
Duygu Analizinin Arkasındaki Sezgi: Sıfırdan Duygu Analizi Nasıl Yapılır?
Yayınlanan: 2020-12-07İçindekiler
Tanıtım
Metin, insan için bilgiyi algılamanın en önemli aracıdır. İnsanlar tarafından kazanılan zekanın büyük bir kısmı, etraflarındaki metinlerin ve cümlelerin anlamlarını öğrenmek ve anlamak yoluyla olur.
İnsanlar belli bir yaştan sonra herhangi bir kelimenin/metnin çıkarımını bilmeden anlamak için içsel bir refleks geliştirirler. Makineler için bu görev tamamen farklıdır. Metinlerin ve cümlelerin anlamlarını özümsemek için makineler, Doğal Dil İşleme'nin (NLP) temellerine güvenir.
Doğal dil işleme için derin öğrenme, kelimelere, cümlelere ve paragraflara uygulanan örüntü tanımadır, bilgisayarla görmenin görüntünün piksellerine uygulanan örüntü tanıma ile aynı şekilde.
Bu derin öğrenme modellerinin hiçbiri metni insani anlamda gerçekten anlamıyor; daha ziyade, bu modeller, birçok basit metinsel görevi çözmek için yeterli olan yazılı dilin istatistiksel yapısını haritalayabilir. Duygu analizi böyle bir görevdir, örneğin: dizilerin veya film incelemelerinin duyarlılığını olumlu veya olumsuz olarak sınıflandırmak.
Bunların endüstride de büyük ölçekli uygulamaları var. Örneğin: bir mal ve hizmet şirketi, ürün yaşam döngüsü üzerinde çalışmak ve satış rakamlarını iyileştirmek ve müşteri geri bildirimi toplamak için belirli bir ürün için aldığı olumlu ve olumsuz yorum sayısına ilişkin verileri toplamak ister.
ön işleme
Duyarlılık analizinin görevi, genellikle Yhat almak için bir tahmin işlevine giren X girdisine sahip olduğumuz basit bir denetimli makine öğrenimi algoritmasına Daha sonra tahminimizi gerçek Y değeriyle karşılaştırırız , Bu bize daha sonra metin işleme modelimizin parametrelerini Daha önce görülmemiş bir metin akışından duygu çıkarma görevinin üstesinden gelmek için ilk adım, ayrı olumlu ve olumsuz duygular ile etiketlenmiş bir veri kümesi toplamaktır. Bu duygular şunlar olabilir: iyi inceleme veya kötü inceleme, alaycı yorum veya alaycı olmayan yorum vb.
Bir sonraki adım, V boyutunda bir vektör oluşturmaktır ; burada Bu kelime vektörü, veri setimizde bulunan her kelimeyi (hiçbir kelime tekrarlanmaz) içerecek ve makinemiz için başvurabileceği bir sözlük görevi görecektir. Artık fazlalıkları kaldırmak için kelime vektörünü önceden işliyoruz. Aşağıdaki adımlar gerçekleştirilir:
- URL'leri ve diğer önemsiz olmayan bilgileri (bir cümlenin anlamını belirlemeye yardımcı olmayan) ortadan kaldırmak
- Dizeyi kelimelere dönüştürme: "Makine öğrenimini seviyorum" dizesine sahip olduğumuzu varsayalım, şimdi simgeleştirme yoluyla cümleyi tek tek kelimelere böldük ve [I, love, machine, learning] olarak bir listede saklıyoruz.
- “Ve”, “am”, “veya”, “ben” vb. gibi durma sözcüklerini kaldırma.
- Stemming: Her kelimeyi kök formuna dönüştürüyoruz. "Tune", "tuning" ve "tuned" gibi kelimeler anlamsal olarak aynı anlama gelir, bu nedenle onları kök formuna, yani "tun"a indirgemek kelime dağarcığını azaltacaktır.
- Tüm kelimeleri küçük harfe dönüştürme
Ön işleme adımını özetlemek için bir örneğe bakalım: diyelim ki “upGrad.com'daki yeni ürünü seviyorum” pozitif bir dizimiz var . Son ön işleme tabi tutulmuş dizi, URL'yi kaldırarak, cümleyi tek bir sözcük listesine tokenize ederek, "I, am, the, at" gibi durak sözcüklerini kaldırarak ve ardından "love" kelimelerini "lov" ve "product" ile köklendirerek elde edilir. “produ”ya çevirmek ve sonunda hepsini küçük harfe dönüştürmek , [lov, new, produ] listesiyle sonuçlanır .
