
6 ประเภทของฟังก์ชั่นการเปิดใช้งานในโครงข่ายประสาทเทียมที่คุณต้องรู้
เผยแพร่แล้ว: 2020-02-13ด้วย Deep Learning ที่กลายเป็นเทคโนโลยีกระแสหลัก จึงมีการพูดคุยกันมากมายเกี่ยวกับ ANNs หรือ Artificial Neural Networks วันนี้ ANN เป็นองค์ประกอบหลักในโดเมนที่เกิดใหม่ที่หลากหลาย เช่น การรู้จำลายมือ การบีบอัดภาพ การทำนายตลาดหุ้น และอื่นๆ อีกมากมาย อ่านเพิ่มเติมเกี่ยวกับประเภทของโครงข่ายประสาทเทียมในการเรียนรู้ของเครื่อง
แต่โครงข่ายประสาทเทียมคืออะไร?
โครงข่ายประสาทเทียมเป็นแบบจำลองการเรียนรู้เชิงลึกที่ดึงแรงบันดาลใจจากโครงสร้างประสาทของสมองมนุษย์ ANN ได้รับการออกแบบเพื่อเลียนแบบการทำงานของสมองมนุษย์ที่เรียนรู้จากประสบการณ์และปรับให้เข้ากับสถานการณ์ เช่นเดียวกับสมองของมนุษย์ที่มีโครงสร้างหลายชั้นที่ประกอบด้วยเซลล์ประสาทหลายพันล้านเซลล์ที่จัดอยู่ในลำดับชั้น ANN ยังมีเครือข่ายของเซลล์ประสาทที่เชื่อมต่อถึงกันผ่านแอกซอน
เซลล์ประสาทที่เชื่อมต่อถึงกันเหล่านี้ส่งสัญญาณไฟฟ้า (เรียกว่า ไซแนปส์) จากชั้นหนึ่งไปยังอีกชั้นหนึ่ง การเลียนแบบการสร้างแบบจำลองสมองนี้ทำให้ ANN สามารถเรียนรู้จากประสบการณ์โดยไม่ต้องอาศัยการแทรกแซงของมนุษย์
อ่าน: โครงข่ายประสาทเทียมในการขุดข้อมูล
ดังนั้น ANNs จึงเป็นโครงสร้างที่ซับซ้อนซึ่งมีองค์ประกอบแบบปรับตัวที่เชื่อมต่อถึงกัน ซึ่งเรียกว่าเซลล์ประสาทเทียมที่สามารถทำการคำนวณจำนวนมากเพื่อเป็นตัวแทนความรู้ พวกมันมีคุณสมบัติพื้นฐานทั้งหมดของระบบเซลล์ประสาททางชีวภาพ รวมถึงความสามารถในการเรียนรู้ ความทนทาน ไม่เชิงเส้น ความขนานสูง ความทนทานต่อข้อผิดพลาดและความล้มเหลว ความสามารถในการจัดการกับข้อมูลที่ไม่ชัดเจนและคลุมเครือ และความสามารถทั่วไป

เข้าร่วม หลักสูตรปัญญาประดิษฐ์ ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก – ปริญญาโท หลักสูตร Executive Post Graduate และหลักสูตรประกาศนียบัตรขั้นสูงใน ML & AI เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
สารบัญ
ลักษณะสำคัญของโครงข่ายประสาทเทียม
- การไม่เชิงเส้นช่วยให้เหมาะสมกับข้อมูลมากขึ้น
- ความขนานสูงส่งเสริมการประมวลผลที่รวดเร็วและความทนทานต่อความล้มเหลวของฮาร์ดแวร์
