
Aumento de conjuntos de datos: creación de datos artificiales [explicado de forma sencilla]
Publicado: 2020-12-07Tabla de contenido
Introducción
Al diseñar cualquier algoritmo de aprendizaje automático, siempre se debe mantener el equilibrio entre la optimización y la generalización . Estas palabras pueden parecer demasiado intrincadas para los novatos, pero conocer la diferencia entre ellas en una etapa temprana durante su viaje para dominar el aprendizaje automático definitivamente los ayudará a comprender el funcionamiento subyacente de por qué su modelo se comporta de una manera particular.
El aspecto de la optimización se refiere a ajustar el modelo de manera que su rendimiento en los datos de entrenamiento esté en su punto máximo. Por otro lado, la generalización se refiere al rendimiento de un modelo de aprendizaje sobre datos que nunca antes había visto, es decir, sobre un conjunto de validación.
A menudo llega un momento en que después de un cierto número de épocas en los datos de entrenamiento, la generalización del modelo deja de mejorar y las métricas de validación comienzan a degradarse, este es el caso en el que se dice que el modelo se sobreajusta, es decir, cuando comienza a aprender información específica para los datos de entrenamiento pero no es útil para correlacionar con nuevos datos.
Para abordar el problema del sobreajuste, la mejor solución es recopilar más datos de entrenamiento: cuantos más datos haya visto el modelo, mayor será su probabilidad de aprender también representaciones de los nuevos datos. Sin embargo, recopilar más datos de entrenamiento puede resultar más costoso que resolver el problema principal que se debe abordar. Para sortear esta limitación, podemos crear datos falsos y agregarlos al conjunto de entrenamiento. Esto se conoce como aumento de datos.
Aumento de datos en profundidad
La premisa de aprender representaciones visuales a partir de imágenes ha ayudado a resolver muchos problemas de visión por computadora. Sin embargo, cuando tenemos un conjunto de datos más pequeño para entrenar, estas representaciones visuales pueden ser engañosas. El aumento de datos es una excelente estrategia para superar este inconveniente.
Durante el aumento, las imágenes en el conjunto de entrenamiento se transforman mediante ciertas operaciones como rotación, escalado, corte, etc. Por ejemplo: si el conjunto de entrenamiento consta de imágenes de humanos en una posición de pie solamente, entonces el clasificador que estamos tratando de construir puede fallar al predecir las imágenes de humanos acostados, por lo que el aumento puede simular la imagen de humanos acostados girando las imágenes del conjunto de entrenamiento 90 grados.

Esta es una forma económica y significativa de ampliar el conjunto de datos y aumentar las métricas de validación del modelo.
El aumento de datos es una herramienta poderosa, especialmente para problemas de clasificación como el reconocimiento de objetos. Operaciones como traducir las imágenes de entrenamiento unos pocos píxeles en cada dirección a menudo pueden mejorar en gran medida la generalización.
Otra característica ventajosa del aumento es que las imágenes se transforman en el flujo, lo que significa que el conjunto de datos existente no se anula. El aumento se llevará a cabo cuando las imágenes se carguen en la red neuronal para el entrenamiento y, por lo tanto, esto no aumentará los requisitos de memoria y conservará los datos para una mayor experimentación.
La aplicación de técnicas de traducción como el aumento es muy útil cuando la recopilación de nuevos datos es costosa, aunque se debe tener en cuenta que no se debe aplicar una transformación que pueda cambiar la distribución existente de la clase de entrenamiento. Por ejemplo, si el conjunto de entrenamiento incluye imágenes de dígitos escritos a mano del 0 al 9, entonces voltear/rotar los dígitos "6" y "9" no es una transformación adecuada, ya que esto hará que el conjunto de entrenamiento quede obsoleto.
Lea también: Principales ideas de proyectos de conjuntos de datos de aprendizaje automático
Uso del aumento de datos con TensorFlow
El aumento se puede lograr usando la API ImageDataGenerator de Keras usando TensorFlow como backend. La instancia de ImageDataGenerator puede realizar una serie de transformaciones aleatorias en las imágenes en el punto de entrenamiento. Algunos de los argumentos populares disponibles en este caso son:

