
Zrozumienie entropii drzewa decyzyjnego w uczeniu maszynowym
Opublikowany: 2020-12-29Drzewo decyzyjne to część nadzorowanego uczenia maszynowego, w której wyjaśniasz dane wejściowe, dla których dane wyjściowe znajdują się w danych uczących. W drzewach decyzyjnych dane są dzielone wielokrotnie zgodnie z podanymi parametrami. Ciągle dzieli dane na mniejsze podzbiory, a jednocześnie drzewo rozwija się przyrostowo. Drzewo ma dwie jednostki, którymi są węzły decyzyjne i węzły liści.
Spis treści
Różne jednostki drzewa decyzyjnego
1. Węzeł decyzyjny
Węzły decyzyjne to te, w których następuje podział danych. Zwykle ma dwie lub więcej gałęzi.
2. Węzły liściowe
Węzły liści reprezentują wyniki, klasyfikację lub decyzje dotyczące zdarzenia. Drzewo binarne dla „Kwalifikacji do konkursu Miss India Beauty”:
Weźmy przykład prostego drzewa binarnego, aby zrozumieć drzewa decyzyjne. Zastanówmy się, czy chcesz dowiedzieć się, czy dziewczyna kwalifikuje się do konkursu piękności, takiego jak Miss India.
Węzeł decyzyjny najpierw zadaje pytanie, czy dziewczyna jest mieszkanką Indii. Jeśli tak, to czy ma od 18 do 25 lat? Jeśli tak, kwalifikuje się, w przeciwnym razie nie. Jeśli nie, czy ma ważne certyfikaty? Jeśli tak, kwalifikuje się, w przeciwnym razie nie. Był to prosty problem typu tak lub nie. Drzewa decyzyjne dzielą się na dwa główne typy:
Trzeba przeczytać: drzewo decyzyjne w AI

Klasyfikacja drzewa decyzyjnego
1. Drzewa klasyfikacyjne
Drzewa klasyfikacyjne to proste drzewa typu tak lub nie. Jest to podobne do przykładu, który widzieliśmy powyżej, gdzie wynik zawierał zmienne, takie jak „odpowiedni” lub „nie kwalifikujący się”. Zmienna decyzyjna jest tutaj kategoryczna.
2. Drzewa regresji
W drzewach regresji zmienna wynikowa lub decyzja jest ciągła, np. litera typu ABC.
Teraz, gdy jesteś w pełni świadomy drzewa decyzyjnego i jego rodzaju, możemy zagłębić się w jego głębię. Drzewa decyzyjne można konstruować przy użyciu wielu algorytmów; jednak najlepszy jest algorytm ID3 lub Iterative Dichotomiser 3. Tutaj pojawia się entropia drzewa decyzyjnego .
Algorytm ID3 w każdej iteracji przechodzi przez niewykorzystany atrybut zbioru i oblicza Entropy H(s) lub Information Gain IG(s). Ponieważ w tym artykule bardziej interesuje nas wiedza o entropii drzewa decyzyjnego , najpierw zrozummy termin Entropia i uprośćmy go za pomocą przykładu.
Entropia: Dla skończonego zbioru S, Entropia, zwana również Entropią Shannona, jest miarą ilości losowości lub niepewności danych. Jest oznaczony przez H(S).
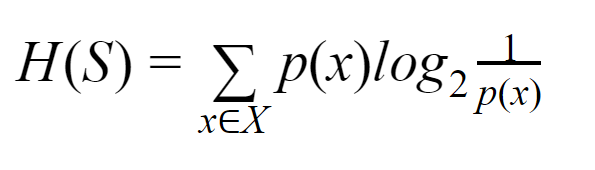
Mówiąc prościej, przewiduje pewne wydarzenie, mierząc czystość. Drzewo decyzyjne jest budowane odgórnie i zaczyna się od węzła głównego. Dane tego węzła głównego są dalej dzielone na partycje lub klasyfikowane w podzbiory, które zawierają jednorodne instancje.
Rozważmy na przykład tabliczkę używaną w kawiarniach, na której po jednej stronie napisane jest „jesteśmy otwarci”, a po drugiej „jesteśmy zamknięci”. Prawdopodobieństwo „jesteśmy otwarci” wynosi 0,5, a prawdopodobieństwo „jesteśmy zamknięci” wynosi 0,5. Ponieważ nie ma możliwości określenia wyniku w tym konkretnym przykładzie, entropia jest najwyższa z możliwych.
Wracając do tego samego przykładu, gdyby tabliczka miała tylko napis „jesteśmy otwarci” po obu jej stronach, to entropię można bardzo dobrze przewidzieć, ponieważ wiemy już, że albo trzymając na awersie, albo na rewersie, nadal jedziemy mieć „jesteśmy otwarci”. Innymi słowy, nie ma losowości, co oznacza, że entropia wynosi zero. Należy pamiętać, że im niższa wartość entropii, tym wyższa czystość zdarzenia, a im wyższa wartość entropii, tym niższa czystość zdarzenia.
Przeczytaj: Klasyfikacja drzewa decyzyjnego
Przykład
Załóżmy, że masz 110 piłek. 89 z nich to kule zielone, a 21 to niebieskie. Oblicz entropię dla całego zbioru danych.
