
機械学習におけるディシジョンツリーエントロピーの理解
公開: 2020-12-29デシジョンツリーは、教師あり機械学習の一部であり、トレーニングデータに出力が含まれる入力を説明します。 デシジョンツリーでは、データは指定されたパラメータに従って複数回分割されます。 データをより小さなサブセットに分割し続けると同時に、ツリーは段階的に開発されます。 ツリーには、決定ノードとリーフノードの2つのエンティティがあります。
目次
デシジョンツリーのさまざまなエンティティ
1.決定ノード
決定ノードは、データが分割されるノードです。 通常、2つ以上のブランチがあります。
2.リーフノード
リーフノードは、イベントの結果、分類、または決定を表します。 「ミスインド美人コンテストの資格」の二分木:
決定木を理解するために、単純な二分木の例を見てみましょう。 女の子がミスインディアのような美人コンテストの資格があるかどうかを調べたいと考えてみましょう。
決定ノードは、最初に、女の子がインドの居住者であるかどうかを質問します。 はいの場合、彼女の年齢は18〜25歳ですか。 はいの場合、彼女は資格があり、そうでない場合はそうではありません。 いいえの場合、彼女は有効な証明書を持っていますか? はいの場合、彼女は資格があり、そうでない場合はそうではありません。 これは単純な「はい」または「いいえ」のタイプの問題でした。 決定木は、主に2つのタイプに分類されます。
必読: AIのディシジョンツリー

デシジョンツリー分類
1.分類木
分類木は、単純なyesまたはnoタイプのツリーです。 これは、上記の例に似ており、結果には「適格」または「不適格」などの変数が含まれていました。 ここでの決定変数はCategoricalです。
2.回帰ツリー
回帰ツリーでは、結果変数または決定は連続的です。たとえば、ABCのような文字です。
デシジョンツリーとそのタイプを完全に理解したので、その詳細を知ることができます。 決定木は、多くのアルゴリズムを使用して構築できます。 ただし、ID3または反復二分法3アルゴリズムが最適です。 ここで、決定木のエントロピーがフレームに入ります。
すべての反復でID3アルゴリズムは、セットの未使用の属性を調べ、エントロピーH(s)または情報ゲインIG(s)を計算します。 現在の記事では決定木のエントロピーについてもっと知りたいので、最初にエントロピーという用語を理解し、例を挙げて簡略化してみましょう。
エントロピー:有限集合Sの場合、エントロピーはシャノンエントロピーとも呼ばれ、データのランダム性または不確実性の量の尺度です。 H(S)で表されます。
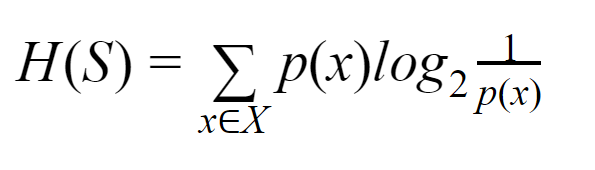
簡単に言えば、純度を測定することで特定のイベントを予測します。 デシジョンツリーはトップダウン方式で構築され、ルートノードから始まります。 このルートノードのデータは、同種のインスタンスを含むサブセットにさらに分割または分類されます。
たとえば、カフェで使用されている、片側に「開いている」、反対側に「閉じている」と書かれているプレートを考えてみます。 「私たちは開いている」の確率は0.5であり、「私たちは閉じている」の確率は0.5です。 この特定の例では結果を決定する方法がないため、エントロピーは可能な限り高くなります。
同じ例で、プレートの両面に「開いている」と書かれているだけの場合、エントロピーは非常によく予測できます。これは、表側または裏側のどちらかを維持していることをすでに知っているためです。 「私たちはオープンです」ということです。 つまり、ランダム性がなく、エントロピーがゼロであることを意味します。 エントロピーの値が低いほど、イベントの純度が高くなり、エントロピーの値が高いほど、イベントの純度が低くなることを覚えておく必要があります。

読む:ディシジョンツリー分類
例
110個のボールがあるとしましょう。 これらのうち89個は緑色のボールで、21個は青色です。 データセット全体のエントロピーを計算します。
ボールの総数(n)= 110
110個のうち89個の緑色のボールがあるので、緑色の確率は80.91%、つまり89を110で割ると、0.8091になります。 さらに、緑色のボールの確率に緑色の確率の対数を掛けると、0.2473になります。 ここで、確率の対数は常に負の数になることに注意してください。 したがって、マイナス記号を付ける必要があります。 これは簡単に次のように表すことができます。
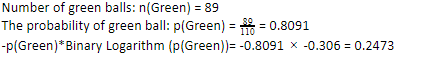
