
Verständnis der Entropie des Entscheidungsbaums beim maschinellen Lernen
Veröffentlicht: 2020-12-29Der Entscheidungsbaum ist ein Teil des überwachten maschinellen Lernens, in dem Sie die Eingabe erklären, für die die Ausgabe in den Trainingsdaten enthalten ist. In Entscheidungsbäumen werden Daten gemäß den angegebenen Parametern mehrfach aufgeteilt. Es zerlegt die Daten immer wieder in kleinere Teilmengen, und gleichzeitig wird der Baum schrittweise entwickelt. Der Baum hat zwei Entitäten, die Entscheidungsknoten und Blattknoten sind.
Inhaltsverzeichnis
Verschiedene Entitäten des Entscheidungsbaums
1. Entscheidungsknoten
Die Entscheidungsknoten sind diejenigen, an denen die Daten aufgeteilt werden. Es hat normalerweise zwei oder mehr Zweige.
2. Blattknoten
Die Blattknoten stellen die Ergebnisse, Klassifizierungen oder Entscheidungen des Ereignisses dar. Ein binärer Baum für „Eligibility for Miss India Beauty Pageant“:
Nehmen wir ein Beispiel eines einfachen Binärbaums, um die Entscheidungsbäume zu verstehen. Nehmen wir an, Sie möchten herausfinden, ob ein Mädchen für einen Schönheitswettbewerb wie Miss India in Frage kommt.
Der Entscheidungsknoten stellt zunächst die Frage, ob das Mädchen in Indien ansässig ist. Wenn ja, ist sie zwischen 18 und 25 Jahre alt? Wenn ja, ist sie berechtigt, sonst nicht. Wenn nein, hat sie gültige Zertifikate? Wenn ja, ist sie berechtigt, sonst nicht. Dies war ein einfaches Ja-oder-Nein-Problem. Die Entscheidungsbäume werden in zwei Haupttypen eingeteilt:
Muss gelesen werden: Entscheidungsbaum in der KI

Entscheidungsbaumklassifizierung
1. Klassifikationsbäume
Die Klassifizierungsbäume sind die einfache Ja- oder Nein-Art von Bäumen. Es ähnelt dem Beispiel, das wir oben gesehen haben, wo das Ergebnis Variablen wie „berechtigt“ oder „nicht berechtigt“ hatte. Die Entscheidungsvariable ist hier kategorisch.
2. Regressionsbäume
In Regressionsbäumen ist die Ergebnisvariable oder die Entscheidung stetig, z. B. ein Buchstabe wie ABC.
Jetzt, da Sie sich des Entscheidungsbaums und seines Typs vollständig bewusst sind, können wir ihm auf den Grund gehen. Entscheidungsbäume können mit vielen Algorithmen konstruiert werden; ID3 oder Iterative Dichotomiser 3 Algorithm ist jedoch der beste. Hier kommt die Entropie des Entscheidungsbaums ins Spiel.
Der ID3-Algorithmus geht bei jeder Iteration durch ein unbenutztes Attribut des Satzes und berechnet die Entropie H(s) oder den Informationsgewinn IG(s). Da wir im aktuellen Artikel mehr daran interessiert sind, etwas über die Entscheidungsbaumentropie zu erfahren , lassen Sie uns zunächst den Begriff Entropie verstehen und mit einem Beispiel vereinfachen.
Entropie: Für eine endliche Menge S ist die Entropie, auch Shannon-Entropie genannt, das Maß für die Zufälligkeit oder Unsicherheit in den Daten. Es wird mit H(S) bezeichnet.
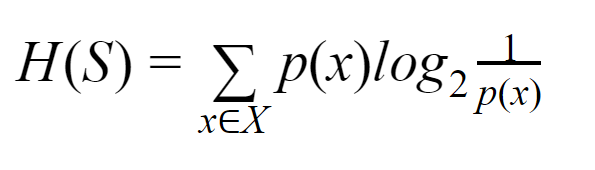
Einfach ausgedrückt sagt es ein bestimmtes Ereignis voraus, indem es die Reinheit misst. Der Entscheidungsbaum wird von oben nach unten aufgebaut und beginnt mit einem Wurzelknoten. Die Daten dieses Wurzelknotens werden weiter partitioniert oder in Teilmengen klassifiziert, die homogene Instanzen enthalten.
