
Интуиция за анализом настроений: как провести анализ настроений с нуля?
Опубликовано: 2020-12-07Оглавление
Введение
Текст является важнейшим средством восприятия информации для человека. Большая часть интеллекта, получаемого людьми, достигается за счет изучения и понимания смысла текстов и предложений вокруг них.
После определенного возраста у людей вырабатывается внутренний рефлекс, позволяющий понять вывод любого слова/текста, даже не подозревая об этом. Для машин эта задача совсем другая. Чтобы усвоить значения текстов и предложений, машины полагаются на основы обработки естественного языка (NLP).
Глубокое обучение для обработки естественного языка — это распознавание образов, применяемое к словам, предложениям и абзацам, почти так же, как компьютерное зрение — это распознавание образов, применяемое к пикселям изображения.
Ни одна из этих моделей глубокого обучения не понимает текст в человеческом смысле; скорее, эти модели могут отображать статистическую структуру письменного языка, чего достаточно для решения многих простых текстовых задач. Анализ настроений является одной из таких задач, например: классификация настроений строк или обзоров фильмов как положительных или отрицательных.
Они также имеют широкое применение в промышленности. Например: компания, производящая товары и услуги, хотела бы собрать данные о количестве положительных и отрицательных отзывов, которые она получила для конкретного продукта, чтобы работать над жизненным циклом продукта и улучшить свои показатели продаж и собрать отзывы клиентов.
Предварительная обработка
Задачу анализа настроений можно разбить на простой алгоритм машинного обучения с учителем, где у нас обычно есть вход X , который входит в функцию прогнозирования для получения Затем мы сравниваем наш прогноз с истинным значением Y . Это дает нам стоимость, которую мы затем используем для обновления параметров Чтобы решить задачу извлечения настроений из ранее невидимого потока текстов, простейшим шагом является сбор помеченного набора данных с отдельными положительными и отрицательными настроениями. Этими настроениями могут быть: хороший отзыв или плохой отзыв, саркастическое замечание или несаркастическое замечание и т. д.
Следующим шагом является создание вектора размерности V , где Этот вектор словаря будет содержать каждое слово (ни одно слово не повторяется) , присутствующее в нашем наборе данных, и будет действовать как словарь для нашей машины, на который он может ссылаться. Теперь мы предварительно обрабатываем вектор словаря, чтобы удалить избыточность. Выполняются следующие шаги:
- Исключение URL-адресов и другой нетривиальной информации (которая не помогает определить смысл предложения)
- Токенизация строки в слова: предположим, у нас есть строка «Я люблю машинное обучение», теперь с помощью токенизации мы просто разбиваем предложение на отдельные слова и сохраняем его в списке как [I, love, machine, learning]
- Удаление стоп-слов вроде «и», «есть», «или», «я» и т. д.
- Стемминг: мы преобразуем каждое слово в его основу. Такие слова, как «настроить», «настроить» и «настроить», имеют семантически одно и то же значение, поэтому сокращение их до основной формы, то есть «tun», уменьшит размер словарного запаса.
- Преобразование всех слов в нижний регистр
Чтобы подытожить этап предварительной обработки, давайте рассмотрим пример: допустим, у нас есть положительная строка «Мне нравится новый продукт на upGrad.com» . Окончательная предварительно обработанная строка получается путем удаления URL-адреса, токенизации предложения в один список слов, удаления стоп-слов, таких как «I, am, the, at», а затем объединения слов «loving» с «lov» и «product». на «produ» и, наконец, преобразовать все это в нижний регистр, что приводит к списку [lov, new, produ] .
Извлечение признаков
После предварительной обработки корпуса следующим шагом будет извлечение признаков из списка предложений. Как и все другие нейронные сети, модели глубокого обучения не принимают на вход необработанный текст: они работают только с числовыми тензорами. Следовательно, предварительно обработанный список слов необходимо преобразовать в числовые значения. Это можно сделать следующим образом. Предположим, что задана компиляция строк с положительными и отрицательными строками, такими как (предположим, что это набор данных) :
| Положительные строки | Отрицательные строки |
|
|
Теперь, чтобы преобразовать каждую из этих строк в числовой вектор размерности 3, мы создаем словарь для сопоставления слова и класса, в котором оно появилось (положительного или отрицательного) , с количеством раз, которое это слово появлялось в соответствующем классе.
| Словарь | Положительная частота | Отрицательная частота |
| я | 3 | 3 |
| являюсь | 3 | 3 |
| счастливый | 2 | 0 |
| потому что | 1 | 0 |
| учусь | 1 | 1 |
| НЛП | 1 | 1 |
| печальный | 0 | 2 |
| нет | 0 | 1 |
После создания вышеупомянутого словаря мы смотрим на каждую из строк по отдельности, а затем суммируем количество положительных и отрицательных частотных чисел слов, которые появляются в строке, оставляя слова, которые не появляются в строке. Возьмем строку «Мне грустно, я не изучаю НЛП» и сгенерируем вектор размерности 3.