Całkowita liczba kulek (n) = 110
Ponieważ mamy 89 zielonych piłek na 110, prawdopodobieństwo zielonego wyniosłoby 80,91% lub 89 podzielone przez 110, co daje 0,8091. Co więcej, prawdopodobieństwo zielonej kuli pomnożone przez logarytm prawdopodobieństwa zielonej kuli daje 0,2473. Należy tutaj pamiętać, że log prawdopodobieństwa zawsze będzie liczbą ujemną. Więc musimy dołączyć znak ujemny. Można to wyrazić po prostu jako:

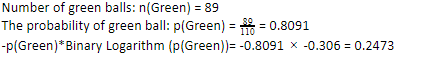
Teraz, wykonując te same kroki dla niebieskich kulek, mamy 21 na 110. Stąd prawdopodobieństwo niebieskiej kuli wynosi 19,09% lub 21 podzielone przez 110, co daje 0,1909. Dalej, mnożąc prawdopodobieństwo niebieskich kulek przez logarytm prawdopodobieństwa niebieskiej kuli, otrzymujemy 0,4561. Ponownie, zgodnie z instrukcją powyżej, dołączymy znak ujemny, ponieważ logarytm prawdopodobieństwa zawsze daje wynik ujemny, czego się nie spodziewamy. Wyrażając to po prostu:
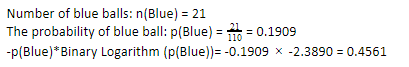
Teraz Entropia Drzewa Decyzyjnego wszystkich danych jest dana przez sumę indywidualnej entropii. Potrzebujemy sumy iloczynu prawdopodobieństwa zielonej kuli i log prawdopodobieństwa zielonej kuli oraz iloczynu prawdopodobieństwa niebieskiej kuli i log prawdopodobieństwa niebieskiej kuli.
Entropia (dane ogólne)= 0,2473 + 0,4561 =0,7034
To był jeden przykład, który pomógł ci zrozumieć, w jaki sposób obliczana jest entropia. Mam nadzieję, że jest to całkiem jasne i zrozumiałeś tę koncepcję. Obliczanie entropii drzewa decyzyjnego nie jest samo w sobie nauką o rakietach.
Musisz jednak być ostrożny podczas wykonywania obliczeń. Będąc na tej stronie, oczywiste jest, że jesteś entuzjastą uczenia maszynowego, dlatego oczekuje się od Ciebie, że będziesz wiedział, jak ważna jest rola każdego najmniejszego szczegółu. Nawet najmniejszy błąd może sprawić kłopoty, dlatego zawsze powinieneś mieć odpowiednie obliczenia.
Zamówienie: rodzaje drzewa binarnego
Dolna linia
Drzewo decyzyjne to nadzorowane uczenie maszynowe, które wykorzystuje różne algorytmy do budowy drzewa decyzyjnego. Wśród różnych algorytmów algorytm ID3 wykorzystuje Entropię. Entropia to nic innego jak miara czystości wydarzenia.
Wiemy, że kariera w uczeniu maszynowym ma obiecującą przyszłość i kwitnącą karierę. Ta branża ma jeszcze długą drogę do osiągnięcia swojego szczytu, dlatego możliwości dla entuzjastów uczenia maszynowego rosną wykładniczo z wieloma innymi zaletami. Zbuduj swoje wyjątkowe miejsce w branży uczenia maszynowego dzięki odpowiedniej wiedzy i umiejętnościom.
Jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, sprawdź dyplom PG IIIT-B i upGrad w uczeniu maszynowym i sztucznej inteligencji, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznego szkolenia, ponad 30 studiów przypadków i zadań, IIIT- Status absolwenta B, ponad 5 praktycznych, praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Jaka jest różnica między Entropią a Nieczystością Giniego?
Algorytmy drzew decyzyjnych to metody klasyfikacji stosowane do przewidywania możliwych, niezawodnych rozwiązań. Entropia jest obliczana w drzewie decyzyjnym w celu jej optymalizacji. Te podzbiory, które uzupełniają cechy drzewa decyzyjnego, są wybierane w celu osiągnięcia większej czystości poprzez obliczenie Entropii. Określa czystość składnika w podgrupie i odpowiednio dzieli dane wejściowe. Entropia mieści się w zakresie od 0 do 1. Gini mierzy również zanieczyszczenie danych, aby wybrać najbardziej odpowiedni podział. Gini Index lub Gini Impurity mierzy, czy podział jest nieprawidłowy pod względem jego cech. W idealnym przypadku wszystkie podziały powinny mieć tę samą klasyfikację, aby osiągnąć czystość.
Co to jest zdobywanie informacji w drzewach decyzyjnych?
Drzewa decyzyjne wymagają wielu podziałów w celu osiągnięcia czystości w podzbiorach. Kiedy czystość jest najwyższa, przewidywanie decyzji jest najsilniejsze. Zysk informacji to ciągły proces obliczeniowy pomiaru zanieczyszczenia w każdym podzbiorze przed dalszym podziałem danych. Zysk informacji wykorzystuje Entropy do określenia tej czystości. W każdej podgrupie stosunek różnych zmiennych w podzbiorach określa ilość informacji wymaganych do wybrania podzbioru do dalszego podziału. Zysk informacji będzie bardziej zrównoważony w proporcji zmiennych w podzbiorze, obiecując większą czystość.
Jakie są wady drzewa decyzyjnego?
Algorytm drzewa decyzyjnego jest najczęściej używanym mechanizmem uczenia maszynowego do podejmowania decyzji. Analogicznie do drzewa, wykorzystuje węzły do klasyfikacji danych na podzbiory, dopóki nie zostanie podjęta najwłaściwsza decyzja. Drzewa decyzyjne pomagają przewidzieć skuteczne rozwiązania. Jednak mają też swoje ograniczenia. Nadmiernie gigantyczne drzewa decyzyjne są trudne do naśladowania i postrzegania; może to być bardzo dobrze spowodowane nadmiernym dopasowaniem danych. Jeśli zestaw danych zostanie w jakikolwiek sposób zmodyfikowany, nastąpią reperkusje w ostatecznej decyzji. Dlatego drzewa decyzyjne mogą być złożone, ale można je odpowiednio wykonać podczas szkolenia.