Stellen Sie sich zum Beispiel einen Teller vor, der in Cafés verwendet wird und auf dessen einer Seite „Wir haben geöffnet“ und auf der anderen Seite „Wir haben geschlossen“ geschrieben steht. Die Wahrscheinlichkeit für „wir sind offen“ beträgt 0,5 und die Wahrscheinlichkeit für „wir sind geschlossen“ beträgt 0,5. Da es in diesem speziellen Beispiel keine Möglichkeit gibt, das Ergebnis zu bestimmen, ist die Entropie die höchstmögliche.
Um zum gleichen Beispiel zu kommen, wenn die Platte nur auf beiden Seiten mit „Wir sind offen“ beschriftet wäre, dann kann die Entropie sehr gut vorhergesagt werden, da wir bereits wissen, dass wir entweder auf der Vorder- oder auf der Rückseite bleiben, wir gehen immer noch um „wir sind offen“ zu haben. Mit anderen Worten, es hat keine Zufälligkeit, was bedeutet, dass die Entropie null ist. Es sollte daran erinnert werden, dass je niedriger der Entropiewert, desto höher die Reinheit des Ereignisses, und je höher der Entropiewert, desto niedriger die Reinheit des Ereignisses.
Lesen Sie: Entscheidungsbaum-Klassifizierung
Beispiel
Nehmen wir an, Sie haben 110 Bälle. Davon sind 89 grüne Kugeln und 21 blaue. Berechnen Sie die Entropie für den gesamten Datensatz.
Gesamtzahl der Bälle (n) = 110
Da wir 89 grüne Kugeln von 110 haben, wäre die Wahrscheinlichkeit für grüne 80,91 % oder 89 geteilt durch 110, was 0,8091 ergibt. Ferner ergibt die Multiplikation der Wahrscheinlichkeit des grünen Balls mit dem Log der Wahrscheinlichkeit des grünen Balls 0,2473. Hierbei ist zu beachten, dass ein Log der Wahrscheinlichkeit immer eine negative Zahl sein wird. Wir müssen also ein negatives Vorzeichen anhängen. Dies kann einfach ausgedrückt werden als:

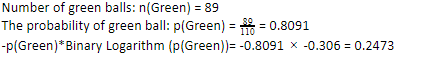
Wenn wir nun die gleichen Schritte für die blauen Kugeln ausführen, haben wir 21 von 110. Daher beträgt die Wahrscheinlichkeit einer blauen Kugel 19,09 % oder 21 geteilt durch 110, was 0,1909 ergibt. Wenn wir außerdem die Wahrscheinlichkeit der blauen Kugeln mit dem Logarithmus der Wahrscheinlichkeit der blauen Kugel multiplizieren, erhalten wir 0,4561. Auch hier werden wir, wie oben beschrieben, ein negatives Vorzeichen anbringen, da der Logarithmus der Wahrscheinlichkeit immer ein negatives Ergebnis liefert, was wir nicht erwarten. Einfach ausgedrückt:
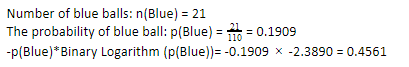
Nun ist die Entscheidungsbaum- Entropie y der Gesamtdaten durch die Summe der einzelnen Entropie gegeben. Wir brauchen die Summe aus dem Produkt der Wahrscheinlichkeit des grünen Balls und dem Logarithmus der Wahrscheinlichkeit des grünen Balls und dem Produkt der Wahrscheinlichkeit des blauen Balls und dem Logarithmus der Wahrscheinlichkeit des blauen Balls.
Entropie (Gesamtdaten) = 0,2473 + 0,4561 = 0,7034
Dies war ein Beispiel, um Ihnen zu helfen zu verstehen, wie die Entropie berechnet wird. Hoffentlich ist es ziemlich klar und Sie haben dieses Konzept verstanden. Die Berechnung der Entscheidungsbaumentropie ist keine Raketenwissenschaft an sich.
Beim Rechnen muss man allerdings scharf sein. Wenn Sie sich auf dieser Seite befinden, ist es offensichtlich, dass Sie ein Enthusiast des maschinellen Lernens sind, und daher wird von Ihnen erwartet, dass Sie wissen, wie wichtig jedes kleinste Detail ist. Selbst der kleinste Fehler kann Probleme verursachen, und daher sollten Sie immer über korrekte Berechnungen verfügen.