Özellik çıkarma
Derlem ön işleme tabi tutulduktan sonra, sonraki adım cümleler listesinden özellikleri çıkarmak olacaktır. Diğer tüm sinir ağları gibi, derin öğrenme modelleri de girdi olarak ham metin almaz: yalnızca sayısal tensörlerle çalışırlar. Önceden işlenmiş sözcük listesinin bu nedenle sayısal değerlere dönüştürülmesi gerekir. Bu, aşağıdaki şekilde yapılabilir. Aşağıdaki gibi pozitif ve negatif dizelere sahip bir dize derlemesi verildiğini varsayalım (bunu veri kümesi olarak varsayın) :
| pozitif dizeler | Negatif dizeler |
|
|
Şimdi bu dizgilerin her birini 3 boyutlu sayısal bir vektöre dönüştürmek için, kelimeyi ve içinde göründüğü sınıfı (pozitif veya negatif) o kelimenin karşılık gelen sınıfında görünme sayısıyla eşlemek için bir sözlük oluşturuyoruz.
| Kelime bilgisi | pozitif frekans | Negatif frekans |
| i | 3 | 3 |
| ben | 3 | 3 |
| mutlu | 2 | 0 |
| Çünkü | 1 | 0 |
| öğrenme | 1 | 1 |
| NLP | 1 | 1 |
| üzgün | 0 | 2 |
| olumsuzluk | 0 | 1 |
Söz konusu sözlüğü oluşturduktan sonra, dizelerin her birine ayrı ayrı bakarız ve daha sonra dizede görünmeyen kelimeleri bırakarak dizede görünen kelimelerin pozitif ve negatif frekans sayılarını toplarız. 'Üzgünüm, NLP öğrenmiyorum' dizesini alalım ve 3. boyutun vektörünü oluşturalım.

“Üzgünüm, NLP öğrenmiyorum”
| Kelime bilgisi | pozitif frekans | Negatif frekans |
| i | 3 | 3 |
| ben | 3 | 3 |
| mutlu | 2 | 0 |
| Çünkü | 1 | 0 |
| öğrenme | 1 | 1 |
| NLP | 1 | 1 |
| üzgün | 0 | 2 |
| olumsuzluk | 0 | 1 |
| Toplam = 8 | Toplam = 11 |
“Üzgünüm, NLP öğrenmiyorum” dizesi için kelime dağarcığında sadece “mutlu, çünkü” kelimelerinin bulunmadığını görüyoruz, şimdi özellikleri çıkarmak ve söz konusu vektörü oluşturmak için pozitif ve negatif frekansı toplarız. sütunlar ayrı ayrı dizede olmayan kelimelerin sıklık numarasını dışarıda bırakır, bu durumda “mutlu, çünkü” bırakırız. Toplamı pozitif frekans için 8 ve negatif frekans için 9 olarak elde ederiz.
Bu nedenle, "Üzgünüm, NLP öğrenmiyorum" dizesi, İndeks 0'da bulunan “1” sayısı, gelecek tüm diziler için “1” olarak kalacak olan sapma birimidir ve “8”, “11” sayıları sırasıyla pozitif ve negatif frekansların toplamını temsil eder.
Benzer bir şekilde, veri kümesindeki tüm diziler rahatlıkla 3 boyutlu bir vektöre dönüştürülebilir.
Devamını oku: Python Kullanarak Duygu Analizi: Uygulamalı Bir Kılavuz
Lojistik Regresyon Uygulaması
Özellik çıkarma, cümlenin özünü anlamayı kolaylaştırır, ancak makinelerin görünmeyen bir dizeyi pozitif veya negatif olarak işaretlemek için hala daha net bir yola ihtiyacı vardır. Burada, vektörleştirilmiş her dizi için 0 ile 1 arasında bir olasılık veren sigmoid fonksiyonunu kullanan lojistik regresyon devreye girer.

