
Анализ выражений в структуре данных: типы обозначений, ассоциативность и приоритет
Опубликовано: 2020-10-07Синтаксический анализ — это процесс анализа строки символов, выраженной на естественном или компьютерном языке, который соответствует формальной грамматике . Анализ выражений в структуре данных означает оценку арифметических и логических выражений. Во-первых, давайте посмотрим, как записывается арифметическое выражение:
- 9+9
- Кб
Выражение может быть записано с константами, переменными и символами, которые могут выступать в качестве оператора или скобки. Все это выражение должно следовать определенному набору правил. В соответствии с этим правилом разбор выражения выполняется на основе грамматики.
Арифметическое выражение выражается в виде нотации . Теперь есть три способа написать выражение в арифметике:
- Инфиксная нотация
- Префиксная (польская) нотация
- Постфиксная (обратная польская) нотация
Однако, когда выражение записано, вывод желаемого выражения остается прежним. Прежде чем приступить к работе с типами нотации, давайте посмотрим, что такое ассоциативность и приоритет в анализе выражений в структуре данных.
Если вы новичок и хотите узнать больше о науке о данных, ознакомьтесь с нашими курсами по науке о данных от лучших университетов.
Читайте: Графики в структуре данных
Оглавление
Ассоциативность
Прежде чем начать, вам нужно знать, что такое свойство Ассоциативность; он предоставляет вам правила перестановки круглых скобок в выражении, чтобы обеспечить действительное доказательство. Это означает, что перестановка скобок должна давать то же значение, что и исходное уравнение. Он предоставляет допустимое правило для замены операторов.
В выражении, содержащем два или более операторов, выполняемая операция не имеет значения, если последовательность операндов не меняется местами. Если выражение написано с использованием скобок и инфикса, изменение позиции не меняет значения.
Поскольку в индоевропейских языках выражения читаются слева направо, большинство инфиксных операторов являются левоассоциативными; операторы оцениваются с одинаковым приоритетом. Восхождение в силе — это правило, используемое при рассмотрении инфиксных операторов. Префиксные операторы, как правило, правоассоциативны, а постфиксные операторы — левоассоциативны.
В некоторых языках операторам и операндам присваивается одинаковое значение, где ассоциативность не считается явной для этой языковой последовательности. Хотя в некоторых языках операторы неассоциативны, это делает использование сложных выражений необходимым для использования скобок, что увеличивает сложность для программистов.
Приоритет в структуре данных
Порядок приоритета означает, в каком порядке операторы должны следовать в операторе выражений. Это обычно используется при работе с инфиксной нотацией.
В ситуации <оператор> <операнд> <оператор> операнд между двумя операторами, предпочтение выделить оператор довольно сложно. Следовательно, для расчета соблюдаются правила приоритета оператора. Например, здесь умножение имеет более высокий приоритет, а затем выполняется операция сложения.
- Наиболее распространенное, но не столь очевидное правило заключается в том, что операции умножения и деления должны выполняться перед сложением и вычитанием. Как правило, они собираются одинаково, поэтому всем операторам придается одинаковая важность.
- Рассматривая эту операцию в логическом формате, вариации видны в «и» и «или». Многие языки обеспечивают одинаковую важность, где операция «или» имеет более высокий приоритет. Некоторые языки считают умножение или «&», «&» сложение «или» равным приоритетом, тогда как большинство языков предоставляют арифметические операции с наивысшим приоритетом.
- Перегрузка возникает из-за неправильного распределения приоритета. Многие языки обеспечивают более высокий приоритет отрицания (истина/ложь), чем выражения векторной алгебры, в то время как некоторые обеспечивают равный приоритет.
Читайте также: Идеи проекта структуры данных
Типы обозначений
Теперь давайте узнаем, как положение оператора определяет тип нотации.
1. Инфиксная нотация
В инфиксной нотации операторы используются между операндами. При чтении выражения инфиксная нотация довольно проста для людей. Но обработка инфиксного аргумента занимает довольно много времени и места, когда речь идет о компьютерном алгоритме. Например: п + к
<операнды> <операторы> <операнды>
Инфиксная нотация нуждается в дополнительной информации для выполнения оценки; правила встраиваются в язык выражений с помощью операторов Associativity , Например: p * ( q + r ) / s
- Правила ассоциативности предполагают, что выражение должно выполняться слева направо, так что умножение на p выполняется до деления на q.
