
Aumento del set di dati: creazione di dati artificiali [spiegato semplicemente]
Pubblicato: 2020-12-07Sommario
introduzione
Durante la progettazione di qualsiasi algoritmo di apprendimento automatico, è sempre necessario mantenere il compromesso tra ottimizzazione e generalizzazione . Queste parole possono sembrare troppo complicate per i principianti, ma conoscere la differenza tra loro in una fase iniziale durante il loro percorso per padroneggiare l'apprendimento automatico li aiuterà sicuramente a capire il funzionamento sottostante del perché il loro modello si comporta in un modo particolare.
L'aspetto dell'ottimizzazione si riferisce all'ottimizzazione del modello in modo tale che le sue prestazioni sui dati di addestramento siano al massimo. D'altra parte, la generalizzazione riguarda le prestazioni di un modello di apprendimento su dati che non ha mai visto prima, cioè su un set di validazione.
Spesso arriva un momento in cui dopo un certo numero di epoche sui dati di addestramento, la generalizzazione del modello smette di migliorare e le metriche di validazione iniziano a degradarsi, questo è il caso in cui si dice che il modello è overfit, ovvero dove inizia ad apprendere informazioni specifiche per i dati di addestramento ma non utili per correlarli a nuovi dati.
Per affrontare il problema dell'overfitting, la soluzione migliore è raccogliere più dati di addestramento: più dati ha visto il modello, migliore è la sua probabilità di apprendere anche le rappresentazioni dei nuovi dati. Tuttavia, raccogliere più dati di addestramento può essere più costoso che risolvere il problema principale che è necessario affrontare. Per aggirare questa limitazione, possiamo creare dati falsi e aggiungerli al training set. Questo è noto come aumento dei dati.
Ampliamento dei dati in profondità
La premessa di apprendere le rappresentazioni visive dalle immagini ha aiutato a risolvere molti problemi di visione artificiale. Tuttavia, quando abbiamo un set di dati più piccolo su cui allenarci, queste rappresentazioni visive potrebbero essere fuorvianti. L'aumento dei dati è un'eccellente strategia per superare questo inconveniente.
Durante l'aumento, le immagini nel set di addestramento vengono trasformate da determinate operazioni come rotazione, ridimensionamento, taglio, ecc. Ad esempio: se il set di addestramento è costituito da immagini di esseri umani solo in posizione eretta, allora il classificatore che stiamo cercando di costruire potrebbe non riuscire a prevedere le immagini degli esseri umani sdraiati, quindi l'aumento può simulare l'immagine degli esseri umani sdraiati ruotando le immagini del set di allenamento di 90 gradi.

Questo è un modo economico e significativo per estendere il set di dati e aumentare le metriche di convalida del modello.
L'aumento dei dati è uno strumento potente soprattutto per problemi di classificazione come il riconoscimento di oggetti. Operazioni come la traduzione delle immagini di addestramento di pochi pixel in ciascuna direzione possono spesso migliorare notevolmente la generalizzazione.
Un'altra caratteristica vantaggiosa dell'aumento è che le immagini vengono trasformate nel flusso, il che significa che il set di dati esistente non viene sovrascritto. L'aumento avverrà quando le immagini vengono caricate nella rete neurale per l'addestramento e, quindi, ciò non aumenterà i requisiti di memoria e conserverà anche i dati per ulteriori sperimentazioni.
L'applicazione di tecniche traslazionali come l'aumento è molto utile laddove la raccolta di nuovi dati è dispendiosa, anche se bisogna tenere a mente di non applicare trasformazioni che potrebbero cambiare la distribuzione esistente della classe di formazione. Ad esempio, se il set di addestramento include immagini di cifre scritte a mano da 0 a 9, capovolgere/ruotare le cifre "6" e "9" non è una trasformazione appropriata poiché ciò renderebbe il set di addestramento obsoleto.
Leggi anche: Le migliori idee per progetti di set di dati di machine learning
Utilizzo dell'aumento dei dati con TensorFlow
L' aumento può essere ottenuto utilizzando l' API ImageDataGenerator di Keras utilizzando TensorFlow come back-end. L' istanza ImageDataGenerator può eseguire una serie di trasformazioni casuali sulle immagini nel punto di addestramento. Alcuni degli argomenti popolari disponibili in questo caso sono:

