
زيادة مجموعة البيانات: إنشاء بيانات اصطناعية [شرح ببساطة]
نشرت: 2020-12-07جدول المحتويات
مقدمة
أثناء تصميم أي خوارزمية للتعلم الآلي ، يحتاج المرء دائمًا إلى الحفاظ على المفاضلة بين التحسين والتعميم . قد تبدو هذه الكلمات معقدة للغاية بالنسبة للمبتدئين ، ولكن معرفة الفرق بينهم في مرحلة مبكرة خلال رحلتهم لإتقان التعلم الآلي سيساعدهم بالتأكيد على فهم العمل الأساسي وراء سبب تصرف نموذجهم بطريقة معينة.
يشير جانب التحسين إلى ضبط النموذج بحيث يكون أدائه على بيانات التدريب في ذروته. من ناحية أخرى ، يتعلق التعميم بأداء نموذج التعلم على البيانات التي لم يسبق له مثيل من قبل ، أي على مجموعة التحقق من الصحة.
غالبًا ما يأتي وقت عندما يتوقف تعميم النموذج عن التحسن بعد عدد معين من الحقب على بيانات التدريب ، وتبدأ مقاييس التحقق من الصحة في التدهور ، وهذه هي الحالة التي يقال فيها إن النموذج قد زاد ، أي حيث يبدأ في تعلم المعلومات الخاصة بـ بيانات التدريب ولكنها ليست مفيدة للارتباط بالبيانات الجديدة.
لمعالجة مشكلة فرط التخصيص ، فإن الحل الأفضل هو جمع المزيد من بيانات التدريب: فكلما زاد عدد البيانات التي شاهدها النموذج ، كان احتمال تعلم تمثيل البيانات الجديدة أفضل أيضًا. ومع ذلك ، قد يكون جمع المزيد من بيانات التدريب أكثر تكلفة من حل المشكلة الرئيسية التي يحتاج المرء إلى معالجتها. للتغلب على هذا القيد ، يمكننا إنشاء بيانات مزيفة وإضافتها إلى مجموعة التدريب. يُعرف هذا باسم زيادة البيانات.
زيادة البيانات في العمق
ساعدت فرضية تعلم التمثيلات المرئية من الصور في حل العديد من مشاكل رؤية الكمبيوتر. ومع ذلك ، عندما يكون لدينا مجموعة بيانات أصغر للتدرب عليها ، فقد تكون هذه التمثيلات المرئية مضللة. تعد زيادة البيانات استراتيجية ممتازة للتغلب على هذا العيب.
أثناء الزيادة ، يتم تحويل الصور الموجودة في مجموعة التدريب من خلال عمليات معينة مثل التدوير ، والقياس ، والقص ، وما إلى ذلك. على سبيل المثال: إذا كانت مجموعة التدريب تتكون من صور لأشخاص في وضع الوقوف فقط ، فإن المصنف الذي نحاول بناءه قد تفشل في التنبؤ بصور البشر مستلقين ، لذلك يمكن أن تحاكي الزيادة صورة البشر مستلقين عن طريق تدوير صور التدريب بمقدار 90 درجة.

هذه طريقة رخيصة وهامة لتوسيع مجموعة البيانات وزيادة مقاييس التحقق من صحة النموذج.
تعد زيادة البيانات أداة قوية خاصةً لمشاكل التصنيف مثل التعرف على الكائنات. غالبًا ما تؤدي العمليات مثل ترجمة صور التدريب إلى بضع وحدات بكسل في كل اتجاه إلى تحسين التعميم بشكل كبير.
ميزة أخرى مفيدة للزيادة هي أن الصور يتم تحويلها على التدفق ، مما يعني أن مجموعة البيانات الحالية لا يتم تجاوزها. ستحدث الزيادة عندما يتم تحميل الصور في الشبكة العصبية للتدريب ، وبالتالي ، لن يؤدي ذلك إلى زيادة متطلبات الذاكرة والحفاظ على البيانات أيضًا لإجراء مزيد من التجارب.
يعد تطبيق تقنيات الترجمة مثل الزيادة مفيدًا للغاية حيث يكون جمع البيانات الجديدة مكلفًا ، على الرغم من أنه يجب على المرء أن يضع في الاعتبار عدم تطبيق التحول الذي قد يغير التوزيع الحالي لفئة التدريب. على سبيل المثال ، إذا تضمنت مجموعة التدريب صورًا لأرقام مكتوبة بخط اليد من 0 إلى 9 ، فإن قلب / تدوير الأرقام "6" و "9" لا يعد تحولًا مناسبًا لأن هذا سيجعل مجموعة التدريب قديمة.
اقرأ أيضًا: أهم أفكار مشاريع مجموعات بيانات التعلم الآلي
استخدام زيادة البيانات مع TensorFlow
يمكن تحقيق التعزيز باستخدام ImageDataGenerator API من Keras باستخدام TensorFlow كخلفية. يمكن لمثيل ImageDataGenerator إجراء عدد من التحويلات العشوائية على الصور عند نقطة التدريب. بعض الحجج الشائعة المتوفرة في هذه الحالة هي:
- rotation_range: قيمة عدد صحيح بالدرجات بين 0-180 لتدوير الصور عشوائيًا.
- width_shift_range: تحويل الصورة أفقيًا حول إطارها لإنشاء المزيد من الأمثلة.
- height_shift_range: تحويل الصورة عموديًا حول إطارها لإنشاء المزيد من الأمثلة.
- shear_range: تطبيق تحويلات قص عشوائية على الصورة لإنشاء أمثلة متعددة.
- zoom_range: الجزء النسبي من الصورة للتكبير عشوائياً.
- أفقي_فليب: يستخدم لقلب الصور أفقيًا.
- fill_mode: طريقة لملء وحدات البكسل المنشأة حديثًا.
يوجد أدناه مقتطف الشفرة الذي يوضح كيف يمكن استخدام مثيل ImageDataGenerator لإجراء التحويل المذكور أعلاه:

