
Entendendo a entropia da árvore de decisão no aprendizado de máquina
Publicados: 2020-12-29A Árvore de Decisão faz parte do Aprendizado de Máquina Supervisionado no qual você explica a entrada para a qual a saída está nos dados de treinamento. Nas árvores de decisão, os dados são divididos várias vezes de acordo com os parâmetros fornecidos. Ele continua dividindo os dados em subconjuntos menores e, simultaneamente, a árvore é desenvolvida de forma incremental. A árvore tem duas entidades, que são nós de decisão e nós folha.
Índice
Diferentes Entidades da Árvore de Decisão
1. Nó de Decisão
Os nós de decisão são aqueles onde os dados se dividem. Geralmente tem dois ou mais ramos.
2. Nós Folha
Os nós folha representam os resultados, classificação ou decisões do evento. Uma árvore binária para “Elegibilidade para o concurso de beleza Miss Índia”:
Tomemos um exemplo de uma árvore binária simples para entender as árvores de decisão. Vamos considerar que você deseja descobrir se uma garota é elegível para um concurso de beleza como Miss Índia.
O nó de decisão primeiro faz a pergunta se a menina é residente da Índia. Se sim, a idade dela está entre 18 e 25 anos? Se sim, ela é elegível, senão não. Se não, ela tem certificados válidos? Se sim, ela é elegível, senão não. Este foi um simples sim ou não tipo de problema. As árvores de decisão são classificadas em dois tipos principais:
Deve ler: Árvore de decisão na IA

Classificação da Árvore de Decisão
1. Árvores de Classificação
As árvores de classificação são do tipo sim ou não de árvores simples. É semelhante ao exemplo que vimos acima, onde o resultado tinha variáveis como 'elegível' ou 'não elegível'. A variável de decisão aqui é Categórica.
2. Árvores de regressão
Em árvores de regressão, a variável de resultado ou a decisão é contínua, por exemplo, uma letra como ABC.
Agora que você está completamente ciente da árvore de decisão e seu tipo, podemos entrar em detalhes. Árvores de decisão podem ser construídas usando muitos algoritmos; no entanto, o algoritmo ID3 ou Iterative Dichotomiser 3 é o melhor. É aqui que a entropia da árvore de decisão entra no quadro.
O algoritmo ID3 em cada iteração passa por um atributo não utilizado do conjunto e calcula a Entropia H(s) ou Ganho de Informação IG(s). Como estamos mais interessados em saber sobre a entropia da árvore de decisão no artigo atual, vamos primeiro entender o termo Entropia e simplificá-lo com um exemplo.
Entropia: Para um conjunto finito S, a entropia, também chamada de entropia de Shannon, é a medida da quantidade de aleatoriedade ou incerteza nos dados. É denotado por H(S).
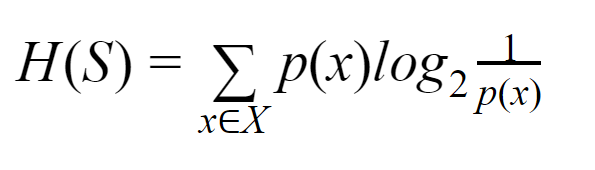
Em termos simples, ele prevê um determinado evento medindo a pureza. A árvore de decisão é construída de forma top-down e começa com um nó raiz. Os dados desse nó raiz são ainda particionados ou classificados em subconjuntos que contêm instâncias homogêneas.
Por exemplo, considere uma placa usada em cafés com “estamos abertos” escrito de um lado e “estamos fechados” do outro. A probabilidade de “estamos abertos” é 0,5 e a probabilidade de “estamos fechados” é 0,5. Como não há como determinar o resultado neste exemplo em particular, a entropia é a mais alta possível.
Voltando ao mesmo exemplo, se a placa tivesse apenas “estamos abertos” escrito em ambos os lados, então a entropia pode ser prevista muito bem, pois já sabemos que mantendo na frente ou no verso, ainda estamos indo ter “estamos abertos”. Em outras palavras, não tem aleatoriedade, o que significa que a entropia é zero. Deve ser lembrado que quanto menor o valor da entropia, maior a pureza do evento, e quanto maior o valor da entropia, menor a pureza do evento.
Leia: Classificação da Árvore de Decisão
Exemplo
Vamos considerar que você tem 110 bolas. 89 delas são bolas verdes e 21 são azuis. Calcule a entropia para o conjunto de dados geral.