- การวางนัยทั่วไปช่วยให้สามารถประยุกต์ใช้แบบจำลองกับข้อมูลที่ยังไม่ได้เรียนรู้
- ไม่ไวต่อสัญญาณรบกวนที่ช่วยให้คาดการณ์ได้อย่างแม่นยำแม้ข้อมูลที่ไม่แน่นอนและข้อผิดพลาดในการวัด
- การเรียนรู้และการปรับตัวช่วยให้โมเดลอัปเดตสถาปัตยกรรมภายในตามสภาพแวดล้อมที่เปลี่ยนแปลงไป
การคำนวณโดยใช้ ANN มีวัตถุประสงค์หลักเพื่อออกแบบอัลกอริธึมทางคณิตศาสตร์ขั้นสูงที่ช่วยให้เครือข่ายประสาทเทียมเรียนรู้โดยการเลียนแบบการประมวลผลข้อมูลและฟังก์ชันการได้มาซึ่งความรู้ของสมองมนุษย์
ส่วนประกอบของโครงข่ายประสาทเทียม
ANN ประกอบด้วยเลเยอร์หลักหรือเฟสสามชั้น – เลเยอร์อินพุต เลเยอร์/วินาทีที่ซ่อนอยู่ และเลเยอร์เอาต์พุต
- เลเยอร์อินพุต: เลเยอร์ แรกถูกป้อนด้วยอินพุต นั่นคือ ข้อมูลดิบ มันถ่ายทอดข้อมูลจากโลกภายนอกไปยังเครือข่าย ในเลเยอร์นี้ จะไม่มีการคำนวณใดๆ – โหนดต่างๆ จะส่งข้อมูลไปยังเลเยอร์ที่ซ่อนอยู่เท่านั้น
- เลเยอร์ที่ซ่อนอยู่: ในเลเยอร์นี้ โหนดต่างๆ จะซ่อนอยู่หลังเลเยอร์อินพุต ซึ่งประกอบไปด้วยส่วนที่เป็นนามธรรมในทุกโครงข่ายประสาทเทียม การคำนวณทั้งหมดเกี่ยวกับคุณสมบัติที่ป้อนผ่านเลเยอร์อินพุตเกิดขึ้นในเลเยอร์ที่ซ่อนอยู่ จากนั้นจะถ่ายโอนผลลัพธ์ไปยังเลเยอร์เอาต์พุต
- เลเยอร์เอาต์พุต: เลเยอร์ นี้แสดงผลลัพธ์ของการคำนวณที่ดำเนินการโดยเครือข่ายไปยังโลกภายนอก
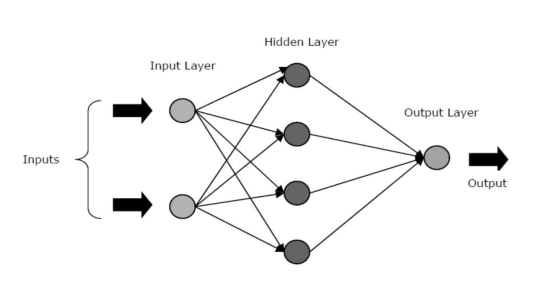
แหล่งที่มา
โครงข่ายประสาทเทียมสามารถจำแนกได้หลายประเภทตามกิจกรรมของเลเยอร์ที่ซ่อนอยู่ ตัวอย่างเช่น ในโครงข่ายประสาทเทียมแบบธรรมดา หน่วยที่ซ่อนอยู่สามารถสร้างการแทนค่าเฉพาะของอินพุตได้ ในที่นี้ น้ำหนักระหว่างหน่วยที่ซ่อนอยู่และหน่วยอินพุตจะกำหนดเมื่อแต่ละหน่วยที่ซ่อนอยู่ทำงาน
ดังนั้น โดยการปรับน้ำหนักเหล่านี้ เลเยอร์ที่ซ่อนอยู่สามารถเลือกสิ่งที่ควรแสดง สถาปัตยกรรมอื่นๆ ได้แก่ โมเดลชั้นเดียวและหลายชั้น ในเลเยอร์เดียว โดยปกติแล้วจะมีเพียงเลเยอร์อินพุตและเอาต์พุต แต่ไม่มีเลเยอร์ที่ซ่อนอยู่ ในขณะที่ในแบบจำลองหลายชั้น มีหนึ่งหรือมากกว่าหนึ่งเลเยอร์ที่ซ่อนอยู่
ฟังก์ชั่นการเปิดใช้งานในโครงข่ายประสาทเทียมคืออะไร?
