
สัญชาตญาณเบื้องหลังการวิเคราะห์ความรู้สึก: วิธีการทำการวิเคราะห์ความรู้สึกตั้งแต่เริ่มต้น?
เผยแพร่แล้ว: 2020-12-07สารบัญ
บทนำ
ข้อความเป็นวิธีที่สำคัญที่สุดในการรับรู้ข้อมูลของมนุษย์ สติปัญญาส่วนใหญ่ที่มนุษย์ได้รับมาจากการเรียนรู้และทำความเข้าใจความหมายของข้อความและประโยคที่อยู่รอบตัวพวกเขา
หลังจากผ่านไประยะหนึ่ง มนุษย์จะพัฒนาปฏิกิริยาตอบสนองภายในเพื่อทำความเข้าใจการอนุมานของคำ/ข้อความใดๆ โดยที่ไม่รู้ด้วยซ้ำ สำหรับเครื่องจักร งานนี้แตกต่างอย่างสิ้นเชิง เพื่อซึมซับความหมายของข้อความและประโยค เครื่องจักรต้องอาศัยพื้นฐานของการประมวลผลภาษาธรรมชาติ (NLP)
การเรียนรู้เชิงลึกสำหรับการประมวลผลภาษาธรรมชาติคือการรู้จำรูปแบบที่ใช้กับคำ ประโยค และย่อหน้า ในลักษณะเดียวกับที่คอมพิวเตอร์วิทัศน์คือการรู้จำรูปแบบที่ใช้กับพิกเซลของภาพ
ไม่มีโมเดลการเรียนรู้เชิงลึกเหล่านี้ที่เข้าใจข้อความในความรู้สึกของมนุษย์อย่างแท้จริง แต่โมเดลเหล่านี้สามารถแมปโครงสร้างทางสถิติของภาษาเขียนได้ ซึ่งก็เพียงพอแล้วที่จะแก้ไขงานที่เป็นข้อความง่ายๆ จำนวนมาก การวิเคราะห์ความคิดเห็นเป็นงานหนึ่ง เช่น การจำแนกความรู้สึกของสตริงหรือบทวิจารณ์ภาพยนตร์เป็นบวกหรือลบ
สิ่งเหล่านี้มีการใช้งานขนาดใหญ่ในอุตสาหกรรมเช่นกัน ตัวอย่างเช่น บริษัทสินค้าและบริการต้องการรวบรวมข้อมูลของจำนวนรีวิวเชิงบวกและเชิงลบที่ได้รับสำหรับผลิตภัณฑ์หนึ่งๆ เพื่อทำงานตามวงจรชีวิตของผลิตภัณฑ์ ปรับปรุงตัวเลขการขาย และรวบรวมคำติชมของลูกค้า
การประมวลผลล่วงหน้า
งานของการวิเคราะห์ความรู้สึกสามารถแบ่งออกเป็น อัลกอริธึมการเรียนรู้ด้วยเครื่องอย่างง่ายซึ่งเรามักจะมีอินพุต X ซึ่ง เข้าสู่ฟังก์ชันตัวทำนายเพื่อ รับ จากนั้นเราเปรียบเทียบการคาดคะเนของเรากับค่าจริง Y ซึ่ง จะทำให้เรามีต้นทุนที่เราจะใช้เพื่ออัปเดตพารามิเตอร์ เพื่อจัดการกับงานการแยกความรู้สึกออกจากกระแสข้อความที่มองไม่เห็นก่อนหน้านี้ ขั้นตอนพื้นฐานคือการรวบรวมชุดข้อมูลที่ติดป้ายกำกับด้วยความรู้สึกเชิงบวกและเชิงลบแยกจากกัน ความรู้สึกเหล่านี้อาจเป็นได้: บทวิจารณ์ที่ดีหรือบทวิจารณ์ที่ไม่ดี คำพูดประชดประชันหรือคำพูดที่ไม่ประชดประชัน ฯลฯ