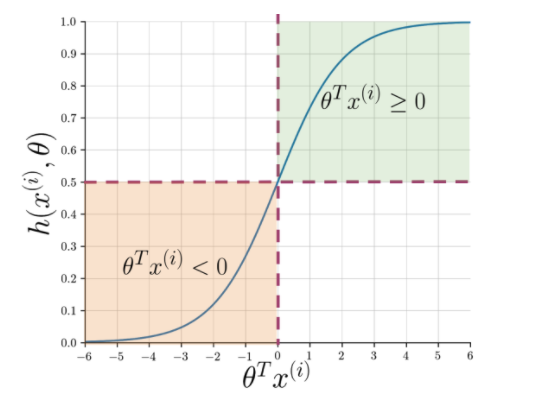
Şekil 1: Sigmoid fonksiyonunun grafik gösterimi
Şekil 1, teta ve Ayrıca Okuyun: En İyi 4 Veri Analitiği Proje Fikri: Başlangıç Düzeyinde Uzman Düzeyinde
Sıradaki ne?
Duygu Analizi, makine öğreniminde önemli bir konudur. Birden fazla alanda çok sayıda uygulamaya sahiptir. Bu konu hakkında daha fazla bilgi edinmek istiyorsanız, blogumuza gidebilir ve birçok yeni kaynak bulabilirsiniz.
Öte yandan, kapsamlı ve yapılandırılmış bir öğrenme deneyimi elde etmek istiyorsanız ve makine öğrenimi hakkında daha fazla bilgi edinmek istiyorsanız, çalışan profesyoneller için tasarlanmış IIIT-B & upGrad'ın Makine Öğrenimi ve Yapay Zeka PG Diplomasına göz atın. ve 450+ saat sıkı eğitim, 30'dan fazla vaka çalışması ve ödev, IIIT-B Mezunu statüsü, 5'ten fazla pratik uygulamalı bitirme projesi ve en iyi firmalarla iş yardımı sunar.
S1. Rastgele Orman Algoritması neden makine öğrenimi için en iyisidir?
Random Forest algoritması, farklı makine öğrenme modelleri geliştirmede yaygın olarak kullanılan denetimli öğrenme algoritmaları kategorisine aittir. Rastgele orman algoritması hem sınıflandırma hem de regresyon modelleri için uygulanabilir. Bu algoritmayı makine öğrenimi için en uygun kılan şey, makine öğrenimi çoğunlukla veri alt kümeleriyle ilgilendiğinden, yüksek boyutlu bilgilerle mükemmel bir şekilde çalışması gerçeğidir. İlginç bir şekilde, rastgele orman algoritması, karar ağaçları algoritmasından türetilmiştir. Ancak, yalnızca belirli özellikleri kullandığından, bu algoritmayı kullanarak karar ağaçlarını kullanmaktan çok daha kısa sürede eğitebilirsiniz. Makine öğrenmesi modellerinde daha fazla verim sağladığı için daha çok tercih edilmektedir.
S2. Makine öğreniminin derin öğrenmeden farkı nedir?
Hem derin öğrenme hem de makine öğrenimi, yapay zeka dediğimiz tüm şemsiyenin alt alanlarıdır. Ancak, bu iki alt alan kendi farklılıkları ile birlikte gelir. Derin öğrenme, aslında makine öğreniminin bir alt kümesidir. Ancak, derin öğrenmeyi kullanarak makineler videoları, görüntüleri ve yalnızca makine öğrenimi kullanarak elde edilmesi zor olabilecek diğer yapılandırılmamış veri biçimlerini analiz edebilir. Makine öğrenimi, bilgisayarların minimum insan müdahalesi ile kendi kendilerine düşünmelerini ve hareket etmelerini sağlamakla ilgilidir. Buna karşılık, derin öğrenme, makinelerin insan beynine benzeyen yapılara dayalı olarak düşünmesine yardımcı olmak için kullanılır.
S3. Veri bilimcileri neden rastgele orman algoritmasını tercih ediyor?
Rastgele orman algoritmasını kullanmanın birçok faydası vardır ve bu da onu veri bilimcileri arasında tercih edilen seçim haline getirir. İlk olarak, lojistik ve doğrusal regresyon gibi diğer doğrusal algoritmalarla karşılaştırıldığında oldukça doğru sonuçlar sağlar. Bu algoritmayı açıklamak zor olsa da, altta yatan karar ağaçlarına dayalı olarak sonuçları incelemek ve yorumlamak daha kolaydır. Yeni örnekler ve özellikler eklendiğinde bile bu algoritmayı aynı kolaylıkla kullanabilirsiniz. Bazı veriler eksik olduğunda bile kullanımı kolaydır.