ดังที่เราได้กล่าวไว้ก่อนหน้านี้ ANN เป็นองค์ประกอบที่สำคัญของโครงสร้างหลายอย่างที่ช่วยปฏิวัติโลกรอบตัวเรา แต่คุณเคยสงสัยหรือไม่ว่า ANN นำเสนอประสิทธิภาพที่ล้ำสมัยเพื่อค้นหาวิธีแก้ไขปัญหาในโลกแห่งความเป็นจริงได้อย่างไร
คำตอบคือ – ฟังก์ชั่นการเปิดใช้งาน
ANN ใช้ฟังก์ชันการเปิดใช้งาน (AF) เพื่อทำการคำนวณที่ซับซ้อนในเลเยอร์ที่ซ่อนอยู่ จากนั้นจึงโอนผลลัพธ์ไปยังเลเยอร์เอาต์พุต วัตถุประสงค์หลักของ AF คือการแนะนำคุณสมบัติที่ไม่เป็นเชิงเส้นในโครงข่ายประสาทเทียม
พวกเขาแปลงสัญญาณอินพุตเชิงเส้นของโหนดเป็นสัญญาณเอาต์พุตที่ไม่ใช่เชิงเส้นเพื่ออำนวยความสะดวกในการเรียนรู้พหุนามลำดับสูงที่เกินระดับหนึ่งสำหรับเครือข่ายลึก ลักษณะเฉพาะของ AFs ก็คือพวกมันสามารถสร้างความแตกต่างได้ ซึ่งช่วยให้พวกมันทำงานระหว่างการแพร่กระจายกลับของโครงข่ายประสาทเทียม
ความต้องการความไม่เชิงเส้นคืออะไร?
หากไม่ใช้ฟังก์ชันการเปิดใช้งาน สัญญาณเอาท์พุตจะเป็นฟังก์ชันเชิงเส้น ซึ่งเป็นพหุนามหนึ่งดีกรี แม้ว่าจะแก้สมการเชิงเส้นได้ง่าย แต่ก็มีผลหารความซับซ้อนที่จำกัด ดังนั้นจึงมีพลังน้อยกว่าในการเรียนรู้การแมปฟังก์ชันที่ซับซ้อนจากข้อมูล ดังนั้น ถ้าไม่มี AFs โครงข่ายประสาทเทียมจะเป็นตัวแบบการถดถอยเชิงเส้นที่มีความสามารถจำกัด
นี่ไม่ใช่สิ่งที่เราต้องการจากโครงข่ายประสาทอย่างแน่นอน งานของโครงข่ายประสาทเทียมคือการคำนวณการคำนวณที่ซับซ้อนมาก นอกจากนี้ หากไม่มี AF โครงข่ายประสาทเทียมจะไม่สามารถเรียนรู้และสร้างแบบจำลองข้อมูลที่ซับซ้อนอื่นๆ รวมถึงรูปภาพ คำพูด วิดีโอ เสียง ฯลฯ
AF ช่วยให้โครงข่ายประสาทเทียมเข้าใจถึงชุดข้อมูลขนาดใหญ่ที่มีมิติสูงและไม่เป็นเชิงเส้นซึ่งมีสถาปัตยกรรมที่ซับซ้อน โดยประกอบด้วยเลเยอร์ที่ซ่อนอยู่หลายชั้นระหว่างชั้นอินพุตและเอาต์พุต
อ่าน: Deep Learning Vs Neural Network
เพื่อไม่ให้เป็นการเสียเวลา เรามาเจาะลึกเกี่ยวกับฟังก์ชันการเปิดใช้งานประเภทต่างๆ ที่ใช้ใน ANN กัน
ประเภทของฟังก์ชั่นการเปิดใช้งาน
1. ฟังก์ชันซิกมอยด์