Número total de bolas (n) = 110
Como temos 89 bolas verdes de 110, a probabilidade de verde seria 80,91% ou 89 dividido por 110, o que dá 0,8091. Além disso, a probabilidade de bola verde multiplicada pelo logaritmo da probabilidade de verde dá 0,2473. Aqui, deve-se lembrar que um logaritmo de probabilidade sempre será um número negativo. Então, temos que anexar um sinal negativo. Isso pode ser expresso simplesmente como:

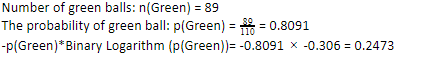
Agora, executando os mesmos passos para as bolas azuis, temos 21 de 110. Portanto, a probabilidade de uma bola azul é 19,09% ou 21 dividido por 110, o que dá 0,1909. Além disso, ao multiplicar a probabilidade das bolas azuis pelo logaritmo da probabilidade da bola azul, obtemos 0,4561. Novamente, conforme instruído acima, estaremos anexando um sinal negativo, pois o logaritmo da probabilidade sempre dá um resultado negativo, o que não esperamos. Expressando isso de forma simples:
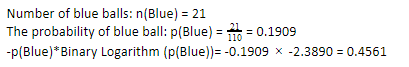
Agora, a Entropia da Árvore de Decisão dos dados globais é dada pela soma da entropia individual. Precisamos da soma do produto da probabilidade de bola verde e log da probabilidade de bola verde e o produto da probabilidade de bola azul e log da probabilidade de bola azul.
Entropia (dados gerais) = 0,2473 + 0,4561 = 0,7034
Este foi um exemplo para ajudá-lo a entender como a entropia é calculada. Espero que esteja bem claro e você tenha entendido esse conceito. Calcular a entropia da árvore de decisão não é ciência do foguete como tal.
No entanto, você deve estar atento ao fazer os cálculos. Estando nesta página, é óbvio que você é um entusiasta do aprendizado de máquina e, portanto, espera-se que você saiba o quão importante é o papel de cada detalhe. Mesmo o menor erro pode causar problemas e, portanto, você deve sempre ter os cálculos adequados.
Checkout: Tipos de Árvore Binária
Resultado final
Uma árvore de decisão é um aprendizado de máquina supervisionado que usa vários algoritmos para construir a árvore de decisão. Entre os diferentes algoritmos, o algoritmo ID3 usa Entropy. A entropia nada mais é do que a medida da pureza do evento.
Sabemos que uma carreira em aprendizado de máquina tem um futuro promissor e uma carreira florescente. Esse setor ainda tem um longo caminho para atingir seu pico e, portanto, as oportunidades para os entusiastas do aprendizado de máquina estão crescendo exponencialmente com muitas outras vantagens. Conquiste seu lugar de destaque no setor de aprendizado de máquina com a ajuda do conhecimento e das habilidades certas.
Se você estiver interessado em aprender mais sobre aprendizado de máquina, confira o PG Diploma in Machine Learning & AI do IIIT-B e upGrad, projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, IIIT- B Status de ex-aluno, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
Qual é a diferença entre Entropia e Gini Impureza?
Os Algoritmos de Árvore de Decisão são métodos de classificação usados para prever soluções possíveis e confiáveis. A entropia é calculada em uma árvore de decisão para otimizá-la. Esses subconjuntos que complementam os recursos da Árvore de Decisão são escolhidos para obter maior pureza calculando a Entropia. Ele determina a pureza do componente no subgrupo e divide a entrada de acordo. A entropia está entre 0 e 1. Gini também mede a impureza dos dados para selecionar a divisão mais apropriada. O Índice de Gini ou Impureza de Gini mede se uma divisão está incorreta em relação às suas características. Idealmente, todas as divisões devem ter a mesma classificação para atingir a pureza.
O que é ganho de informação em árvores de decisão?
Árvores de decisão envolvem muita divisão para obter pureza nos subconjuntos. Quando a pureza é mais alta, a previsão da decisão é a mais forte. O ganho de informação é um processo de cálculo contínuo de medição da impureza em cada subconjunto antes de dividir ainda mais os dados. O ganho de informação usa a entropia para determinar essa pureza. Em cada subgrupo, a proporção de várias variáveis nos subconjuntos determina a quantidade de informação necessária para escolher o subconjunto para divisão posterior. O ganho de informação será mais equilibrado na proporção de variáveis no subconjunto, prometendo mais pureza.
Quais são as desvantagens de uma árvore de decisão?
O algoritmo Árvore de Decisão é o mecanismo de aprendizado de máquina mais utilizado para tomada de decisão. Analogamente a uma árvore, ela usa nós para classificar os dados em subconjuntos até que a decisão mais adequada seja tomada. As Árvores de Decisão ajudam a prever soluções bem-sucedidas. No entanto, eles também têm suas limitações. Árvores de Decisão excessivamente gigantes são difíceis de seguir e perceber; isso pode muito bem ser devido ao overfitting de dados. Se o conjunto de dados for ajustado de alguma forma, as repercussões na decisão final se seguirão. Portanto, as Árvores de Decisão podem ser complexas, mas podem ser executadas adequadamente com treinamento.