- intervallo_rotazione: un valore intero in gradi compreso tra 0 e 180 per ruotare le immagini in modo casuale.
- width_shift_range: sposta l'immagine orizzontalmente attorno alla cornice per generare più esempi.
- height_shift_range: sposta l'immagine verticalmente attorno alla cornice per generare più esempi.
- shear_range: applica trasformazioni di taglio casuali sull'immagine per generare più esempi.
- zoom_range: porzione relativa dell'immagine da ingrandire casualmente.
- horizontal_flip: Usato per capovolgere le immagini orizzontalmente.
- fill_mode: metodo per riempire i pixel appena creati.
Di seguito è riportato il frammento di codice che mostra come l' istanza ImageDataGenerator può essere utilizzata per eseguire la suddetta trasformazione:
- train_datagen = ImageDataGenerator(
- ridimensionamento=1./255,
- intervallo_rotazione=40,
- width_shift_range=0.2,
- height_shift_range=0.2,
- shear_range=0.2,
- zoom_range=0.2,
- horizontal_flip=Vero,
- fill_mode='più vicino')
È anche banale vedere il risultato dell'applicazione di queste trasformazioni casuali sul training set. Per questo possiamo visualizzare alcune immagini di allenamento aumentate in modo casuale iterando sul set di allenamento:

Figura 1: immagini generate utilizzando l'aumento
(Immagine da Deep Learning con Python di Francois Chollet, Capitolo 5, pagina 140)
La Figura 1 ci dà un'idea di come l'aumento può produrre più immagini da una singola immagine di input con tutte le immagini superficialmente diverse l'una dall'altra solo a causa delle trasformazioni casuali che sono state eseguite su di esse durante il training.
Per comprendere la vera essenza dell'utilizzo delle strategie di aumento, dobbiamo comprenderne l'impatto sulle metriche di addestramento e validazione del modello. Per questo, addestreremo due modelli: uno non utilizzerà l'aumento dei dati e l'altro lo farà. Per convalidarlo, utilizzeremo il set di dati Cats and Dogs disponibile all'indirizzo:
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
Di seguito sono riportate le curve di precisione osservate per entrambi i modelli:
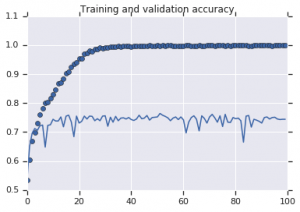
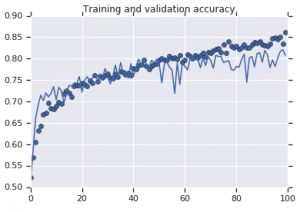
Figura 2: Accuratezza della formazione e della convalida. A sinistra : modello senza aumento. A destra : modello con trasformazioni casuali di aumento dei dati.
Da leggere: I migliori set di dati stabiliti per l'analisi del sentimento
Conclusione
È evidente dalla Figura 2 che il modello addestrato senza strategie di aumento mostra un basso potere di generalizzazione. La performance del modello sul set di validazione non è alla pari con quella del training set. Ciò significa che il modello è sovradimensionato.
D'altra parte, il secondo modello che utilizza strategie di aumento mostra metriche eccellenti con l'accuratezza della convalida che sale tanto quanto l'accuratezza dell'allenamento. Ciò dimostra quanto sia utile impiegare tecniche di potenziamento del set di dati in cui un modello mostra segni di overfitting.
Se sei ulteriormente interessato a conoscere l'analisi del sentimento e le tecnologie associate, come l'intelligenza artificiale e l'apprendimento automatico, puoi consultare il nostro corso PG Diploma in Machine Learning e AI .