ใน ANN ฟังก์ชัน sigmoid คือ AF แบบไม่เป็นเชิงเส้นซึ่งใช้เป็นหลักในโครงข่ายประสาทแบบ feedforward เป็นฟังก์ชันจริงที่หาอนุพันธ์ได้ ซึ่งกำหนดไว้สำหรับค่าอินพุตจริง และประกอบด้วยอนุพันธ์เชิงบวกทุกที่ที่มีระดับความเรียบเฉพาะเจาะจง ฟังก์ชัน sigmoid ปรากฏในเลเยอร์เอาต์พุตของโมเดลการเรียนรู้เชิงลึก และใช้สำหรับทำนายผลลัพธ์ตามความน่าจะเป็น ฟังก์ชัน sigmoid แสดงเป็น:
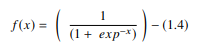
แหล่งที่มา
โดยทั่วไป อนุพันธ์ของฟังก์ชัน sigmoid จะถูกนำไปใช้กับอัลกอริทึมการเรียนรู้ กราฟของฟังก์ชันซิกมอยด์เป็นรูปตัว 'S'
ข้อเสียหลักๆ บางประการของฟังก์ชัน sigmoid ได้แก่ ความอิ่มตัวของการไล่ระดับสี การบรรจบกันที่ช้า การไล่ระดับความชื้นที่คมชัดระหว่างการขยายกลับจากภายในเลเยอร์ที่ซ่อนอยู่ลึกไปจนถึงเลเยอร์อินพุต และเอาต์พุตที่ไม่มีศูนย์ซึ่งทำให้การอัปเดตการไล่ระดับสีแพร่กระจายไปในทิศทางที่แตกต่างกัน

2. ฟังก์ชันไฮเปอร์โบลิกแทนเจนต์ (Tanh)
ฟังก์ชันไฮเปอร์โบลิกแทนเจนต์ หรือที่เรียกว่าฟังก์ชัน tanh เป็น AF อีกประเภทหนึ่ง เป็นฟังก์ชันที่มีศูนย์กลางเป็นศูนย์ที่ราบรื่นยิ่งขึ้นซึ่งมีช่วงระหว่าง -1 ถึง 1 ดังนั้น เอาต์พุตของฟังก์ชัน tanh จึงแสดงโดย:
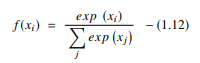
แหล่งที่มา
ฟังก์ชัน tanh ใช้กันอย่างแพร่หลายมากกว่าฟังก์ชัน sigmoid เนื่องจากให้ประสิทธิภาพการฝึกที่ดีขึ้นสำหรับโครงข่ายประสาทหลายชั้น ข้อได้เปรียบที่ใหญ่ที่สุดของฟังก์ชัน tanh คือให้เอาต์พุตที่มีศูนย์กลางเป็นศูนย์ ซึ่งจะช่วยสนับสนุนกระบวนการย้อนกลับ ฟังก์ชัน tanh ถูกใช้เป็นส่วนใหญ่ในโครงข่ายประสาทเทียมสำหรับการประมวลผลภาษาธรรมชาติและการรู้จำคำพูด
อย่างไรก็ตาม ฟังก์ชัน tanh ก็ยังมีข้อจำกัด เช่นเดียวกับฟังก์ชัน sigmoid ที่ไม่สามารถแก้ปัญหาการไล่ระดับสีที่หายไปได้ นอกจากนี้ ฟังก์ชัน tanh สามารถบรรลุการไล่ระดับสี 1 เมื่อค่าอินพุตเป็น 0 (x เป็นศูนย์) เท่านั้น เป็นผลให้ฟังก์ชันสามารถผลิต เซลล์ประสาทที่ตายแล้ว บางส่วน ในระหว่างกระบวนการคำนวณ
3. ฟังก์ชัน Softmax
ฟังก์ชัน softmax เป็น AF อีกประเภทหนึ่งที่ใช้ในโครงข่ายประสาทเทียมเพื่อคำนวณการกระจายความน่าจะเป็นจากเวกเตอร์ของจำนวนจริง ฟังก์ชันนี้สร้างเอาต์พุตที่มีช่วงระหว่างค่า 0 ถึง 1 และมีผลรวมของความน่าจะเป็นเท่ากับ 1 ฟังก์ชัน softmax จะแสดงดังนี้:
