
Comprendere l'entropia dell'albero decisionale nell'apprendimento automatico
Pubblicato: 2020-12-29Decision Tree fa parte di Supervised Machine Learning in cui spieghi l'input per cui l'output è nei dati di addestramento. Negli alberi decisionali, i dati vengono suddivisi più volte in base ai parametri specificati. Continua a suddividere i dati in sottoinsiemi più piccoli e, contemporaneamente, l'albero viene sviluppato in modo incrementale. L'albero ha due entità, che sono nodi decisionali e nodi foglia.
Sommario
Diverse entità dell'albero decisionale
1. Nodo decisionale
I nodi decisionali sono quelli in cui i dati si dividono. Di solito ha due o più rami.
2. Nodi fogliari
I nodi foglia rappresentano i risultati, la classificazione o le decisioni dell'evento. Un albero binario per "Idoneità al concorso di bellezza Miss India":
Prendiamo un esempio di un semplice albero binario per comprendere gli alberi decisionali. Consideriamo che vuoi scoprire se una ragazza è idonea a un concorso di bellezza come Miss India.
Il nodo decisionale prima pone la domanda se la ragazza è residente in India. Se sì, la sua età è compresa tra 18 e 25 anni? Se sì, è idonea, altrimenti no. Se no, ha certificati validi? Se sì, è idonea, altrimenti no. Questo era un semplice tipo di problema sì o no. Gli alberi decisionali sono classificati in due tipi principali:
Deve leggere: Decision Tree in AI

Classificazione dell'albero decisionale
1. Alberi di classificazione
Gli alberi di classificazione sono i semplici tipi di alberi sì o no. È simile all'esempio che abbiamo visto sopra, in cui il risultato aveva variabili come "idoneo" o "non idoneo". La variabile di decisione qui è Categoriale.
2. Alberi di regressione
Negli alberi di regressione, la variabile di risultato o la decisione è continua, ad esempio una lettera come ABC.
Ora che sei completamente consapevole dell'albero decisionale e del suo tipo, possiamo entrare nel profondo di esso. Gli alberi decisionali possono essere costruiti utilizzando molti algoritmi; tuttavia, ID3 o Iterative Dichotomiser 3 Algorithm è il migliore. È qui che entra in gioco l' entropia dell'albero decisionale .
L'algoritmo ID3 ad ogni iterazione passa attraverso un attributo inutilizzato dell'insieme e calcola l'Entropy H(s) o Information Gain IG(s). Poiché in questo articolo siamo più interessati a conoscere l'entropia dell'albero decisionale , prima comprendiamo il termine Entropia e semplifichiamolo con un esempio.
Entropia: per un insieme finito S, l'entropia, chiamata anche entropia di Shannon, è la misura della quantità di casualità o incertezza nei dati. È indicato con H(S).
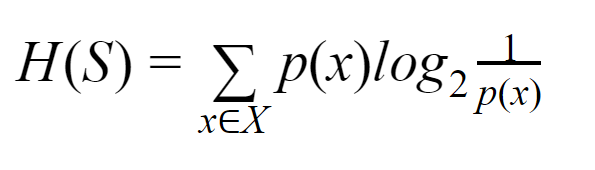
In parole povere, prevede un certo evento misurandone la purezza. L'albero decisionale è costruito in modo top-down e inizia con un nodo radice. I dati di questo nodo radice vengono ulteriormente partizionati o classificati in sottoinsiemi che contengono istanze omogenee.
Si consideri, ad esempio, un piatto usato nei bar con la scritta "siamo aperti" da un lato e "siamo chiusi" dall'altro lato. La probabilità di "siamo aperti" è 0,5 e la probabilità di "siamo chiusi" è 0,5. Poiché non c'è modo di determinare il risultato in questo particolare esempio, l'entropia è la più alta possibile.
Venendo allo stesso esempio, se il piatto avesse scritto solo "siamo aperti" su entrambi i lati, allora l'entropia può essere prevista molto bene poiché sappiamo già che tenendo sul lato anteriore o sul lato posteriore, stiamo ancora andando avere "siamo aperti". In altre parole, non ha casualità, il che significa che l'entropia è zero. Va ricordato che minore è il valore dell'entropia, maggiore è la purezza dell'evento e maggiore è il valore dell'entropia, minore è la purezza dell'evento.
Leggi: Classificazione dell'albero decisionale
Esempio
Consideriamo che hai 110 palline. 89 di queste sono palline verdi e 21 blu. Calcola l'entropia per il set di dati complessivo.