- Точно так же правила приоритета предполагают, что операции умножения и деления выполняются до выполнения операций сложения и вычитания.
2. Префиксная запись
Здесь сначала пишется оператор, а затем операнд. Его также называют польской нотацией. Например +pq
<операторы> <операнды> <операнды>
Например: p * ( q + r ) / с
Оценка должна выполняться слева направо, а скобки не изменяют и не изменяют шаблон уравнения. Здесь сложение должно быть завершено до умножения, потому что позиция «+» слева от «*».
Здесь каждый оператор выполняет операции над значениями, которые находятся непосредственно слева от них. Например, «+» выше использует «q» и «r». Мы можем суммировать скобки, чтобы сделать это явным:
((p(qr+)*)s/)
Таким образом, «()» рассматривает и использует два значения, непосредственно предшествующие «p», и результат «+». Точно так же «/» использует результат выражения умножения и «s».

3. Постфиксная нотация
Постфиксная нотация, в первую очередь записывается операнд, за которым следует оператор. Его также называют обратной польской нотацией, например, pq+
<операнды> <операнды> <операторы>
Что касается постфикса, то же, что и префиксная операция выражения, выполняется слева направо и «()» не нужны. Здесь операторы работают с двумя ближайшими значениями справа. В приведенном ниже примере скобки добавлены без необходимости, чтобы прояснить, что это не влияет на оценку.
(/ (* р (+ qr)) s)
Здесь «вычисление оператора слева направо», значения операций находятся справа от них, а если значения сами по себе предполагают вычисления, то происходит изменение порядка вычисления. Взяв пример, указанный выше, см. «/» — это основной оператор слева.
Он ждет, пока операция умножения не завершится. И в первую очередь, операцию умножения нужно выполнить до того, как начнется вычисление деления (а из приведенного выше примера видно, что операцию сложения нужно выполнить до операции умножения).
Поскольку операторы Postfix Notation используют значение справа от него; любые значения, связанные с расчетами, будут иметь уже завершенный расчет, когда мы двигаемся влево. Итак, мы можем сделать вывод, что вычисление выражения не то же самое, что операция оператора префикса.
Чтобы выделить все три нотации, операнды идут в одном порядке, и операторы должны быть перемещены, чтобы обеспечить правильное значение во время вычисления. Это необходимо учитывать, в частности, при рассмотрении асимметричных операторов «-» и «/», чтобы было ясно, что pq всегда равно qr, если только они не имеют одинаковое значение; значения эквивалентны «pq -» или «- pq»
P+q ≡ +pq ≡ pq+
Например:
Инфикс- p*q+r/s
Префикс – pq*rs/+
Постфикс — +*pq/rs
Сначала для выполнения операции умножьте p и q, затем разделите r на s и, наконец, сложите результаты.
Ниже приведены краткие таблицы между тремя обозначениями,
| Инфиксная нотация | Польская нотация | Обратное польское обозначение |
| р+к | +pq | pq+ |
| (р+к)*р | +*pq | pqr+* |
| р*(д+г) | *р+кв | пгр*+ + |
| p÷q+r÷s | +÷pq÷rs | pq÷rs÷+ |
| (пкв)*(рс) | *-pq-rs | pq-rs-* |
Преобразование между нотациями
*Для ясности в выражении добавлены скобки
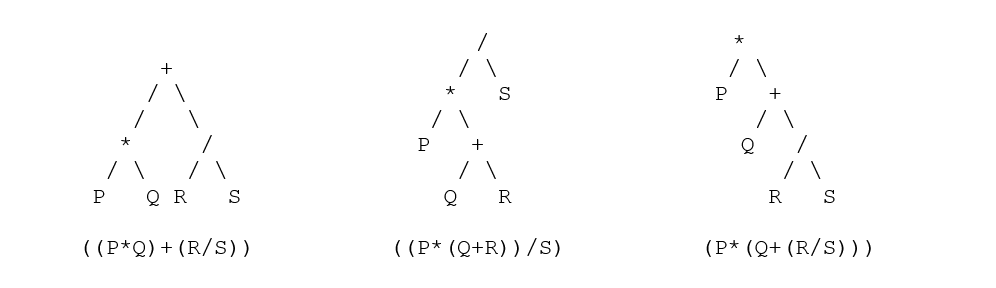
| Инфикс | Постфикс | Приставка |
| ((p*q) + (r/s)) | ((pq*)(rs/)+) | (+ (* пк) (/рс)) ) |
| ((p * (q + r)) / с) | ((p(qr+)*)s/) | (/ (* р (+ qr)) s) |
| (p * (q + (r/s)) ) | (p(q(rs/)+)*) | (* p (+ q (/ rs)) ) |
- Вы можете начать преобразование непосредственно в скобках с помощью операторов в скобках, например, (m + n) или (mn +) или (+ mn). Теперь повторите это во всех операторах, удалив ненужные скобки.