แหล่งที่มา
ฟังก์ชันนี้ใช้เป็นหลักในโมเดลหลายคลาส โดยจะคืนค่าความน่าจะเป็นของแต่ละคลาส โดยคลาสเป้าหมายมีความน่าจะเป็นสูงสุด ปรากฏในเลเยอร์เอาต์พุตเกือบทั้งหมดของสถาปัตยกรรม DL ที่ใช้ ความแตกต่างหลักระหว่าง sigmoid และ softmax AF คือในขณะที่อดีตใช้ในการจำแนกประเภทไบนารี ส่วนหลังจะใช้สำหรับการจำแนกประเภทหลายตัวแปร
4. ฟังก์ชัน Softsign
ฟังก์ชัน softsign เป็นอีกหนึ่ง AF ที่ใช้ในการคำนวณเครือข่ายประสาทเทียม แม้ว่าจะเป็นปัญหาการคำนวณการถดถอยเป็นหลัก แต่ทุกวันนี้ก็ยังใช้ในแอปพลิเคชันการแปลงข้อความเป็นคำพูดที่ใช้ DL เป็นพหุนามกำลังสอง แทนด้วย:
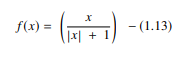
แหล่งที่มา
ที่นี่ "x" เท่ากับค่าสัมบูรณ์ของอินพุต
ความแตกต่างหลัก ระหว่างฟังก์ชัน softsign และฟังก์ชัน tanh คือ ไม่เหมือนกับฟังก์ชัน tanh ที่บรรจบกันแบบทวีคูณ ฟังก์ชัน softsign จะมาบรรจบกันในรูปแบบพหุนาม
5. ฟังก์ชันหน่วยเชิงเส้นตรง (ReLU) ที่แก้ไข
หนึ่งใน AF ที่ได้รับความนิยมมากที่สุดในรุ่น DL คือฟังก์ชัน rectified linear unit (ReLU) เป็น AF ที่เรียนรู้ได้รวดเร็วซึ่งสัญญาว่าจะให้ประสิทธิภาพที่ล้ำสมัยพร้อมผลลัพธ์ที่เป็นตัวเอก เมื่อเปรียบเทียบกับ AF อื่นๆ เช่น ฟังก์ชัน sigmoid และ tanh ฟังก์ชัน ReLU ให้ประสิทธิภาพและลักษณะทั่วไปที่ดีกว่าในการเรียนรู้เชิงลึก ฟังก์ชันนี้เป็นฟังก์ชันที่เกือบเป็นเส้นตรงที่คงคุณสมบัติของแบบจำลองเชิงเส้นไว้ ซึ่งทำให้ง่ายต่อการปรับให้เหมาะสมด้วยวิธีลาดลงสู่ระดับต่ำ
ฟังก์ชัน ReLU ดำเนินการตามขีดจำกัดบนแต่ละองค์ประกอบอินพุต โดยที่ค่าทั้งหมดที่น้อยกว่าศูนย์ถูกตั้งค่าเป็นศูนย์ ดังนั้น ReLU จึงแสดงเป็น:
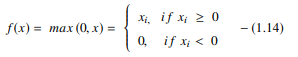
แหล่งที่มา
โดยการแก้ไขค่าของอินพุตที่น้อยกว่าศูนย์และตั้งค่าให้เป็นศูนย์ ฟังก์ชันนี้จะขจัดปัญหาการไล่ระดับสีที่หายไปซึ่งพบได้ในฟังก์ชันการเปิดใช้งานประเภทก่อนหน้า (sigmoid และ tanh)