- train_datagen = ImageDataGenerator (
- إعادة التدوير = 1. / 255 ،
- rotation_range = 40 ،
- width_shift_range = 0.2 ،
- height_shift_range = 0.2 ،
- shear_range = 0.2 ،
- zoom_range = 0.2 ،
- أفقي_فليب = صحيح ،
- fill_mode = "الأقرب")
كما أنه من التافه رؤية نتيجة تطبيق هذه التحولات العشوائية على مجموعة التدريب. لهذا يمكننا عرض بعض صور التدريب المعززة بشكل عشوائي عن طريق التكرار على مجموعة التدريب:

الشكل 1: الصور التي تم إنشاؤها باستخدام التكبير
(صورة من التعلم العميق باستخدام بايثون بقلم فرانسوا شوليت ، الفصل الخامس ، الصفحة 140)
يعطينا الشكل 1 فكرة عن كيف يمكن أن ينتج عن التكبير صور متعددة من صورة إدخال واحدة مع اختلاف جميع الصور بشكل سطحي عن بعضها البعض فقط بسبب التحويلات العشوائية التي تم إجراؤها عليها في وقت التدريب.
لفهم الجوهر الحقيقي لاستخدام استراتيجيات التعزيز ، يجب أن نفهم تأثيرها على مقاييس التدريب والتحقق من صحة النموذج. لهذا ، سنقوم بتدريب نموذجين: أحدهما لن يستخدم زيادة البيانات والآخر سوف. للتحقق من ذلك ، سنستخدم مجموعة بيانات القطط والكلاب المتوفرة في:
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
منحنيات الدقة التي تمت ملاحظتها لكلا النموذجين موضحة أدناه:
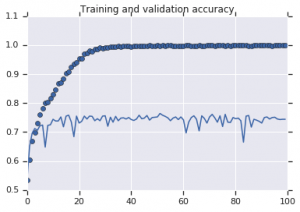
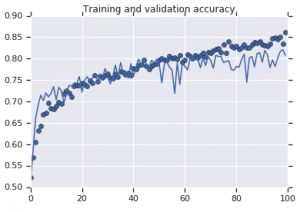
الشكل 2: دقة التدريب والتحقق من الصحة. اليسار : نموذج بدون تكبير. إلى اليمين : نموذج مع تحويلات زيادة البيانات العشوائية.
يجب أن تقرأ: أفضل مجموعات البيانات المثبتة لتحليل المشاعر
خاتمة
يتضح من الشكل 2 أن النموذج الذي تم تدريبه بدون استراتيجيات زيادة يظهر قوة تعميم منخفضة. أداء النموذج في مجموعة التحقق لا يتساوى مع أداء مجموعة التدريب. هذا يعني أن النموذج قد تم تجهيزه بشكل زائد.
من ناحية أخرى ، يُظهر النموذج الثاني الذي يستخدم استراتيجيات التعزيز مقاييس ممتازة مع دقة التحقق من الصحة التي تصل إلى دقة التدريب. يوضح هذا مدى فائدة استخدام تقنيات زيادة مجموعة البيانات حيث يُظهر النموذج علامات التجهيز الزائد.
إذا كنت مهتمًا أيضًا بالتعرف على تحليل المشاعر والتقنيات المرتبطة به ، مثل الذكاء الاصطناعي والتعلم الآلي ، فيمكنك التحقق من دورة دبلوم PG في التعلم الآلي والذكاء الاصطناعي .