- rango_de_rotación : un valor entero en grados entre 0 y 180 para rotar imágenes aleatoriamente.
- width_shift_range: Desplazar la imagen horizontalmente alrededor de su marco para generar más ejemplos.
- height_shift_range: desplazar la imagen verticalmente alrededor de su marco para generar más ejemplos.
- shear_range: aplique transformaciones de corte aleatorias en la imagen para generar múltiples ejemplos.
- zoom_range: Porción relativa de la imagen para hacer zoom aleatoriamente.
- horizontal_flip: se utiliza para voltear las imágenes horizontalmente.
- fill_mode: Método para rellenar píxeles recién creados.
A continuación se muestra el fragmento de código que demuestra cómo se puede utilizar la instancia de ImageDataGenerator para realizar la transformación mencionada anteriormente:
- train_datagen = ImageDataGenerator(
- reescalar=1./255,
- rango_de_rotación=40,
- ancho_cambio_rango=0.2,
- altura_cambio_rango=0.2,
- cortante_rango=0.2,
- zoom_rango=0.2,
- horizontal_flip=Verdadero,
- fill_mode='más cercano')
También es trivial ver el resultado de aplicar estas transformaciones aleatorias en el conjunto de entrenamiento. Para esto, podemos mostrar algunas imágenes de entrenamiento aumentadas aleatoriamente iterando sobre el conjunto de entrenamiento:

Figura 1: Imágenes generadas usando aumento
(Imagen de Aprendizaje profundo con Python por Francois Chollet, Capítulo 5, página 140)
La Figura 1 nos da una idea de cómo el aumento puede producir múltiples imágenes a partir de una sola imagen de entrada con todas las imágenes superficialmente diferentes entre sí solo debido a las transformaciones aleatorias que se realizaron en ellas en el momento del entrenamiento.
Para comprender la verdadera esencia del uso de estrategias de aumento, debemos comprender su impacto en las métricas de entrenamiento y validación del modelo. Para ello, entrenaremos dos modelos: uno no usará aumento de datos y el otro sí. Para validar esto, utilizaremos el conjunto de datos de perros y gatos que está disponible en:
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
Las curvas de precisión que se observaron para ambos modelos se representan a continuación:
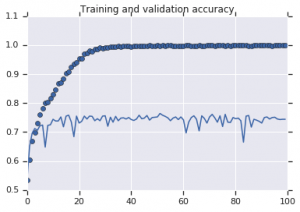
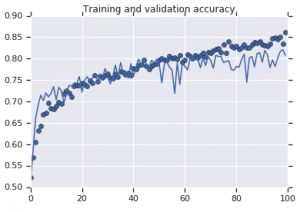
Figura 2: Precisión de entrenamiento y validación. Izquierda : modelo sin aumento. Derecha : modelo con transformaciones de aumento de datos aleatorios.
Debe leer: Principales conjuntos de datos establecidos para análisis de sentimiento
Conclusión
Es evidente a partir de la Figura 2 que el modelo entrenado sin estrategias de aumento muestra un bajo poder de generalización. El rendimiento del modelo en el conjunto de validación no está a la par con el del conjunto de entrenamiento. Esto significa que el modelo se ha sobreajustado.
Por otro lado, el segundo modelo que usa estrategias de aumento muestra excelentes métricas con la precisión de validación subiendo tan alto como la precisión de entrenamiento. Esto demuestra cuán útil se vuelve emplear técnicas de aumento de conjuntos de datos donde un modelo muestra signos de sobreajuste.
Si está más interesado en aprender sobre el análisis de sentimientos y las tecnologías asociadas, como la inteligencia artificial y el aprendizaje automático, puede consultar nuestro curso PG Diploma in Machine Learning and AI .