ข้อได้เปรียบที่สำคัญที่สุดของการใช้ฟังก์ชัน ReLU ในการคำนวณคือรับประกันการคำนวณที่เร็วขึ้น โดยไม่คำนวณเลขชี้กำลังและการหาร ซึ่งจะช่วยเพิ่มความเร็วในการคำนวณโดยรวม อีกแง่มุมที่สำคัญของฟังก์ชัน ReLU คือการเพิ่มความกระปรี้กระเปร่าในหน่วยที่ซ่อนอยู่โดยการบีบค่าระหว่างศูนย์ถึงค่าสูงสุด
6. ฟังก์ชันเอกซ์โปเนนเชียลลิเนียร์ (ELUs)
ฟังก์ชัน exponential linear unit (ELUs) คือ AF ที่ใช้เพื่อเพิ่มความเร็วในการฝึกอบรมเครือข่ายประสาทเทียม (เช่นเดียวกับฟังก์ชัน ReLU) ข้อได้เปรียบที่ใหญ่ที่สุดของฟังก์ชัน ELU คือสามารถขจัดปัญหาการไล่ระดับสีที่หายไปได้โดยใช้ข้อมูลประจำตัวสำหรับค่าบวกและโดยการปรับปรุงลักษณะการเรียนรู้ของแบบจำลอง
ELU มีค่าลบที่ผลักดันให้การเปิดใช้งานหน่วยเฉลี่ยเข้าใกล้ศูนย์ ซึ่งจะช่วยลดความซับซ้อนในการคำนวณและปรับปรุงความเร็วในการเรียนรู้ ELU เป็นทางเลือกที่ยอดเยี่ยมสำหรับ ReLU โดยจะลดการเบี่ยงเบนของอคติโดยการกดการเปิดใช้งานเฉลี่ยไปที่ศูนย์ในระหว่างกระบวนการฝึกอบรม
ฟังก์ชันหน่วยเชิงเส้นแบบเลขชี้กำลังแสดงเป็น:
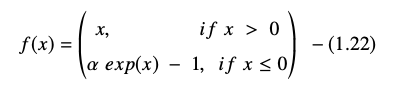
อนุพันธ์หรือเกรเดียนต์ของสมการ ELU แสดงเป็น:
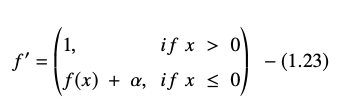
แหล่งที่มา
ในที่นี้ “α” เท่ากับไฮเปอร์พารามิเตอร์ ELU ที่ควบคุมจุดอิ่มตัวสำหรับอินพุตสุทธิเชิงลบ ซึ่งมักจะตั้งค่าเป็น 1.0 อย่างไรก็ตาม ฟังก์ชัน ELU มีข้อจำกัด ซึ่งไม่ใช่ศูนย์
บทสรุป
ทุกวันนี้ AF เช่น ReLU และ ELU ได้รับความสนใจสูงสุด เนื่องจากช่วยขจัดปัญหาการไล่ระดับสีที่หายไป ซึ่งเป็นสาเหตุของปัญหาสำคัญในกระบวนการฝึกอบรม และลดความแม่นยำและประสิทธิภาพของโมเดลโครงข่ายประสาทเทียม
ลองดูโปรแกรมการรับรองขั้นสูงใน Machine Learning & Cloud กับ IIT Madras ซึ่งเป็นโรงเรียนวิศวกรรมที่ดีที่สุดในประเทศเพื่อสร้างโปรแกรมที่สอนคุณไม่เพียงแต่แมชชีนเลิร์นนิง แต่ยังรวมถึงการปรับใช้อย่างมีประสิทธิภาพโดยใช้โครงสร้างพื้นฐานระบบคลาวด์ เป้าหมายของเราในโปรแกรมนี้คือการเปิดประตูของสถาบันที่คัดเลือกมามากที่สุดในประเทศและให้ผู้เรียนเข้าถึงคณาจารย์และทรัพยากรที่น่าทึ่งเพื่อฝึกฝนทักษะที่สูงและเติบโต
โครงข่ายประสาทเทียมคืออะไร?
