
Augmentation de l'ensemble de données : créer des données artificielles [expliqué simplement]
Publié: 2020-12-07Table des matières
introduction
Lors de la conception d'un algorithme d'apprentissage automatique, il faut toujours maintenir le compromis entre optimisation et généralisation . Ces mots peuvent sembler trop complexes pour les novices, mais connaître la différence entre eux à un stade précoce de leur parcours vers la maîtrise de l'apprentissage automatique les aidera certainement à comprendre le fonctionnement sous-jacent de la raison pour laquelle leur modèle se comporte d'une manière particulière.
L'aspect de l'optimisation fait référence au réglage du modèle de sorte que ses performances sur les données d'apprentissage soient à leur apogée. D'autre part, la généralisation porte sur les performances d'un modèle d'apprentissage sur des données qu'il n'a jamais vues auparavant, c'est-à-dire sur un ensemble de validation.
Il arrive souvent un moment où après un certain nombre d'époques sur les données d'apprentissage, la généralisation du modèle cesse de s'améliorer et les métriques de validation commencent à se dégrader, c'est le cas où le modèle est dit sur- ajusté, c'est à dire où il commence à apprendre des informations propres à les données de formation, mais pas utile pour la corrélation avec de nouvelles données.
Pour résoudre le problème du surajustement, la meilleure solution consiste à collecter davantage de données d'apprentissage : plus le modèle a vu de données, meilleure est sa probabilité d'apprendre également des représentations des nouvelles données. Cependant, la collecte de plus de données de formation peut être plus coûteuse que la résolution du problème principal auquel on doit s'attaquer. Pour contourner cette limitation, nous pouvons créer de fausses données et les ajouter à l'ensemble d'entraînement. C'est ce qu'on appelle l'augmentation des données.
Augmentation des données en profondeur
La prémisse d'apprendre des représentations visuelles à partir d'images a aidé à résoudre de nombreux problèmes de vision par ordinateur. Cependant, lorsque nous avons un ensemble de données plus petit sur lequel nous former, ces représentations visuelles peuvent être trompeuses. L'augmentation des données est une excellente stratégie pour surmonter cet inconvénient.
Lors de l'augmentation, les images de l'ensemble d'apprentissage sont transformées par certaines opérations comme la rotation, la mise à l'échelle, le cisaillement, etc. Par exemple : si l'ensemble d'apprentissage se compose d'images d'humains en position debout uniquement, alors le classificateur que nous essayons de construire peut ne pas prédire les images d'humains allongés, de sorte que l'augmentation peut simuler l'image d'humains allongés en faisant pivoter les images de l'ensemble d'entraînement de 90 degrés.

Il s'agit d'un moyen peu coûteux et significatif d'étendre l'ensemble de données et d'augmenter les métriques de validation du modèle.
L'augmentation des données est un outil puissant, en particulier pour les problèmes de classification tels que la reconnaissance d'objets. Des opérations telles que la translation des images d'entraînement de quelques pixels dans chaque direction peuvent souvent améliorer considérablement la généralisation.
Une autre caractéristique avantageuse de l'augmentation est que les images sont transformées sur le flux, ce qui signifie que l'ensemble de données existant n'est pas remplacé. L'augmentation aura lieu lorsque les images seront chargées dans le réseau neuronal pour la formation et, par conséquent, cela n'augmentera pas les besoins en mémoire et préservera également les données pour une expérimentation ultérieure.
L'application de techniques translationnelles telles que l'augmentation est très utile lorsque la collecte de nouvelles données est coûteuse, bien qu'il faille garder à l'esprit de ne pas appliquer de transformation susceptible de modifier la distribution existante de la classe d'entraînement. Par exemple, si l'ensemble d'apprentissage comprend des images de chiffres manuscrits de 0 à 9, le retournement/la rotation des chiffres « 6 » et « 9 » n'est pas une transformation appropriée car cela rendra l'ensemble d'apprentissage obsolète.
Lisez également : Meilleures idées de projets d'ensembles de données d'apprentissage automatique
Utilisation de l'augmentation des données avec TensorFlow
L'augmentation peut être obtenue en utilisant l' API ImageDataGenerator de Keras en utilisant TensorFlow comme backend. L' instance ImageDataGenerator peut effectuer un certain nombre de transformations aléatoires sur les images au point d'apprentissage. Certains des arguments populaires disponibles dans ce cas sont :

