
O intuiție în spatele analizei sentimentelor: cum să faci o analiză a sentimentelor de la zero?
Publicat: 2020-12-07Cuprins
Introducere
Textul este cel mai important mijloc de percepere a informațiilor pentru ființe umane. Cea mai mare parte a inteligenței dobândite de oameni este prin învățarea și înțelegerea sensului textelor și propozițiilor din jurul lor.
După o anumită vârstă, oamenii dezvoltă un reflex intrinsec de a înțelege inferența oricărui cuvânt/text fără să știe. Pentru mașini, această sarcină este complet diferită. Pentru a asimila semnificațiile textelor și propozițiilor, mașinile se bazează pe elementele fundamentale ale procesării limbajului natural (NLP).
Învățarea profundă pentru procesarea limbajului natural este recunoașterea modelelor aplicată cuvintelor, propozițiilor și paragrafelor, în același mod în care viziunea computerizată este recunoașterea modelelor aplicată pixelilor imaginii.
Niciunul dintre aceste modele de învățare profundă nu înțelege cu adevărat textul în sens uman; mai degrabă, aceste modele pot mapa structura statistică a limbajului scris, ceea ce este suficient pentru a rezolva multe sarcini textuale simple. Analiza sentimentelor este o astfel de sarcină, de exemplu: clasificarea sentimentelor șirurilor sau a recenziilor de filme ca pozitive sau negative.
Acestea au aplicații pe scară largă și în industrie. De exemplu: o companie de bunuri și servicii ar dori să adune date despre numărul de recenzii pozitive și negative pe care le-a primit pentru un anumit produs, pentru a funcționa pe ciclul de viață al produsului și pentru a-și îmbunătăți cifrele de vânzări și pentru a colecta feedback-ul clienților.
Preprocesare
Sarcina analizei sentimentelor poate fi împărțită într-un algoritm simplu de învățare automată supravegheat, în care de obicei avem o intrare X , care intră într-o funcție de predictor pentru a obține Apoi comparăm predicția noastră cu valoarea reală Y , aceasta ne oferă costul pe care îl folosim apoi pentru a actualiza parametrii Pentru a aborda sarcina de a extrage sentimente dintr-un flux de texte nevăzut anterior, pasul primitiv este de a aduna un set de date etichetat cu sentimente pozitive și negative separate. Aceste sentimente pot fi: recenzie bună sau recenzie proastă, remarcă sarcastică sau remarcă non-sarcastică etc.
Următorul pas este crearea unui vector cu dimensiunea V , unde Acest vector de vocabular va conține fiecare cuvânt (niciun cuvânt nu se repetă) care este prezent în setul nostru de date și va acționa ca un lexic pentru mașina noastră la care se poate referi. Acum preprocesăm vectorul de vocabular pentru a elimina redundanțele. Se efectuează următorii pași:
- Eliminarea adreselor URL și a altor informații non-triviale (care nu ajută la determinarea sensului unei propoziții)
- Tokenizarea șirului în cuvinte: să presupunem că avem șirul „Iubesc învățarea automată”, acum prin tokenizare pur și simplu împărțim propoziția în cuvinte simple și o stocăm într-o listă ca [Eu, dragoste, mașină, învățarea]
- Eliminarea cuvintelor stop precum „și”, „sunt”, „sau”, „eu”, etc.
- Stemming: transformăm fiecare cuvânt în forma lui stem. Cuvinte precum „tune”, „tuning” și „tuned” au aceeași semnificație din punct de vedere semantic, așa că reducerea lor la forma tulpină care este „tun” va reduce dimensiunea vocabularului.
- Conversia tuturor cuvintelor în minuscule
Pentru a rezuma pasul de preprocesare, să aruncăm o privire la un exemplu: să spunem că avem un șir pozitiv „Îmi place noul produs la upGrad.com” . Șirul final preprocesat este obținut prin eliminarea adresei URL, tokenizarea propoziției într-o singură listă de cuvinte, eliminarea cuvintelor oprite precum „Eu, sunt, la, la”, apoi împuternicirea cuvintelor „iubitor” la „iubit” și „produs”. la „produ” și în cele din urmă conversia totul în litere mici, ceea ce are ca rezultat lista [lov, new, produ] .