ขั้นตอนต่อไปคือการสร้างเวกเตอร์ของมิติ V โดยที่ เวกเตอร์คำศัพท์นี้จะประกอบด้วยทุกคำ (ไม่มีการซ้ำคำ) ที่มีอยู่ในชุดข้อมูลของเรา และจะทำหน้าที่เป็นพจนานุกรมสำหรับเครื่องของเราซึ่งสามารถอ้างถึงได้ ตอนนี้เราประมวลผลเวกเตอร์คำศัพท์ล่วงหน้าเพื่อลบความซ้ำซ้อน มีการดำเนินการตามขั้นตอนต่อไปนี้:
- การกำจัด URL และข้อมูลที่ไม่น่าสนใจอื่นๆ (ซึ่งไม่ได้ช่วยกำหนดความหมายของประโยค)
- การแปลงสตริงเป็นคำ: สมมติว่าเรามีสตริง "ฉันรักการเรียนรู้ของเครื่อง" ตอนนี้โดยการทำให้เป็นโทเค็นเราเพียงแค่แบ่งประโยคเป็นคำเดียวและเก็บไว้ในรายการเป็น [ฉัน, ความรัก, เครื่องจักร, การเรียนรู้]
- การลบคำหยุด เช่น “และ”, “กำลัง”, “หรือ”, “ฉัน” เป็นต้น
- ต้นกำเนิด: เราแปลงแต่ละคำให้เป็นรูปแบบต้นกำเนิด คำว่า "tune", "tuning" และ "tuned" มีความหมายเหมือนกัน ดังนั้นการลดคำเหล่านั้นให้อยู่ในรูปแบบต้นกำเนิดของคำว่า "tun" จะทำให้ขนาดคำศัพท์ลดลง
- การแปลงคำทั้งหมดเป็นตัวพิมพ์เล็ก
เพื่อสรุปขั้นตอนก่อนการประมวลผล มาดูตัวอย่างกัน: สมมติว่าเรามีสตริงเชิงบวก “ฉันรักผลิตภัณฑ์ใหม่ที่ upGrad.com ” สตริงที่ประมวลผลล่วงหน้าขั้นสุดท้ายได้มาจากการนำ URL ออก แปลงประโยคให้เป็นรายการคำเดียว ลบคำหยุดเช่น "I, am, the, at" จากนั้นจึงตัดคำว่า "loving" เป็น "lov" และ "product" เป็น "produ" และสุดท้ายแปลงทั้งหมดเป็นตัวพิมพ์เล็กซึ่งส่งผลให้รายการ [lov, new, produ ]
การแยกคุณลักษณะ
หลังจากประมวลผลคลังข้อมูลแล้ว ขั้นตอนต่อไปคือการดึงคุณลักษณะออกจากรายการประโยค เช่นเดียวกับโครงข่ายประสาทเทียมอื่นๆ โมเดลการเรียนรู้เชิงลึกไม่ได้ใช้เป็นข้อความดิบที่ป้อนเข้า แต่จะใช้งานได้เฉพาะกับเมตริกซ์ที่เป็นตัวเลขเท่านั้น รายการคำที่ประมวลผลล่วงหน้าจึงจำเป็นต้องแปลงเป็นค่าตัวเลข สามารถทำได้ด้วยวิธีต่อไปนี้ สมมติว่ามีการรวบรวมสตริงที่มีสตริงบวกและลบ เช่น (สมมติว่าเป็นชุดข้อมูล) :
| สตริงบวก | สตริงเชิงลบ |
|
|
ในการแปลงสตริงเหล่านี้เป็นเวกเตอร์ตัวเลขของมิติ 3 เราจึงสร้างพจนานุกรมเพื่อจับคู่คำนั้น และคลาสที่ปรากฏใน (บวกหรือลบ) เป็นจำนวนครั้งที่คำนั้นปรากฏในคลาสที่สอดคล้องกัน
| คำศัพท์ | ความถี่บวก | ความถี่เชิงลบ |