Numero totale di palline (n) = 110
Dato che abbiamo 89 palline verdi su 110, la probabilità che il verde sia 80,91% o 89 diviso per 110, che dà 0,8091. Inoltre, la probabilità della pallina verde moltiplicata per il log della probabilità della pallina verde dà 0,2473. Qui, va ricordato che un log di probabilità sarà sempre un numero negativo. Quindi, dobbiamo allegare un segno negativo. Questo può essere espresso semplicemente come:

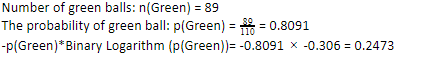
Ora, eseguendo gli stessi passaggi per le palline blu, abbiamo 21 su 110. Quindi, la probabilità di una pallina blu è 19,09% o 21 diviso per 110, che dà 0,1909. Inoltre, moltiplicando la probabilità delle palline blu per il log della probabilità della pallina blu, otteniamo 0,4561. Ancora una volta, come indicato sopra, allegheremo un segno negativo poiché il log della probabilità dà sempre un risultato negativo, che non ci aspettiamo. Esprimendo questo semplicemente:
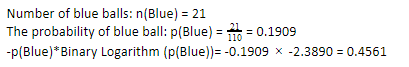
Ora, l' entropia dell'albero decisionale dei dati complessivi è data dalla somma dell'entropia individuale. Abbiamo bisogno della somma del prodotto della probabilità della pallina verde e del log della probabilità della pallina verde e del prodotto della probabilità della pallina blu e del log della probabilità della pallina blu.
Entropia (dati complessivi)= 0,2473 + 0,4561 = 0,7034
Questo è stato un esempio per aiutarti a capire come viene calcolata l'entropia. Si spera che sia abbastanza chiaro e che tu abbia capito questo concetto. Calcolare l' entropia dell'albero decisionale non è scienza missilistica in quanto tale.
Tuttavia, devi essere appassionato mentre fai i calcoli. Essendo su questa pagina, è ovvio che sei un appassionato di apprendimento automatico e, quindi, dovresti sapere quanto sia importante il ruolo di ogni minimo dettaglio. Anche il più piccolo errore può causare problemi e, quindi, dovresti sempre avere calcoli corretti.
Checkout: tipi di albero binario
Linea di fondo
Un albero decisionale è un apprendimento automatico supervisionato che utilizza vari algoritmi per costruire l'albero decisionale. Tra i diversi algoritmi, l'algoritmo ID3 utilizza Entropy. L'entropia non è altro che la misura della purezza dell'evento.
Sappiamo che una carriera nell'apprendimento automatico ha un futuro promettente e una carriera fiorente. Questo settore ha ancora molta strada da fare per raggiungere il suo apice, e quindi le opportunità per gli appassionati di machine learning stanno crescendo esponenzialmente con molti altri vantaggi. Fai il tuo posto straordinario nel settore dell'apprendimento automatico con l'aiuto delle giuste conoscenze e abilità.
Se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al Diploma PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, IIIT- B Status di Alumni, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
Qual è la differenza tra Entropy e Gini Impurity?
Gli algoritmi dell'albero decisionale sono metodi di classificazione utilizzati per prevedere soluzioni possibili e affidabili. L'entropia viene calcolata in un albero decisionale per ottimizzarla. Questi sottoinsiemi che completano le caratteristiche dell'albero decisionale vengono scelti per ottenere una maggiore purezza calcolando l'entropia. Determina la purezza del componente nel sottogruppo e divide l'input di conseguenza. L'entropia è compresa tra 0 e 1. Gini misura anche l'impurità dei dati per selezionare la divisione più appropriata. Gini Index o Gini Impurity misura se una divisione è errata riguardo alle sue caratteristiche. Idealmente, tutte le divisioni dovrebbero avere la stessa classificazione per ottenere la purezza.
Che cos'è il guadagno di informazioni negli alberi decisionali?
Gli alberi decisionali comportano molte suddivisioni per ottenere la purezza nei sottoinsiemi. Quando la purezza è massima, la previsione della decisione è la più forte. Il guadagno di informazioni è un processo di calcolo continuo per misurare l'impurità in ogni sottoinsieme prima di suddividere ulteriormente i dati. Il guadagno di informazioni utilizza Entropy per determinare questa purezza. In ciascun sottogruppo, il rapporto tra le varie variabili nei sottoinsiemi determina la quantità di informazioni necessarie per scegliere il sottoinsieme da suddividere ulteriormente. Il guadagno di informazioni sarà più equilibrato nella proporzione delle variabili nel sottoinsieme, promettendo una maggiore purezza.
Quali sono gli svantaggi di un albero decisionale?
L'algoritmo Decision Tree è il meccanismo di apprendimento automatico più utilizzato per il processo decisionale. Analogamente a un albero, utilizza i nodi per classificare i dati in sottoinsiemi fino a quando non viene presa la decisione più appropriata. Gli alberi decisionali aiutano a prevedere soluzioni di successo. Tuttavia, hanno anche i loro limiti. Gli alberi decisionali eccessivamente giganti sono difficili da seguire e percepire; questo può benissimo essere dovuto all'overfitting dei dati. Se il set di dati viene modificato in qualsiasi modo, seguiranno le ripercussioni nella decisione finale. Pertanto, gli alberi decisionali potrebbero essere complessi ma possono essere eseguiti in modo appropriato con la formazione.