Extragerea caracteristicilor
După ce corpus este preprocesat, următorul pas ar fi extragerea caracteristicilor din lista de propoziții. Ca toate celelalte rețele neuronale, modelele de învățare profundă nu iau ca intrare text brut: funcționează doar cu tensori numerici. Lista de cuvinte preprocesată trebuie, prin urmare, să fie convertită în valori numerice. Acest lucru se poate face în felul următor. Să presupunem că, având în vedere o compilație de șiruri cu șiruri pozitive și negative, cum ar fi (să presupunem că aceasta este setul de date) :
| Corzi pozitive | Corzi negative |
|
|
Acum, pentru a converti fiecare dintre aceste șiruri într-un vector numeric de dimensiunea 3, creăm un dicționar pentru a mapa cuvântul și clasa în care a apărut (pozitiv sau negativ) la numărul de ori a apărut acel cuvânt în clasa sa corespunzătoare.
| Vocabular | Frecvență pozitivă | Frecvență negativă |
| eu | 3 | 3 |
| a.m | 3 | 3 |
| fericit | 2 | 0 |
| deoarece | 1 | 0 |
| învăţare | 1 | 1 |
| NLP | 1 | 1 |
| trist | 0 | 2 |
| nu | 0 | 1 |
După generarea dicționarului menționat anterior, ne uităm la fiecare dintre șiruri individual, apoi însumăm numărul de frecvență pozitiv și negativ al cuvintelor care apar în șir, lăsând cuvintele care nu apar în șir. Să luăm șirul „Sunt trist, nu învăț NLP” și să generăm vectorul dimensiunii 3.

„Sunt trist, nu învăț NLP”
| Vocabular | Frecvență pozitivă | Frecvență negativă |
| eu | 3 | 3 |
| a.m | 3 | 3 |
| fericit | 2 | 0 |
| deoarece | 1 | 0 |
| învăţare | 1 | 1 |
| NLP | 1 | 1 |
| trist | 0 | 2 |
| nu | 0 | 1 |
| Suma = 8 | Suma = 11 |
Vedem că pentru șirul „Sunt trist, nu învăț NLP”, doar două cuvinte „fericit, pentru că” nu sunt conținute în vocabular, acum pentru a extrage caracteristici și a crea vectorul menționat, însumăm frecvența pozitivă și cea negativă. coloane separat lăsând deoparte numărul de frecvență al cuvintelor care nu sunt prezente în șir, în acest caz lăsăm „fericit, pentru că”. Obținem suma ca 8 pentru frecvența pozitivă și 9 pentru frecvența negativă.
Prin urmare, șirul „Sunt trist, nu învăț NLP” poate fi reprezentat ca un vector Numărul „1” prezent în indicele 0 este unitatea de polarizare care va rămâne „1” pentru toate șirurile viitoare, iar numerele „8”, „11” reprezintă suma frecvențelor pozitive și, respectiv, negative.
Într-o manieră similară, toate șirurile din setul de date pot fi convertite confortabil într-un vector de dimensiunea 3.
Citiți mai multe: Analiza sentimentelor folosind Python: un ghid practic
Aplicarea regresiei logistice
Extragerea caracteristicilor facilitează înțelegerea esenței propoziției, dar mașinile au nevoie de o modalitate mai clară de a semnala un șir nevăzut în pozitiv sau negativ. Aici intră în joc regresia logistică care folosește funcția sigmoidă care emite o probabilitate între 0 și 1 pentru fiecare șir vectorizat.