Checkout: Arten von Binärbäumen
Endeffekt
Ein Entscheidungsbaum ist überwachtes maschinelles Lernen, das verschiedene Algorithmen verwendet, um den Entscheidungsbaum zu erstellen. Unter verschiedenen Algorithmen verwendet der ID3-Algorithmus Entropie. Entropie ist nichts anderes als das Maß für die Reinheit des Geschehens.
Wir wissen, dass eine Karriere im maschinellen Lernen eine vielversprechende Zukunft und eine blühende Karriere hat. Diese Branche hat noch einen langen Weg vor sich, um ihren Höhepunkt zu erreichen, und daher wachsen die Möglichkeiten für Enthusiasten des maschinellen Lernens exponentiell mit vielen anderen Vorteilen. Machen Sie sich mit Hilfe der richtigen Kenntnisse und Fähigkeiten einen bemerkenswerten Platz in der Branche des maschinellen Lernens.
Wenn Sie mehr über maschinelles Lernen erfahren möchten, sehen Sie sich das PG-Diplom in maschinellem Lernen und KI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben bietet, IIIT- B-Alumni-Status, mehr als 5 praktische, praktische Abschlussprojekte und Jobunterstützung bei Top-Unternehmen.
Was ist der Unterschied zwischen Entropie und Gini-Verunreinigung?
Entscheidungsbaumalgorithmen sind Klassifikationsverfahren, die verwendet werden, um mögliche, zuverlässige Lösungen vorherzusagen. Die Entropie wird in einem Entscheidungsbaum berechnet, um sie zu optimieren. Diese Teilmengen, die die Merkmale des Entscheidungsbaums ergänzen, werden ausgewählt, um durch die Berechnung der Entropie eine größere Reinheit zu erreichen. Es bestimmt die Reinheit der Komponente in der Untergruppe und teilt den Input entsprechend auf. Die Entropie liegt zwischen 0 und 1. Gini misst auch die Verunreinigung der Daten, um die am besten geeignete Aufteilung auszuwählen. Gini Index oder Gini Impurity misst, ob eine Teilung bezüglich ihrer Eigenschaften falsch ist. Idealerweise sollten alle Splits die gleiche Klassifizierung haben, um Reinheit zu erreichen.
Was ist Informationsgewinn in Entscheidungsbäumen?
Entscheidungsbäume beinhalten viel Aufspaltung, um Reinheit in den Teilmengen zu erreichen. Wenn die Reinheit am höchsten ist, ist die Vorhersage der Entscheidung am stärksten. Der Informationsgewinn ist ein kontinuierlicher rechnerischer Prozess der Messung der Verunreinigung an jeder Teilmenge, bevor die Daten weiter aufgeteilt werden. Informationsgewinn verwendet Entropie, um diese Reinheit zu bestimmen. Bei jeder Untergruppe bestimmt das Verhältnis verschiedener Variablen in den Untergruppen die Informationsmenge, die erforderlich ist, um die Untergruppe für die weitere Aufteilung auszuwählen. Der Informationsgewinn wird im Verhältnis der Variablen in der Teilmenge ausgewogener sein, was mehr Reinheit verspricht.
Was sind die Nachteile eines Entscheidungsbaums?
Der Entscheidungsbaum-Algorithmus ist der am weitesten verbreitete maschinelle Lernmechanismus für die Entscheidungsfindung. Analog zu einem Baum verwendet es Knoten, um Daten in Teilmengen zu klassifizieren, bis die am besten geeignete Entscheidung getroffen wird. Entscheidungsbäume helfen, erfolgreiche Lösungen vorherzusagen. Allerdings haben sie auch ihre Grenzen. Übermäßig riesige Entscheidungsbäume sind schwer zu verfolgen und wahrzunehmen; Dies kann sehr wohl auf eine Überanpassung der Daten zurückzuführen sein. Wenn der Datensatz in irgendeiner Weise optimiert wird, wird dies Auswirkungen auf die endgültige Entscheidung haben. Daher können Entscheidungsbäume komplex sein, können aber mit Training angemessen ausgeführt werden.