalizarea se referă la performanța unui model de învățare pe date pe care nu le-a văzut niciodată până acum, adică pe un set de validare.
Adesea vine un moment în care după un anumit număr de epoci asupra datelor de antrenament, generalizarea modelului încetează să se îmbunătățească și metricile de validare încep să se degradeze, acesta este cazul în care se spune că modelul se supraajustează, adică în care începe să învețe informații specifice pentru datele de antrenament, dar nu sunt utile pentru corelarea cu date noi.
Pentru a aborda problema supraadaptării, cea mai bună soluție este de a aduna mai multe date de antrenament: cu cât modelul a văzut mai multe date, cu atât este mai mare probabilitatea acestuia de a învăța și reprezentările noilor date. Cu toate acestea, strângerea mai multor date de antrenament poate fi mai costisitoare decât rezolvarea problemei principale pe care trebuie să o abordăm. Pentru a ocoli această limitare, putem crea date false și le putem adăuga la setul de antrenament. Acest lucru este cunoscut sub numele de creștere a datelor.
Mărirea datelor în profunzime
Premisa învățării reprezentărilor vizuale din imagini a ajutat la rezolvarea multor probleme de vedere pe computer. Cu toate acestea, atunci când avem un set de date mai mic pe care să ne antrenăm, atunci aceste reprezentări vizuale pot induce în eroare. Mărirea datelor este o strategie excelentă pentru a depăși acest dezavantaj.
În timpul creșterii, imaginile din setul de antrenament sunt transformate prin anumite operații precum rotație, scalare, forfecare etc. De exemplu: dacă setul de antrenament constă numai din imagini ale oamenilor aflați în poziție în picioare, atunci clasificatorul pe care încercăm să-l construim poate nu reușește să prezică imaginile oamenilor întinși, astfel încât mărirea poate simula imaginea oamenilor întinși prin rotirea imaginilor setului de antrenament cu 90 de grade.

Aceasta este o modalitate ieftină și semnificativă de a extinde setul de date și de a crește valorile de validare a modelului.
Mărirea datelor este un instrument puternic în special pentru probleme de clasificare, cum ar fi recunoașterea obiectelor. Operațiuni precum traducerea imaginilor de antrenament cu câțiva pixeli în fiecare direcție pot deseori îmbunătăți considerabil generalizarea.
O altă caracteristică avantajoasă a creșterii este că imaginile sunt transformate în flux, ceea ce înseamnă că setul de date existent nu este suprascris. Mărirea va avea loc atunci când imaginile sunt încărcate în rețeaua neuronală pentru antrenament și, prin urmare, acest lucru nu va crește cerințele de memorie și nu va păstra și datele pentru experimente ulterioare.
Aplicarea tehnicilor de translație precum augmentarea este foarte utilă acolo unde colectarea de date noi este costisitoare, deși trebuie să țineți cont de a nu aplica transformarea care ar putea schimba distribuția existentă a clasei de antrenament. De exemplu, dacă setul de antrenament include imagini cu cifre scrise de mână de la 0 la 9, atunci răsturnarea/rotirea cifrelor „6” și „9” nu este o transformare adecvată, deoarece aceasta va face ca setul de antrenament să fie depășit.
Citește și: Top idei de proiecte pentru seturi de date de învățare automată
Utilizarea creșterii datelor cu TensorFlow
Augmentarea poate fi realizată utilizând API-ul ImageDataGenerator de la Keras folosind TensorFlow ca backend. Instanța ImageDataGenerator poate efectua o serie de transformări aleatorii asupra imaginilor la punctul de antrenament. Unele dintre argumentele populare disponibile în acest caz sunt:

- rotation_range: o valoare întreagă în grade între 0-180 pentru a roti aleatoriu imaginile.
- width_shift_range: Deplasarea orizontală a imaginii în jurul cadrului său pentru a genera mai multe exemple.
- height_shift_range: Deplasarea verticală a imaginii în jurul cadrului său pentru a genera mai multe exemple.
- shear_range: aplicați transformări aleatoare de forfecare pe imagine pentru a genera mai multe exemple.
- zoom_range: porțiune relativă a imaginii pentru a mări aleatoriu.
- horizontal_flip: Folosit pentru a răsturna imaginile pe orizontală.
- fill_mode: Metodă de umplere a pixelilor nou creați.
Mai jos este fragmentul de cod care demonstrează cum poate fi utilizată instanța ImageDataGenerator pentru a efectua transformarea menționată mai sus:
- train_datagen = ImageDataGenerator(
- redimensionare=1./255,
- interval_rotație=40,
- width_shift_range=0,2,
- înălțime_schift_range=0,2,
- shear_range=0,2,
- zoom_range=0,2,
- horizontal_flip=Adevărat,
- fill_mode='cel mai apropiat')
De asemenea, este trivial să vedem rezultatul aplicării acestor transformări aleatorii pe setul de antrenament. Pentru aceasta, putem afișa câteva imagini de antrenament augmentate aleatoriu prin iterarea setului de antrenament:

Figura 1: Imagini generate folosind augmentare
(Imagine din Deep Learning with Python de Francois Chollet, capitolul 5, pagina 140)
Figura 1 ne oferă o idee despre modul în care augmentarea poate produce mai multe imagini dintr-o singură imagine de intrare, toate imaginile fiind superficial diferite unele de altele doar din cauza transformărilor aleatorii care au fost efectuate asupra lor în timpul antrenamentului.
Pentru a înțelege adevărata esență a utilizării strategiilor de augmentare, trebuie să înțelegem impactul acestora asupra parametrilor de formare și validare a modelului. Pentru aceasta, vom antrena două modele: unul nu va folosi creșterea datelor și celălalt va. Pentru a valida acest lucru, vom folosi setul de date Cats and Dogs care este disponibil la:
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
Curbele de precizie care au fost observate pentru ambele modele sunt reprezentate mai jos:
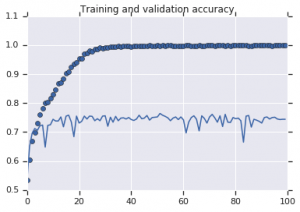
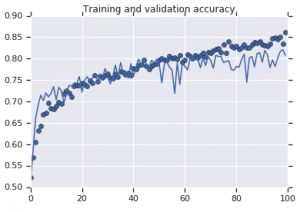
Figura 2: Precizia instruirii și validării. Stânga : Model fără mărire. Dreapta : Model cu transformări aleatorii de mărire a datelor.
Trebuie citit: Cele mai bune seturi de date stabilite pentru analiza sentimentelor
Concluzie
Din Figura 2 este evident că modelul antrenat fără strategii de augmentare prezintă o putere scăzută de generalizare. Performanța modelului pe setul de validare nu este la egalitate cu cea pe setul de antrenament. Aceasta înseamnă că modelul s-a supraadaptat.
Pe de altă parte, cel de-al doilea model care utilizează strategii de augmentare arată metrici excelente, cu precizia validării urcând la fel de mare ca precizia antrenamentului. Acest lucru demonstrează cât de util devine folosirea tehnicilor de creștere a setului de date în cazul în care un model prezintă semne de supraadaptare.
Dacă mai sunteți interesat să aflați despre analiza sentimentelor și tehnologiile asociate, cum ar fi inteligența artificială și învățarea automată, puteți consulta cursul nostru PG Diploma în învățare automată și AI .