
Memahami Entropi Pohon Keputusan dalam Pembelajaran Mesin
Diterbitkan: 2020-12-29Pohon Keputusan adalah bagian dari Pembelajaran Mesin Terawasi di mana Anda menjelaskan input yang outputnya ada dalam data pelatihan. Di pohon Keputusan, data dibagi beberapa kali sesuai dengan parameter yang diberikan. Itu terus memecah data menjadi himpunan bagian yang lebih kecil, dan secara bersamaan, pohon dikembangkan secara bertahap. Pohon memiliki dua entitas, yaitu simpul keputusan dan simpul daun.
Daftar isi
Entitas yang berbeda dari Pohon Keputusan
1. Simpul Keputusan
Node keputusan adalah node di mana data terbelah. Biasanya memiliki dua atau lebih cabang.
2. Node Daun
Node daun mewakili hasil, klasifikasi, atau keputusan acara. Pohon biner untuk "Kelayakan untuk Kontes Kecantikan Miss India":
Mari kita ambil contoh pohon biner sederhana untuk memahami pohon keputusan. Mari kita pertimbangkan bahwa Anda ingin mengetahui apakah seorang gadis memenuhi syarat untuk kontes kontes kecantikan seperti Miss India.
Simpul keputusan pertama-tama mengajukan pertanyaan apakah gadis itu adalah penduduk India. Jika ya, apakah usianya antara 18 sampai 25 tahun? Jika ya, dia memenuhi syarat, jika tidak. Jika tidak, apakah dia memiliki sertifikat yang valid? Jika ya, dia memenuhi syarat, jika tidak. Ini adalah jenis masalah ya atau tidak yang sederhana. Pohon keputusan diklasifikasikan menjadi dua jenis utama:
Harus Dibaca: Pohon Keputusan di AI

Klasifikasi Pohon Keputusan
1. Pohon Klasifikasi
Pohon klasifikasi adalah jenis pohon ya atau tidak yang sederhana. Hal ini mirip dengan contoh yang telah kita lihat di atas, di mana hasilnya memiliki variabel seperti 'memenuhi syarat' atau 'tidak memenuhi syarat.' Variabel keputusan di sini adalah Kategoris.
2. Pohon Regresi
Dalam pohon regresi, variabel hasil atau keputusan adalah kontinu, misalnya huruf seperti ABC.
Sekarang setelah Anda benar-benar mengetahui pohon keputusan dan jenisnya, kita bisa masuk ke dalamnya. Pohon keputusan dapat dibangun menggunakan banyak algoritma; namun, Algoritma ID3 atau Iterative Dichotomiser 3 adalah yang terbaik. Di sinilah entropi pohon keputusan masuk ke dalam bingkai.
Algoritma ID3 pada setiap iterasi melewati atribut yang tidak digunakan dari himpunan dan menghitung Entropi H(s) atau Information Gain IG(s). Karena kita lebih tertarik untuk mengetahui tentang entropi pohon keputusan dalam artikel ini, mari kita pahami dulu istilah Entropi dan sederhanakan dengan sebuah contoh.
Entropi: Untuk himpunan berhingga S, Entropi, juga disebut Entropi Shannon, adalah ukuran jumlah keacakan atau ketidakpastian dalam data. Dilambangkan dengan H(S).
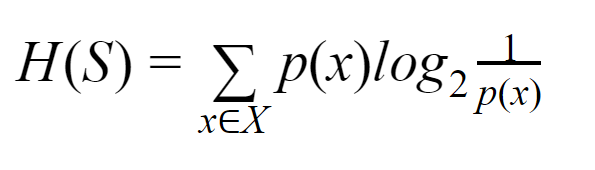
Secara sederhana, ia memprediksi peristiwa tertentu dengan mengukur kemurniannya. Pohon keputusan dibangun dengan cara top-down dan dimulai dengan simpul akar. Data dari simpul akar ini selanjutnya dipartisi atau diklasifikasikan ke dalam himpunan bagian yang berisi instance homogen.
Misalnya, pertimbangkan piring yang digunakan di kafe dengan tulisan "kami buka" di satu sisi dan "kami tutup" di sisi lain. Probabilitas "kami terbuka" adalah 0,5, dan probabilitas "kami tutup" adalah 0,5. Karena tidak ada cara untuk menentukan hasil dalam contoh khusus ini, entropi adalah yang tertinggi.
Datang ke contoh yang sama, jika pelat hanya memiliki tulisan "kita terbuka" di kedua sisinya, maka entropi dapat diprediksi dengan sangat baik karena kita sudah tahu bahwa tetap di sisi depan atau belakang, kita masih akan untuk memiliki "kami terbuka." Dengan kata lain, ia tidak memiliki keacakan, artinya entropi adalah nol. Harus diingat bahwa semakin rendah nilai entropi, semakin tinggi kemurnian acara, dan semakin tinggi nilai entropi, semakin rendah kemurnian acara.
Baca: Klasifikasi Pohon Keputusan
Contoh
Mari kita pertimbangkan bahwa Anda memiliki 110 bola. 89 dari ini adalah bola hijau, dan 21 berwarna biru. Hitung entropi untuk keseluruhan dataset.