- rotation_range : une valeur entière en degrés entre 0 et 180 pour faire pivoter les images de manière aléatoire.
- width_shift_range : décaler l'image horizontalement autour de son cadre pour générer plus d'exemples.
- height_shift_range : décaler l'image verticalement autour de son cadre pour générer plus d'exemples.
- shear_range : appliquez des transformations de cisaillement aléatoires sur l'image pour générer plusieurs exemples.
- zoom_range : partie relative de l'image à zoomer de manière aléatoire.
- horizontal_flip : utilisé pour retourner les images horizontalement.
- fill_mode : méthode de remplissage des pixels nouvellement créés.
Vous trouverez ci-dessous l'extrait de code qui montre comment l' instance ImageDataGenerator peut être utilisée pour effectuer la transformation susmentionnée :
- train_datagen = ImageDataGenerator(
- remise à l'échelle=1./255,
- rotation_range=40,
- width_shift_range=0.2,
- height_shift_range=0.2,
- shear_range=0.2,
- zoom_range=0.2,
- horizontal_flip=Vrai,
- fill_mode='le plus proche')
Il est également trivial de voir le résultat de l'application de ces transformations aléatoires sur l'ensemble d'apprentissage. Pour cela, nous pouvons afficher des images d'entraînement augmentées de manière aléatoire en parcourant l'ensemble d'entraînement :

Figure 1 : Images générées à l'aide de l'augmentation
(Image tirée de Deep Learning with Python par François Chollet, chapitre 5, page 140)
La figure 1 nous donne une idée de la façon dont l'augmentation peut produire plusieurs images à partir d'une seule image d'entrée, toutes les images étant superficiellement différentes les unes des autres uniquement en raison des transformations aléatoires qui ont été effectuées sur elles au moment de la formation.
Pour comprendre la véritable essence de l'utilisation de stratégies d'augmentation, nous devons comprendre son impact sur les mesures de formation et de validation du modèle. Pour cela, nous allons former deux modèles : l'un n'utilisera pas l'augmentation de données et l'autre le fera. Pour valider cela, nous utiliserons l' ensemble de données Cats and Dogs qui est disponible sur :
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
Les courbes de précision observées pour les deux modèles sont tracées ci-dessous :
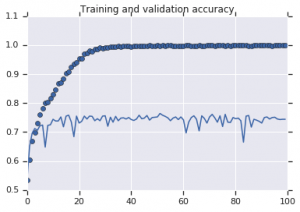
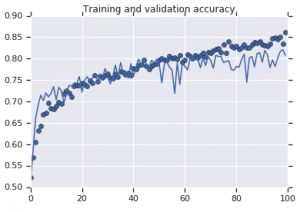
Figure 2 : Précision de la formation et de la validation. A gauche : Modèle sans augmentation. Droite : Modèle avec transformations d'augmentation de données aléatoires.
Doit lire : les meilleurs ensembles de données établis pour l'analyse des sentiments
Conclusion
Il ressort de la figure 2 que le modèle formé sans stratégies d'augmentation affiche un faible pouvoir de généralisation. Les performances du modèle sur l'ensemble de validation ne sont pas équivalentes à celles de l'ensemble d'apprentissage. Cela signifie que le modèle est surajusté.
D'autre part, le deuxième modèle qui utilise des stratégies d'augmentation montre d'excellentes métriques avec la précision de la validation grimpant aussi haut que la précision de la formation. Cela montre à quel point il devient utile d'utiliser des techniques d'augmentation d'ensembles de données lorsqu'un modèle montre des signes de surajustement.
Si vous souhaitez en savoir plus sur l'analyse des sentiments et les technologies associées, telles que l'intelligence artificielle et l'apprentissage automatique, vous pouvez consulter notre cours PG Diploma in Machine Learning and AI .