
Uma intuição por trás da análise de sentimentos: como fazer a análise de sentimentos do zero?
Publicados: 2020-12-07Índice
Introdução
O texto é o meio mais importante de percepção da informação para os seres humanos. A maior parte da inteligência adquirida pelos humanos é através do aprendizado e compreensão do significado dos textos e frases ao seu redor.
Depois de uma certa idade, o ser humano desenvolve um reflexo intrínseco para entender a inferência de qualquer palavra/texto mesmo sem saber. Para máquinas, essa tarefa é completamente diferente. Para assimilar os significados de textos e frases, as máquinas contam com os fundamentos do Processamento de Linguagem Natural (PLN).
O aprendizado profundo para processamento de linguagem natural é o reconhecimento de padrões aplicado a palavras, frases e parágrafos, da mesma forma que a visão computacional é o reconhecimento de padrões aplicado a pixels de imagem.
Nenhum desses modelos de aprendizado profundo realmente entende o texto em um sentido humano; em vez disso, esses modelos podem mapear a estrutura estatística da linguagem escrita, o que é suficiente para resolver muitas tarefas textuais simples. A análise de sentimento é uma dessas tarefas, por exemplo: classificar o sentimento de strings ou críticas de filmes como positivo ou negativo.
Estes têm aplicações em larga escala na indústria também. Por exemplo: uma empresa de bens e serviços gostaria de coletar os dados do número de avaliações positivas e negativas que recebeu de um produto específico para trabalhar no ciclo de vida do produto e melhorar seus números de vendas e coletar feedback dos clientes.
Pré-processando
A tarefa de análise de sentimentos pode ser dividida em um algoritmo simples de aprendizado de máquina supervisionado, onde geralmente temos uma entrada X , que entra em uma função de previsão para obter Em seguida, comparamos nossa previsão com o valor verdadeiro Y , o que nos dá o custo que usamos para atualizar os parâmetros Para lidar com a tarefa de extrair sentimentos de um fluxo de textos inéditos, o passo primitivo é reunir um conjunto de dados rotulado com sentimentos positivos e negativos separados. Esses sentimentos podem ser: boa ou má crítica, comentário sarcástico ou não sarcástico, etc.
O próximo passo é criar um vetor de dimensão V , onde Este vetor de vocabulário conterá cada palavra (nenhuma palavra é repetida) que está presente em nosso conjunto de dados e atuará como um léxico para nossa máquina ao qual ele pode se referir. Agora pré-processamos o vetor de vocabulário para remover redundâncias. As seguintes etapas são executadas:
- Eliminar URLs e outras informações não triviais (que não ajudam a determinar o significado de uma frase)
- Tokenizando a string em palavras: suponha que temos a string “I love machine learning”, agora, tokenizando, simplesmente quebramos a frase em palavras únicas e a armazenamos em uma lista como [I, love, machine, learning]
- Removendo palavras de parada como “e”, “sou”, “ou”, “eu”, etc.
- Stemming: transformamos cada palavra em sua forma radical. Palavras como “tune”, “tuning” e “tuned” têm semanticamente o mesmo significado, então reduzi-las à sua forma radical que é “tun” reduzirá o tamanho do vocabulário
- Convertendo todas as palavras para minúsculas
Para resumir a etapa de pré-processamento, vamos dar uma olhada em um exemplo: digamos que temos uma string positiva “Estou adorando o novo produto em upGrad.com” . A string final pré-processada é obtida removendo o URL, tokenizando a frase em uma única lista de palavras, removendo as palavras de parada como “eu, sou, o, em”, e então derivando as palavras “amando” para “lov” e “produto” para “produ” e, finalmente, convertendo tudo para minúsculas, o que resulta na lista [lov, new, produ] .
Extração de recursos
Após o corpus ser pré-processado, o próximo passo seria extrair características da lista de sentenças. Como todas as outras redes neurais, os modelos de aprendizado profundo não aceitam texto bruto de entrada: eles só funcionam com tensores numéricos. A lista de palavras pré-processadas precisa, portanto, ser convertida em valores numéricos. Isso pode ser feito da seguinte maneira. Suponha que, dada uma compilação de strings com strings positivas e negativas, como (assuma isso como o conjunto de dados) :
| Cadeias positivas | Strings negativas |
|
|
Agora, para converter cada uma dessas strings em um vetor numérico de dimensão 3, criamos um dicionário para mapear a palavra e a classe em que ela apareceu (positiva ou negativa) para o número de vezes que a palavra apareceu em sua classe correspondente.
| Vocabulário | Frequência positiva | Frequência negativa |
| eu | 3 | 3 |
| sou | 3 | 3 |
| feliz | 2 | 0 |
| Porque | 1 | 0 |
| Aprendendo | 1 | 1 |
| PNL | 1 | 1 |
| triste | 0 | 2 |
| não | 0 | 1 |
Depois de gerar o dicionário citado, olhamos para cada uma das strings individualmente, e então somamos o número de frequência positiva e negativa das palavras que aparecem na string deixando as palavras que não aparecem na string. Vamos pegar a string '“Estou triste, não estou aprendendo PNL” e gerar o vetor de dimensão 3.