Jumlah bola (n) = 110
Karena kita memiliki 89 bola hijau dari 110, probabilitas hijau adalah 80,91% atau 89 dibagi 110, yang menghasilkan 0,8091. Selanjutnya, peluang bola hijau dikalikan dengan log peluang bola hijau menghasilkan 0,2473. Di sini, harus diingat bahwa log probabilitas akan selalu berupa angka negatif. Jadi, kita harus melampirkan tanda negatif. Ini dapat dinyatakan secara sederhana sebagai:
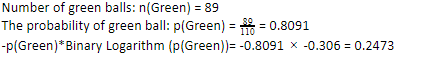
Sekarang, dengan melakukan langkah yang sama untuk bola biru, kita mendapatkan 21 dari 110. Jadi, peluang bola biru adalah 19,09% atau 21 dibagi 110, yang menghasilkan 0,1909. Selanjutnya, mengalikan peluang bola biru dengan log peluang bola biru, kita mendapatkan 0,4561. Sekali lagi, seperti yang diinstruksikan di atas, kami akan melampirkan tanda negatif karena log probabilitas selalu memberikan hasil negatif, yang tidak kami harapkan. Mengekspresikan ini secara sederhana:
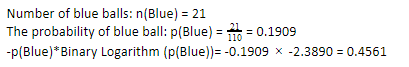
Sekarang, Entropi Pohon Keputusan dari keseluruhan data diberikan oleh jumlah dari entropi individu. Kita membutuhkan jumlah produk peluang bola hijau dan log peluang bola hijau dan hasil kali peluang bola biru dan log peluang bola biru.
Entropi (Data Keseluruhan)= 0,2473 + 0,4561 = 0,7034
Ini adalah salah satu contoh untuk membantu Anda memahami bagaimana entropi dihitung. Mudah-mudahan, ini cukup jelas, dan Anda telah memahami konsep ini. Menghitung entropi pohon keputusan bukanlah ilmu roket seperti itu.
Namun, Anda harus jeli saat melakukan perhitungan. Berada di halaman ini, jelas bahwa Anda adalah penggemar pembelajaran mesin, dan dengan demikian, Anda diharapkan untuk mengetahui betapa pentingnya peran setiap detail menit. Bahkan kesalahan terkecil dapat menyebabkan masalah, dan karenanya, Anda harus selalu memiliki perhitungan yang tepat.
Checkout: Jenis Pohon Biner
Intinya
Pohon keputusan adalah pembelajaran mesin yang diawasi yang menggunakan berbagai algoritma untuk membangun pohon keputusan. Di antara algoritma yang berbeda, algoritma ID3 menggunakan Entropi. Entropi tidak lain adalah ukuran kemurnian acara.
Kita tahu bahwa karier dalam pembelajaran mesin memiliki masa depan yang menjanjikan dan karier yang berkembang. Industri ini masih memiliki jalan panjang untuk mencapai puncaknya, dan karenanya peluang bagi penggemar pembelajaran mesin tumbuh secara eksponensial dengan banyak keuntungan lainnya. Jadikan tempat Anda yang luar biasa di industri pembelajaran mesin dengan bantuan pengetahuan dan keterampilan yang tepat.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang pembelajaran mesin, lihat PG Diploma IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, IIIT- B Status alumni, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Apa perbedaan antara Entropi dan Pengotor Gini?
Algoritma Pohon Keputusan adalah metode klasifikasi yang digunakan untuk memprediksi solusi yang mungkin dan andal. Entropi dihitung dalam Pohon Keputusan untuk mengoptimalkannya. Subset yang melengkapi fitur Pohon Keputusan ini dipilih untuk mencapai kemurnian yang lebih besar dengan menghitung Entropi. Ini menentukan kemurnian komponen dalam subkelompok dan membagi input yang sesuai. Entropi terletak antara 0 hingga 1. Gini juga mengukur pengotor data untuk memilih pemisahan yang paling tepat. Gini Index atau Gini Impurity mengukur apakah suatu divisi salah mengenai fitur-fiturnya. Idealnya, semua pemisahan harus memiliki klasifikasi yang sama untuk mencapai kemurnian.
Apa itu Perolehan Informasi di Pohon Keputusan?
Pohon Keputusan melibatkan banyak pemisahan untuk mencapai kemurnian dalam himpunan bagian. Ketika kemurnian tertinggi, prediksi keputusan adalah yang terkuat. Perolehan informasi adalah proses kalkulatif berkelanjutan untuk mengukur ketidakmurnian pada setiap subset sebelum memisahkan data lebih lanjut. Penguatan informasi menggunakan Entropi untuk menentukan kemurnian ini. Pada setiap subkelompok, rasio berbagai variabel dalam himpunan bagian menentukan jumlah informasi yang diperlukan untuk memilih bagian untuk dipecah lebih lanjut. Perolehan informasi akan lebih seimbang dalam proporsi variabel dalam subset, menjanjikan kemurnian lebih.
Apa kerugian dari Pohon Keputusan?
Algoritma Decision Tree adalah mekanisme pembelajaran mesin yang paling banyak digunakan untuk pengambilan keputusan. Analog dengan pohon, menggunakan node untuk mengklasifikasikan data ke dalam himpunan bagian sampai keputusan yang paling tepat dibuat. Pohon Keputusan membantu memprediksi solusi yang berhasil. Namun, mereka juga memiliki keterbatasan. Pohon Keputusan yang sangat besar sulit untuk diikuti dan dipahami; ini bisa sangat baik karena overfitting data. Jika kumpulan data diubah dengan cara apa pun, dampak dalam keputusan akhir akan mengikuti. Oleh karena itu, Pohon Keputusan mungkin kompleks tetapi dapat dieksekusi dengan tepat dengan pelatihan.