| ฉัน | 3 | 3 |
| เช้า | 3 | 3 |
| มีความสุข | 2 | 0 |
| เพราะ | 1 | 0 |
| การเรียนรู้ | 1 | 1 |
| NLP | 1 | 1 |
| เศร้า | 0 | 2 |
| ไม่ | 0 | 1 |
หลังจากสร้างพจนานุกรมดังกล่าวแล้ว เราจะดูแต่ละสตริงแยกกัน จากนั้นจึงรวมตัวเลขความถี่บวกและลบของคำที่ปรากฏในสตริงโดยปล่อยให้คำที่ไม่ปรากฏในสตริง ลองใช้สตริง "ฉันเสียใจ ฉันไม่ได้เรียนรู้ NLP" และสร้างเวกเตอร์ของมิติที่ 3

“ฉันเสียใจ ฉันไม่ได้เรียน NLP”
| คำศัพท์ | ความถี่บวก | ความถี่เชิงลบ |
| ฉัน | 3 | 3 |
| เช้า | 3 | 3 |
| มีความสุข | 2 | 0 |
| เพราะ | 1 | 0 |
| การเรียนรู้ | 1 | 1 |
| NLP | 1 | 1 |
| เศร้า | 0 | 2 |
| ไม่ | 0 | 1 |
| ผลรวม = 8 | ผลรวม = 11 |
เราเห็นว่าสำหรับสตริง "ฉันเศร้าฉันไม่ได้เรียนรู้ NLP" เพียงสองคำ "มีความสุขเพราะ" ไม่มีอยู่ในคำศัพท์ตอนนี้เพื่อแยกคุณสมบัติและสร้างเวกเตอร์ดังกล่าวเรารวมความถี่บวกและลบ คอลัมน์แยกกันโดยทิ้งจำนวนความถี่ของคำที่ไม่มีอยู่ในสตริง ในกรณีนี้เราจะปล่อยให้ "มีความสุขเพราะ" เราได้รับผลรวมเป็น 8 สำหรับความถี่บวกและ 9 สำหรับความถี่เชิงลบ
ดังนั้นสตริง “ฉันเสียใจ ฉันไม่ได้เรียนรู้ NLP” สามารถแสดงเป็นเวกเตอร์ หมายเลข “1” ที่มีอยู่ในดัชนี 0 คือหน่วยอคติที่จะยังคงเป็น “1” สำหรับสตริงที่ออกมาทั้งหมด และตัวเลข “8”, “11” แทนผลรวมของความถี่บวกและลบตามลำดับ
ในทำนองเดียวกัน สตริงทั้งหมดในชุดข้อมูลสามารถแปลงเป็นเวกเตอร์ขนาด 3 ได้อย่างสะดวกสบาย
อ่านเพิ่มเติม: การวิเคราะห์ความรู้สึกโดยใช้ Python: A Hands-on Guide
การใช้การถดถอยโลจิสติก
การแยกคุณลักษณะทำให้ง่ายต่อการเข้าใจแก่นแท้ของประโยค แต่เครื่องยังคงต้องการวิธีที่คมชัดกว่านี้เพื่อตั้งค่าสถานะสตริงที่มองไม่เห็นเป็นค่าบวกหรือค่าลบ นี่คือการถดถอยโลจิสติกที่ใช้ฟังก์ชัน sigmoid ซึ่งแสดงความน่าจะเป็นระหว่าง 0 ถึง 1 สำหรับแต่ละสตริงเวกเตอร์

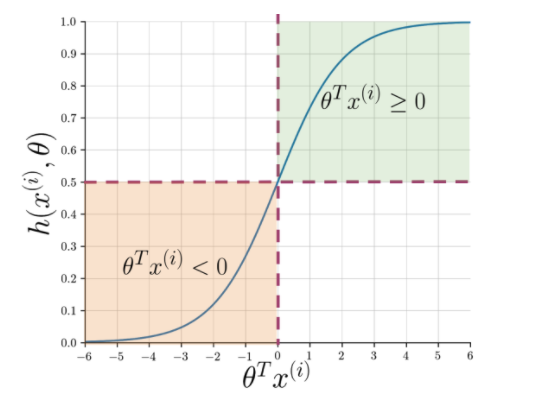
รูปที่ 1: สัญกรณ์กราฟิกของฟังก์ชัน sigmoid
รูปที่ 1 แสดงให้เห็นว่าเมื่อใดก็ตามที่ dot product ของ theta และ อ่านเพิ่มเติม: แนวคิดโครงการวิเคราะห์ข้อมูล 4 อันดับแรก: ระดับเริ่มต้นถึงระดับผู้เชี่ยวชาญ
อะไรต่อไป?