“Estou triste, não estou aprendendo PNL”
| Vocabulário | Frequência positiva | Frequência negativa |
| eu | 3 | 3 |
| sou | 3 | 3 |
| feliz | 2 | 0 |
| Porque | 1 | 0 |
| Aprendendo | 1 | 1 |
| PNL | 1 | 1 |
| triste | 0 | 2 |
| não | 0 | 1 |
| Soma = 8 | Soma = 11 |
Vemos que para a string “Estou triste, não estou aprendendo PNL”, apenas duas palavras “feliz, porque” não estão contidas no vocabulário, agora para extrair características e criar o referido vetor, somamos a frequência positiva e negativa colunas separadamente deixando de fora o número de frequência das palavras que não estão presentes na string, neste caso deixamos “feliz, porque”. Obtemos a soma como 8 para a frequência positiva e 9 para a frequência negativa.
Assim, a string “Estou triste, não estou aprendendo PNL” pode ser representada como um vetor O número “1” presente no índice 0 é a unidade de polarização que permanecerá “1” para todas as próximas strings e os números “8”, “11” representam a soma das frequências positivas e negativas, respectivamente.
De maneira semelhante, todas as strings no conjunto de dados podem ser convertidas confortavelmente em um vetor de dimensão 3.
Leia mais: Análise de sentimentos usando Python: um guia prático
Aplicando a regressão logística
A extração de recursos facilita a compreensão da essência da frase, mas as máquinas ainda precisam de uma maneira mais nítida de sinalizar uma string não vista em positiva ou negativa. Aqui entra em jogo a regressão logística que faz uso da função sigmóide que produz uma probabilidade entre 0 e 1 para cada string vetorizada.

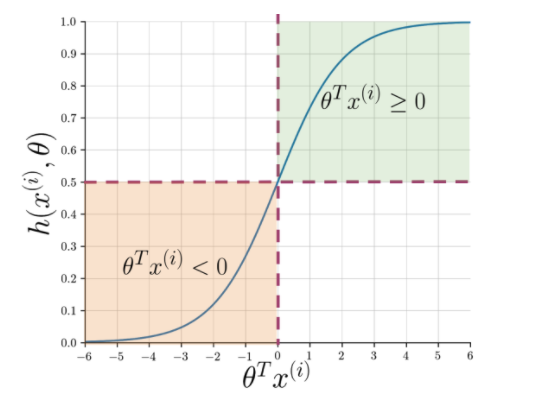
Figura 1: Notação gráfica da função sigmóide
A Figura 1 mostra que sempre que o produto escalar de teta e Leia também: As 4 principais ideias de projetos de análise de dados: nível iniciante a especialista
Qual o proximo?
A Análise de Sentimentos é um tópico essencial no aprendizado de máquina. Tem inúmeras aplicações em vários campos. Se você quiser saber mais sobre esse tópico, acesse nosso blog e encontre muitos novos recursos.
Por outro lado, se você deseja obter uma experiência de aprendizado abrangente e estruturada, também se estiver interessado em aprender mais sobre aprendizado de máquina, confira o Diploma PG do IIIT-B e do upGrad em aprendizado de máquina e IA, projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, status de ex-alunos do IIIT-B, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
Q1. Por que o algoritmo Random Forest é melhor para aprendizado de máquina?
O algoritmo Random Forest pertence à categoria de algoritmos de aprendizado supervisionado, que são amplamente utilizados no desenvolvimento de diferentes modelos de aprendizado de máquina. O algoritmo de floresta aleatória pode ser aplicado tanto para modelos de classificação quanto para modelos de regressão. O que torna esse algoritmo o mais adequado para aprendizado de máquina é o fato de funcionar de forma brilhante com informações de alta dimensão, já que o aprendizado de máquina lida principalmente com subconjuntos de dados. Curiosamente, o algoritmo de floresta aleatória é derivado do algoritmo de árvores de decisão. Mas você pode treinar usando esse algoritmo em um período de tempo muito menor do que usando árvores de decisão, pois ele usa apenas recursos específicos. Oferece maior eficiência em modelos de aprendizado de máquina e, portanto, é mais preferido.
Q2. Como o aprendizado de máquina é diferente do aprendizado profundo?
Tanto o aprendizado profundo quanto o aprendizado de máquina são subcampos de todo o guarda-chuva que chamamos de inteligência artificial. No entanto, esses dois subcampos vêm com suas próprias diferenças. O aprendizado profundo é essencialmente um subconjunto do aprendizado de máquina. No entanto, usando o aprendizado profundo, as máquinas podem analisar vídeos, imagens e outras formas de dados não estruturados, o que pode ser difícil de alcançar empregando apenas o aprendizado de máquina. O aprendizado de máquina tem tudo a ver com permitir que os computadores pensem e ajam por si mesmos, com o mínimo de intervenção humana. Em contraste, o aprendizado profundo é usado para ajudar as máquinas a pensar com base em estruturas semelhantes ao cérebro humano.
Q3. Por que os cientistas de dados preferem o algoritmo de floresta aleatória?
Há muitos benefícios em usar o algoritmo de floresta aleatória, o que o torna a escolha preferida entre os cientistas de dados. Em primeiro lugar, fornece resultados altamente precisos quando comparados a outros algoritmos lineares, como regressão logística e linear. Embora esse algoritmo possa ser difícil de explicar, é mais fácil inspecionar e interpretar os resultados com base em suas árvores de decisão subjacentes. Você pode usar esse algoritmo com a mesma facilidade, mesmo quando novas amostras e recursos são adicionados a ele. É fácil de usar mesmo quando alguns dados estão faltando.