ANN เป็นแบบจำลองการเรียนรู้เชิงลึกที่ได้รับแรงบันดาลใจจากโครงสร้างประสาทของสมองมนุษย์ ANN ถูกสร้างขึ้นเพื่อจำลองกิจกรรมของสมองมนุษย์ ซึ่งเรียนรู้จากประสบการณ์ของพวกเขาและปรับให้เข้ากับสภาพแวดล้อม ANN มีเครือข่ายของเซลล์ประสาทที่เชื่อมต่อซึ่งกันและกันด้วยซอน คล้ายกับที่จิตใจของมนุษย์มีโครงสร้างหลายชั้น โดยมีเซลล์ประสาทหลายพันล้านเซลล์จัดเรียงเป็นลำดับชั้น สัญญาณไฟฟ้า (เรียกว่า ไซแนปส์) ถูกส่งจากชั้นหนึ่งไปยังอีกชั้นหนึ่งโดยเซลล์ประสาทที่เชื่อมโยงกันเหล่านี้ ANN สามารถเรียนรู้จากประสบการณ์โดยไม่จำเป็นต้องมีส่วนร่วมของมนุษย์ ต้องขอบคุณการจำลองสมองโดยประมาณนี้
ฟังก์ชั่นการเปิดใช้งานในโครงข่ายประสาทเทียมคืออะไร?
ANN ใช้ฟังก์ชันการเปิดใช้งาน (AF) ในเลเยอร์ที่ซ่อนอยู่เพื่อดำเนินการคำนวณที่ซับซ้อน จากนั้นจึงโอนผลลัพธ์ไปยังเลเยอร์เอาต์พุต เป้าหมายพื้นฐานของ AFs คือการทำให้โครงข่ายประสาทเทียมมีคุณสมบัติไม่เป็นเชิงเส้น พวกเขาเปลี่ยนสัญญาณอินพุตเชิงเส้นของโหนดเป็นสัญญาณเอาต์พุตที่ไม่ใช่เชิงเส้นเพื่อช่วยให้เครือข่ายลึกเรียนรู้พหุนามลำดับสูงที่มีมากกว่าหนึ่งองศา AF มีความแตกต่างกันตรงที่ต่างกันได้ ซึ่งช่วยสนับสนุนบทบาทของพวกเขาในระหว่างการขยายพันธุ์ของโครงข่ายประสาทเทียม
ความต้องการความไม่เชิงเส้นคืออะไร?
ถ้าไม่มีการใช้ฟังก์ชันการเปิดใช้งาน สัญญาณเอาต์พุตจะเป็นการแปลงเชิงเส้น ซึ่งเป็นพหุนามหนึ่งดีกรี แม้ว่าสมการเชิงเส้นจะแก้ได้ง่าย แต่ก็มีความฉลาดทางความซับซ้อนต่ำ ซึ่งจำกัดความสามารถในการเรียนรู้การแมปที่ซับซ้อนจากข้อมูล โครงข่ายประสาทเทียมที่ไม่มี AF จะเป็นโมเดลเชิงเส้นตรงทั่วไปที่มีความสามารถจำกัด นี่ไม่ใช่ประสิทธิภาพที่เราต้องการจากโครงข่ายประสาทเทียม โครงข่ายประสาทเทียมถูกนำมาใช้ในการคำนวณที่ซับซ้อนอย่างยิ่ง นอกจากนี้ โครงข่ายประสาทเทียมจะไม่สามารถเรียนรู้และแสดงข้อมูลที่ซับซ้อนอื่นๆ ได้หากไม่มี AF เช่น รูปภาพ เสียง ภาพยนตร์ เสียง และอื่นๆ