การวิเคราะห์ความรู้สึกเป็นหัวข้อสำคัญในการเรียนรู้ของเครื่อง มีแอพพลิเคชั่นมากมายในหลายสาขา หากคุณต้องการเรียนรู้เพิ่มเติมเกี่ยวกับหัวข้อนี้ คุณสามารถไปที่บล็อกของเราและค้นหาแหล่งข้อมูลใหม่ๆ มากมาย
ในทางกลับกัน หากคุณต้องการได้รับประสบการณ์การเรียนรู้ที่ครอบคลุมและมีโครงสร้าง หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's PG Diploma in Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงาน และเสนอการฝึกอบรมที่เข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายงานมากกว่า 30 รายการ สถานะศิษย์เก่า IIIT-B โครงการหลัก 5 โครงการและความช่วยเหลือด้านงานกับบริษัทชั้นนำ
ไตรมาสที่ 1 เหตุใด Random Forest Algorithm จึงดีที่สุดสำหรับการเรียนรู้ของเครื่อง
อัลกอริธึม Random Forest อยู่ในหมวดหมู่ของอัลกอริธึมการเรียนรู้ภายใต้การดูแล ซึ่งใช้กันอย่างแพร่หลายในการพัฒนาโมเดลการเรียนรู้ของเครื่องต่างๆ อัลกอริธึมฟอเรสต์สุ่มสามารถใช้ได้กับทั้งแบบจำลองการจำแนกประเภทและการถดถอย สิ่งที่ทำให้อัลกอริธึมนี้เหมาะสมที่สุดสำหรับการเรียนรู้ของเครื่องคือความจริงที่ว่ามันทำงานได้อย่างยอดเยี่ยมกับข้อมูลที่มีมิติสูง เนื่องจากการเรียนรู้ของเครื่องส่วนใหญ่เกี่ยวข้องกับชุดย่อยของข้อมูล ที่น่าสนใจคือ อัลกอริธึมฟอเรสต์แบบสุ่มได้มาจากอัลกอริธึมทรีการตัดสินใจ แต่คุณสามารถฝึกโดยใช้อัลกอริธึมนี้ได้ในช่วงเวลาที่สั้นกว่าการใช้แผนผังการตัดสินใจ เนื่องจากมันใช้เฉพาะคุณสมบัติเฉพาะเท่านั้น มีประสิทธิภาพมากขึ้นในโมเดลการเรียนรู้ของเครื่อง ดังนั้นจึงเป็นที่ต้องการมากกว่า
ไตรมาสที่ 2 แมชชีนเลิร์นนิงต่างจากการเรียนรู้เชิงลึกอย่างไร
ทั้งการเรียนรู้เชิงลึกและการเรียนรู้ของเครื่องเป็นสาขาย่อยของทั้งระบบที่เราเรียกว่าปัญญาประดิษฐ์ อย่างไรก็ตาม ฟิลด์ย่อยทั้งสองนี้มีความแตกต่างกัน การเรียนรู้เชิงลึกเป็นส่วนย่อยของการเรียนรู้ของเครื่อง อย่างไรก็ตาม เมื่อใช้การเรียนรู้เชิงลึก เครื่องจักรสามารถวิเคราะห์วิดีโอ รูปภาพ และข้อมูลที่ไม่มีโครงสร้างรูปแบบอื่นๆ ได้ ซึ่งอาจเป็นเรื่องยากที่จะทำได้โดยใช้เพียงแค่แมชชีนเลิร์นนิง แมชชีนเลิร์นนิงเป็นเรื่องเกี่ยวกับการทำให้คอมพิวเตอร์คิดและดำเนินการด้วยตนเอง โดยมีการแทรกแซงของมนุษย์น้อยที่สุด ในทางตรงกันข้าม การเรียนรู้เชิงลึกนั้นใช้เพื่อช่วยให้เครื่องคิดตามโครงสร้างที่คล้ายกับสมองของมนุษย์
ไตรมาสที่ 3 เหตุใดนักวิทยาศาสตร์ข้อมูลจึงชอบอัลกอริธึมฟอเรสต์แบบสุ่ม
มีประโยชน์มากมายของการใช้อัลกอริธึมฟอเรสต์แบบสุ่ม ซึ่งทำให้เป็นทางเลือกที่นิยมในหมู่นักวิทยาศาสตร์ด้านข้อมูล ประการแรก มันให้ผลลัพธ์ที่แม่นยำสูงเมื่อเปรียบเทียบกับอัลกอริธึมเชิงเส้นอื่นๆ เช่น การถดถอยโลจิสติกและการถดถอยเชิงเส้น แม้ว่าอัลกอริธึมนี้สามารถอธิบายได้ยาก แต่การตรวจสอบและตีความผลลัพธ์นั้นง่ายกว่าโดยพิจารณาจากแผนผังการตัดสินใจพื้นฐาน คุณสามารถใช้อัลกอริธึมนี้ได้อย่างง่ายดายเท่าเทียมกัน แม้ว่าจะมีการเพิ่มตัวอย่างและคุณสมบัติใหม่เข้าไป ใช้งานง่ายแม้ข้อมูลบางส่วนจะขาดหายไป