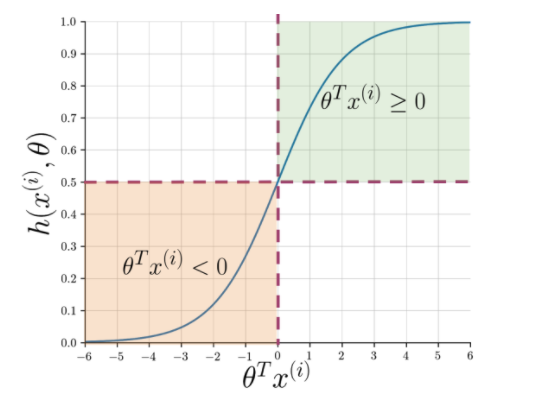
Figura 1: Notarea grafică a funcției sigmoide
Figura 1 arată că ori de câte ori produsul punctual al lui theta și Citește și: Top 4 idei de proiecte de analiză a datelor: nivel începător până la nivel expert
Ce urmează?
Analiza sentimentelor este un subiect esențial în învățarea automată. Are numeroase aplicații în mai multe domenii. Dacă doriți să aflați mai multe despre acest subiect, atunci puteți accesa blogul nostru și puteți găsi multe resurse noi.
Pe de altă parte, dacă doriți să obțineți o experiență de învățare cuprinzătoare și structurată, și dacă sunteți interesat să aflați mai multe despre învățarea automată, consultați Diploma PG de la IIIT-B și upGrad în învățare automată și AI, care este concepută pentru profesioniștii care lucrează. și oferă peste 450 de ore de pregătire riguroasă, peste 30 de studii de caz și sarcini, statutul de absolvenți IIIT-B, peste 5 proiecte practice practice și asistență pentru locuri de muncă cu firme de top.
Î1. De ce este algoritmul forestier aleatoriu cel mai bun pentru învățarea automată?
Algoritmul Random Forest aparține categoriei de algoritmi de învățare supravegheată, care sunt utilizați pe scară largă în dezvoltarea diferitelor modele de învățare automată. Algoritmul forestier aleatoriu poate fi aplicat atât pentru modelele de clasificare, cât și pentru cele de regresie. Ceea ce face ca acest algoritm să fie cel mai potrivit pentru învățarea automată este faptul că funcționează genial cu informații cu dimensiuni mari, deoarece învățarea automată se ocupă în principal cu subseturi de date. Interesant este că algoritmul forestier aleatoriu este derivat din algoritmul arborilor de decizie. Dar, vă puteți antrena folosind acest algoritm într-un interval de timp mult mai scurt decât folosind arbori de decizie, deoarece folosește doar caracteristici specifice. Oferă o eficiență mai mare în modelele de învățare automată și, prin urmare, este preferată mai mult.
Q2. Cum este învățarea automată diferită de învățarea profundă?
Atât învățarea profundă, cât și învățarea automată sunt subdomenii ale întregii umbrele pe care le numim inteligență artificială. Cu toate acestea, aceste două subcâmpuri vin cu propriile diferențe. Învățarea profundă este în esență un subset al învățării automate. Cu toate acestea, folosind învățarea profundă, mașinile pot analiza videoclipuri, imagini și alte forme de date nestructurate, ceea ce poate fi dificil de realizat folosind doar învățarea automată. Învățarea automată se referă la a permite computerelor să gândească și să acționeze singure, cu o intervenție umană minimă. În schimb, învățarea profundă este folosită pentru a ajuta mașinile să gândească pe baza unor structuri asemănătoare creierului uman.
Q3. De ce oamenii de știință preferă algoritmul forestier aleatoriu?
Există multe beneficii ale utilizării algoritmului forestier aleatoriu, ceea ce îl face alegerea preferată printre oamenii de știință de date. În primul rând, oferă rezultate foarte precise în comparație cu alți algoritmi liniari, cum ar fi regresia logistică și liniară. Chiar dacă acest algoritm poate fi dificil de explicat, este mai ușor să inspectezi și să interpretezi rezultatele pe baza arborilor de decizie care stau la bază. Puteți utiliza acest algoritm cu aceeași ușurință chiar și atunci când noi mostre și funcții sunt adăugate la el. Este ușor de utilizat chiar și atunci când unele date lipsesc.