ここで、青いボールに対して同じ手順を実行すると、110のうち21が得られます。したがって、青いボールの確率は19.09%または21を110で割ると、0.1909になります。 さらに、青いボールの確率に青いボールの確率の対数を掛けると、0.4561が得られます。 繰り返しになりますが、上記のように、確率の対数は常に負の結果をもたらすため、負の符号を付けますが、これは予期しないことです。 これを簡単に表現すると:
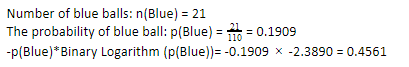
ここで、データ全体のディシジョンツリーエントロピーは、個々のエントロピーの合計によって与えられます。 緑のボールの確率と緑のボールの確率の対数の積と、青のボールの確率と青のボールの確率の対数の積の合計が必要です。
エントロピー(全体データ)= 0.2473 + 0.4561 = 0.7034
これは、エントロピーの計算方法を理解するのに役立つ1つの例です。 うまくいけば、それはかなり明確であり、あなたはこの概念を理解しています。 デシジョンツリーのエントロピーを計算すること自体は、ロケット科学ではありません。
ただし、計算を行うときは熱心でなければなりません。 このページを見ると、あなたが機械学習の愛好家であることは明らかです。したがって、細部の役割がどれほど重要であるかを知っていることが期待されます。 どんなに小さな間違いでも問題を引き起こす可能性があるため、常に適切な計算を行う必要があります。
チェックアウト:二分木の種類
結論
デシジョンツリーは、さまざまなアルゴリズムを使用してデシジョンツリーを構築する教師あり機械学習です。 さまざまなアルゴリズムの中で、ID3アルゴリズムはエントロピーを使用します。 エントロピーは、イベントの純度の尺度に他なりません。
機械学習のキャリアには、有望な未来と繁栄するキャリアがあることを私たちは知っています。 この業界はまだピークに達するまでに長い道のりがあり、したがって機械学習愛好家の機会は他の多くの利点とともに指数関数的に成長しています。 適切な知識とスキルを活用して、機械学習業界で注目に値する場所を作りましょう。
機械学習について詳しく知りたい場合は、IIIT-BとupGradの機械学習とAIのPGディプロマをご覧ください。これは、働く専門家向けに設計されており、450時間以上の厳格なトレーニング、30以上のケーススタディと課題、IIIT-を提供します。 B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との仕事の支援。
エントロピーとジニ不純物の違いは何ですか?
デシジョンツリーアルゴリズムは、可能な信頼できるソリューションを予測するために使用される分類方法です。 エントロピーは、それを最適化するために決定木で計算されます。 デシジョンツリー機能を補完するこれらのサブセットは、エントロピーを計算することでより高い純度を実現するために選択されます。 サブグループ内のコンポーネントの純度を決定し、それに応じて入力を分割します。 エントロピーは0から1の間にあります。Giniはデータの不純物も測定して、最も適切な分割を選択します。 GiniIndexまたはGiniImpurityは、除算がその機能に関して正しくないかどうかを測定します。 理想的には、純度を達成するために、すべての分割が同じ分類を持つ必要があります。
デシジョンツリーでの情報獲得とは何ですか?
デシジョンツリーは、サブセットの純度を達成するために多くの分割を伴います。 純度が最も高い場合、決定の予測が最も強くなります。 情報ゲインは、データをさらに分割する前に、各サブセットで不純物を測定する連続的な計算プロセスです。 情報ゲインは、エントロピーを使用してこの純度を決定します。 各サブグループで、サブセット内のさまざまな変数の比率によって、さらに分割するサブセットを選択するために必要な情報の量が決まります。 情報の獲得は、サブセット内の変数の比率でよりバランスが取れており、より純粋であることが約束されます。
デシジョンツリーの欠点は何ですか?
デシジョンツリーアルゴリズムは、意思決定に最も広く使用されている機械学習メカニズムです。 ツリーと同様に、ノードを使用して、最も適切な決定が行われるまでデータをサブセットに分類します。 デシジョンツリーは、成功するソリューションを予測するのに役立ちます。 ただし、制限もあります。 過度に巨大な決定木は、追跡および認識が困難です。 これは、データの過剰適合が原因である可能性が非常に高くなります。 データセットが何らかの方法で調整された場合、最終決定への影響が続きます。 したがって、ディシジョンツリーは複雑になる可能性がありますが、トレーニングによって適切に実行できます。