- Теперь используйте этот прием, показанный выше, для преобразования и разбора деревьев — эквивалентные деревья разбора для каждого узла:
Оформление заказа: структура данных и алгоритм в Python
Заключение
Анализ выражений в структуре данных , инфиксные, постфиксные и префиксные нотации в арифметических выражениях совершенно разные, но имеют одинаковые способы записи выражений. Их знание необходимо при написании программ.
В языке программирования выражение рассматривается и анализируется из строки. Правила Ассоциативности и Приоритета сильно различаются в разных языках.
Почему стоит выбрать курс по науке о данных с upGrad?
Наука о данных — одна из бурно развивающихся областей информатики. Компаниям нужны программисты, хорошо знающие основы, что необходимо для программирования независимо от языка программирования.
upGrad фокусируется на предоставлении проницательных и информативных классов, охватывающих все основные потребности, необходимые для того, чтобы стать специалистом по данным. 12-месячная программа upGrad Executive PG по науке о данных. , предлагаемый IIIT Bangalore, является первым в Индии сертифицированным курсом NASSCOM, который включает индивидуальное наставничество 1: 1 от экспертов отрасли обработки данных, охватывающее все основные языки программирования, инструменты и библиотеки. Он предоставляет вам наилучшую основу для начала вашей высокооплачиваемой работы в области науки о данных.
Что такое структуры данных?
Структуры данных используются для организации данных в памяти. Существует несколько методов организации данных в памяти, включая массивы, списки, стеки, очереди и многие другие. Структура данных не является языком программирования, как C, C++ или Java. Вместо этого это набор методов, которые используются для организации данных в памяти на любом языке программирования. Структура данных — это метод эффективной организации, обработки и хранения данных. Элементы данных могут быть просто пройдены с помощью структуры данных. Это имеет решающее значение для повышения скорости работы программы, поскольку основная задача программы заключается в сохранении и извлечении данных пользователя как можно быстрее.
Каково реальное использование синтаксического анализа данных?
Процесс преобразования данных из одного формата в другой называется синтаксическим анализом данных. Они широко используются в компиляторах для разбора компьютерного кода и генерации машинного кода. Процесс преобразования данных из одного формата в другой называется синтаксическим анализом данных. Поскольку необработанный HTML-код, который мы получаем, сложен для понимания, парсеры часто используются для онлайн-скрапинга. Мы требуем, чтобы данные были преобразованы в удобочитаемый формат. Это может подразумевать создание отчетов с использованием строк или таблиц HTML для предоставления наиболее релевантной информации.
Как Ассоциативность и Приоритет помогают в структурировании данных?
Порядок вычисления выражений определяется двумя свойствами операторов: приоритетом и ассоциативностью. Приоритет помогает установить, как следует группировать термины в выражении и как выражение должно оцениваться. Поскольку большинство выражений используют структуру BODMAS, некоторые операторы имеют приоритет над другими. Когда два оператора имеют одинаковый приоритет в выражении, применяется правило ассоциативности. В зависимости от предпочтений компилятора ассоциативность может быть либо слева направо, либо справа налево.