
Înțelegerea entropiei arborelui de decizie în învățarea automată
Publicat: 2020-12-29Arborele de decizie este o parte a învățării automate supravegheate în care explicați intrarea pentru care se află rezultatul în datele de antrenament. În arborii de decizie, datele sunt împărțite de mai multe ori în funcție de parametrii dați. Continuă să împartă datele în subseturi mai mici și, simultan, arborele este dezvoltat progresiv. Arborele are două entități, care sunt noduri de decizie și noduri de frunze.
Cuprins
Diferite entități ale arborelui decizional
1. Nod de decizie
Nodurile de decizie sunt cele în care datele se împart. Are de obicei două sau mai multe ramuri.
2. Nodurile frunzelor
Nodurile frunze reprezintă rezultatele, clasificarea sau deciziile evenimentului. Un arbore binar pentru „Eligibilitatea pentru concursul de frumusețe Miss India”:
Să luăm un exemplu de arbore binar simplu pentru a înțelege arborii de decizie. Să considerăm că doriți să aflați dacă o fată este eligibilă pentru un concurs de concurs de frumusețe precum Miss India.
Nodul de decizie pune mai întâi întrebarea dacă fata este rezidentă în India. Dacă da, are vârsta ei între 18 și 25 de ani? Dacă da, ea este eligibilă, altfel nu. Dacă nu, are certificate valabile? Dacă da, ea este eligibilă, altfel nu. Acesta a fost un simplu tip de problemă da sau nu. Arborele de decizie sunt clasificate în două tipuri principale:
Trebuie citit: Arborele de decizie în AI

Clasificarea arborelui de decizie
1. Arbori de clasificare
Arborele de clasificare sunt tipul simplu de arbori da sau nu. Este similar cu exemplul pe care l-am văzut mai sus, în care rezultatul a avut variabile precum „eligibil” sau „neeligibil”. Variabila de decizie aici este categorică.
2. Arbori de regresie
În arborii de regresie, variabila rezultat sau decizia este continuă, de exemplu, o literă precum ABC.
Acum că sunteți complet conștienți de arborele de decizie și de tipul acestuia, putem intra în profunzimea acestuia. Arborii de decizie pot fi construiți folosind mulți algoritmi; cu toate acestea, algoritmul ID3 sau Iterative Dichotomizer 3 este cel mai bun. Aici intervine entropia arborelui de decizie .
Algoritmul ID3 la fiecare iterație trece printr-un atribut neutilizat al setului și calculează Entropia H(e) sau IG(e) de câștig de informații. Deoarece suntem mai interesați să știm despre entropia arborelui de decizie în articolul curent, să înțelegem mai întâi termenul Entropie și să-l simplificăm cu un exemplu.
Entropie: Pentru o mulțime finită S, Entropia, numită și Entropia Shannon, este măsura cantității de aleatorie sau incertitudine a datelor. Este notat cu H(S).
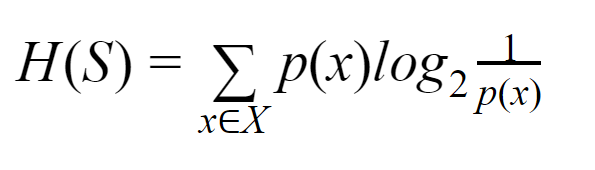
În termeni simpli, prezice un anumit eveniment prin măsurarea purității. Arborele de decizie este construit de sus în jos și începe cu un nod rădăcină. Datele acestui nod rădăcină sunt în continuare împărțite sau clasificate în subseturi care conțin instanțe omogene.
De exemplu, luați în considerare o farfurie folosită în cafenele cu „suntem deschisi” scris pe o parte și „suntem închise” pe cealaltă parte. Probabilitatea „suntem deschiși” este 0,5, iar probabilitatea „suntem închise” este de 0,5. Deoarece nu există nicio modalitate de a determina rezultatul în acest exemplu particular, entropia este cea mai mare posibilă.
Venind la același exemplu, dacă placa avea doar scris „noi suntem deschisi” pe ambele părți, atunci entropia poate fi prezisă foarte bine, deoarece știm deja că fie păstrând pe partea din față, fie pe partea din spate, încă mergem. a avea „noi suntem deschiși”. Cu alte cuvinte, nu are aleatorie, adică entropia este zero. Trebuie amintit că cu cât valoarea entropiei este mai mică, cu atât este mai mare puritatea evenimentului și cu cât valoarea entropiei este mai mare, cu atât puritatea evenimentului este mai mică.
Citiți: Clasificarea arborelui de decizie
Exemplu
Să considerăm că ai 110 bile. 89 dintre acestea sunt bile verzi, iar 21 sunt albastre. Calculați entropia pentru setul de date global.