«Мне грустно, я не изучаю НЛП»
| Словарь | Положительная частота | Отрицательная частота |
| я | 3 | 3 |
| являюсь | 3 | 3 |
| счастливый | 2 | 0 |
| потому что | 1 | 0 |
| учусь | 1 | 1 |
| НЛП | 1 | 1 |
| печальный | 0 | 2 |
| нет | 0 | 1 |
| Сумма = 8 | Сумма = 11 |
Мы видим, что для строки «Мне грустно, я не изучаю НЛП» только два слова «счастливый, потому что» не содержатся в словаре, теперь для извлечения признаков и создания указанного вектора суммируем положительную и отрицательную частоты столбцы отдельно, опуская номер частоты слов, которых нет в строке, в этом случае мы оставляем «счастливый, потому что». Мы получаем сумму как 8 для положительной частоты и 9 для отрицательной частоты.
Следовательно, строка «Мне грустно, я не изучаю НЛП» может быть представлена в виде вектора Число «1», присутствующее в индексе 0, является единицей смещения, которая останется «1» для всех последующих строк, а числа «8», «11» представляют собой сумму положительных и отрицательных частот соответственно.
Аналогичным образом все строки в наборе данных можно удобно преобразовать в вектор размерности 3.
Подробнее: Анализ настроений с использованием Python: практическое руководство
Применение логистической регрессии
Извлечение признаков позволяет легко понять суть предложения, но машинам по-прежнему нужен более четкий способ пометить невидимую строку как положительную или отрицательную. Здесь в игру вступает логистическая регрессия, использующая сигмовидную функцию, которая выводит вероятность от 0 до 1 для каждой векторизованной строки.

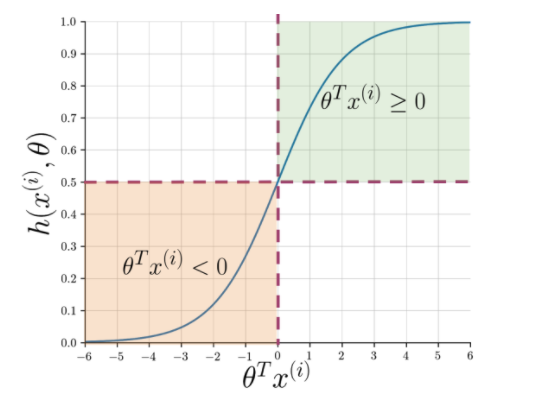
Рисунок 1: Графическое представление сигмовидной функции
На рис. 1 показано, что всякий раз, когда скалярное произведение тета и Читайте также: 4 лучших идеи проекта по аналитике данных: уровень от новичка до эксперта
Что дальше?
Анализ настроений является важной темой в машинном обучении. Он имеет множество приложений в различных областях. Если вы хотите узнать больше об этой теме, вы можете зайти в наш блог и найти много новых ресурсов.
С другой стороны, если вы хотите получить всесторонний и структурированный опыт обучения, а также если вам интересно узнать больше о машинном обучении, ознакомьтесь с дипломом PG IIIT-B и upGrad в области машинного обучения и искусственного интеллекта, который предназначен для работающих профессионалов. и предлагает более 450 часов тщательного обучения, более 30 тематических исследований и заданий, статус выпускника IIIT-B, более 5 практических практических проектов и помощь в трудоустройстве в ведущих фирмах.
Q1. Почему алгоритм случайного леса лучше всего подходит для машинного обучения?
Алгоритм случайного леса относится к категории алгоритмов обучения с учителем, которые широко используются при разработке различных моделей машинного обучения. Алгоритм случайного леса можно применять как для классификационных, так и для регрессионных моделей. Что делает этот алгоритм наиболее подходящим для машинного обучения, так это тот факт, что он блестяще работает с многомерной информацией, поскольку машинное обучение в основном имеет дело с подмножествами данных. Интересно, что алгоритм случайного леса является производным от алгоритма деревьев решений. Но вы можете обучаться с использованием этого алгоритма за гораздо более короткий промежуток времени, чем с помощью деревьев решений, поскольку он использует только определенные функции. Он предлагает большую эффективность в моделях машинного обучения, поэтому его предпочитают больше.
Q2. Чем машинное обучение отличается от глубокого обучения?
И глубокое обучение, и машинное обучение являются подобластями всего зонтика, который мы называем искусственным интеллектом. Однако эти два подполя имеют свои отличия. Глубокое обучение — это, по сути, подмножество машинного обучения. Однако, используя глубокое обучение, машины могут анализировать видео, изображения и другие формы неструктурированных данных, чего может быть трудно достичь, используя только машинное обучение. Машинное обучение позволяет компьютерам думать и действовать самостоятельно с минимальным вмешательством человека. Напротив, глубокое обучение используется, чтобы помочь машинам думать на основе структур, напоминающих человеческий мозг.
Q3. Почему специалисты по данным предпочитают алгоритм случайного леса?
Алгоритм случайного леса имеет много преимуществ, что делает его предпочтительным выбором среди специалистов по обработке и анализу данных. Во-первых, он обеспечивает очень точные результаты по сравнению с другими линейными алгоритмами, такими как логистическая и линейная регрессия. Несмотря на то, что этот алгоритм может быть сложным для объяснения, его легче проверять и интерпретировать результаты на основе лежащих в его основе деревьев решений. Вы можете использовать этот алгоритм с одинаковой легкостью, даже когда к нему добавляются новые образцы и функции. Его легко использовать, даже если некоторые данные отсутствуют.