Numărul total de bile (n) = 110

Deoarece avem 89 de bile verzi din 110, probabilitatea de verde ar fi 80,91% sau 89 împărțit la 110, ceea ce dă 0,8091. În plus, probabilitatea bilei verzi înmulțită cu logaritmul probabilității verzi dă 0,2473. Aici, trebuie amintit că un log de probabilitate va fi întotdeauna un număr negativ. Deci, trebuie să atașăm un semn negativ. Acest lucru poate fi exprimat simplu astfel:
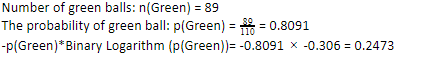
Acum, efectuând aceiași pași pentru bilele albastre, avem 21 din 110. Prin urmare, probabilitatea unei bile albastre este de 19,09% sau 21 împărțit la 110, ceea ce dă 0,1909. În plus, înmulțind probabilitatea bilelor albastre cu logaritmul probabilității bilei albastre, obținem 0,4561. Din nou, așa cum sa indicat mai sus, vom atașa un semn negativ, deoarece logaritmul probabilității dă întotdeauna un rezultat negativ, la care nu ne așteptăm. Exprimând acest lucru simplu:
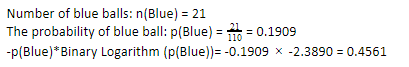
Acum, entropia arborelui de decizie a datelor generale este dată de suma entropiei individuale. Avem nevoie de suma produsului dintre probabilitatea bilei verzi și log al probabilității bilei verzi și produsul probabilității bilei albastre și log al probabilității bilei albastre.
Entropie (date generale) = 0,2473 + 0,4561 = 0,7034
Acesta a fost un exemplu pentru a vă ajuta să înțelegeți cum este calculată entropia. Sper că este destul de clar și aveți acest concept înțeles. Calcularea entropiei arborelui de decizie nu este știință rachetă ca atare.
Cu toate acestea, trebuie să fii pasionat în timp ce faci calculele. Fiind pe această pagină, este evident că ești un pasionat de învățare automată și, prin urmare, trebuie să știi cât de important este rolul fiecărui detaliu minut. Chiar și cea mai mică greșeală poate cauza probleme și, prin urmare, ar trebui să aveți întotdeauna calcule adecvate.
Checkout: Tipuri de arbore binar
Concluzie
Un arbore de decizie este învățarea automată supravegheată care utilizează diverși algoritmi pentru a construi arborele de decizie. Printre diferiți algoritmi, algoritmul ID3 folosește Entropia. Entropia nu este altceva decât măsura purității evenimentului.
Știm că o carieră în învățarea automată are un viitor promițător și o carieră înfloritoare. Această industrie are încă un drum lung pentru a atinge apogeul și, prin urmare, oportunitățile pentru pasionații de învățare automată cresc exponențial cu o mulțime de alte avantaje. Faceți-vă un loc remarcabil în industria învățării automate cu ajutorul cunoștințelor și abilităților potrivite.
Dacă sunteți interesat să aflați mai multe despre învățarea automată, consultați Diploma PG de la IIIT-B și upGrad în Învățare automată și AI, care este concepută pentru profesioniști care lucrează și oferă peste 450 de ore de pregătire riguroasă, peste 30 de studii de caz și sarcini, IIIT- B Statut de absolvenți, peste 5 proiecte practice practice și asistență pentru locuri de muncă cu firme de top.
Care este diferența dintre Entropie și Impuritatea Gini?
Algoritmii arborelui de decizie sunt metode de clasificare utilizate pentru a prezice soluții posibile și fiabile. Entropia este calculată într-un arbore de decizie pentru ao optimiza. Aceste subseturi care completează caracteristicile Arborelui de decizie sunt alese pentru a obține o puritate mai mare prin calcularea Entropiei. Determină puritatea componentei din subgrup și împarte intrarea în consecință. Entropia este cuprinsă între 0 și 1. Gini măsoară și impuritatea datelor pentru a selecta cea mai potrivită împărțire. Indicele Gini sau Impuritatea Gini măsoară dacă o diviziune este incorectă în ceea ce privește caracteristicile sale. În mod ideal, toate diviziunile ar trebui să aibă aceeași clasificare pentru a obține puritatea.
Ce este câștigul de informații în arbori de decizie?
Arborele de decizie implică o mulțime de împărțire pentru a obține puritatea în subseturi. Când puritatea este cea mai mare, predicția deciziei este cea mai puternică. Câștigul de informații este un proces de calcul continuu de măsurare a impurităților la fiecare subset înainte de a împărți datele în continuare. Câștigul de informații folosește Entropia pentru a determina această puritate. La fiecare subgrup, raportul dintre diferitele variabile din subseturi determină cantitatea de informații necesare pentru a alege subsetul pentru a se împărți în continuare. Câștigul de informații va fi mai echilibrat în proporția de variabile din subset, promițând mai multă puritate.
Care sunt dezavantajele unui arbore de decizie?
Algoritmul Decision Tree este cel mai utilizat mecanism de învățare automată pentru luarea deciziilor. Analog cu un arbore, folosește noduri pentru a clasifica datele în subseturi până când este luată cea mai potrivită decizie. Arborele de decizie ajută la prezicerea soluțiilor de succes. Cu toate acestea, au și limitările lor. Arborii de decizie excesiv de giganți sunt greu de urmărit și perceput; acest lucru se poate datora foarte bine supraadaptării datelor. Dacă setul de date este modificat în vreun fel, vor urma repercusiuni în decizia finală. Prin urmare, arborii de decizie ar putea fi complexi, dar pot fi executați în mod corespunzător cu antrenament.