
Intuicja za analizą nastrojów: jak przeprowadzić analizę nastrojów od podstaw?
Opublikowany: 2020-12-07Spis treści
Wstęp
Tekst jest dla człowieka najważniejszym środkiem odbierania informacji. Większość inteligencji zdobywanej przez ludzi to uczenie się i rozumienie znaczenia tekstów i zdań wokół nich.
Po pewnym wieku ludzie rozwijają wewnętrzny odruch, aby zrozumieć wnioskowanie dowolnego słowa/tekstu, nawet nie wiedząc. W przypadku maszyn to zadanie jest zupełnie inne. Aby przyswoić znaczenia tekstów i zdań, maszyny opierają się na podstawach przetwarzania języka naturalnego (NLP).
Głębokie uczenie do przetwarzania języka naturalnego to rozpoznawanie wzorców stosowane do słów, zdań i akapitów, podobnie jak widzenie komputerowe jest rozpoznawaniem wzorców stosowanym do pikseli obrazu.
Żaden z tych modeli głębokiego uczenia się naprawdę nie rozumie tekstu w ludzkim sensie; modele te mogą raczej odwzorować strukturę statystyczną języka pisanego, co wystarcza do rozwiązania wielu prostych zadań tekstowych. Jednym z takich zadań jest analiza sentymentu, na przykład: klasyfikowanie sentymentu napisów lub recenzji filmów jako pozytywne lub negatywne.
Mają one również zastosowanie w przemyśle na dużą skalę. Na przykład: firma zajmująca się towarami i usługami chciałaby zebrać dane o liczbie pozytywnych i negatywnych recenzji, które otrzymała dla danego produktu, aby pracować nad cyklem życia produktu i poprawić wyniki sprzedaży oraz zebrać opinie klientów.
Przetwarzanie wstępne
Zadanie analizy sentymentu można podzielić na prosty nadzorowany algorytm uczenia maszynowego, w którym zwykle mamy wejście X , które przechodzi do funkcji predykcyjnej, aby uzyskać Następnie porównujemy nasze przewidywanie z prawdziwą wartością Y . Daje nam to koszt, którego następnie używamy do aktualizacji parametrów Aby poradzić sobie z zadaniem wyodrębnienia sentymentów z wcześniej niewidzianego strumienia tekstów, podstawowym krokiem jest zebranie oznakowanego zestawu danych z oddzielnymi sentymentami pozytywnymi i negatywnymi. Tymi opiniami mogą być: dobra recenzja lub zła recenzja, sarkastyczna uwaga lub niesarkastyczna uwaga itp.
Następnym krokiem jest utworzenie wektora wymiaru V , gdzie Ten wektor słownictwa będzie zawierał każde słowo (żadne słowo się nie powtarza) obecne w naszym zbiorze danych i będzie działać jako leksykon dla naszej maszyny, do której może się odwoływać. Teraz wstępnie przetwarzamy wektor słownictwa, aby usunąć nadmiarowość. Wykonywane są następujące kroki:
- Eliminowanie adresów URL i innych nietrywialnych informacji (co nie pomaga w określeniu znaczenia zdania)
- Tokenizacja ciągu na słowa: załóżmy, że mamy ciąg „Uwielbiam uczenie maszynowe”, teraz poprzez tokenizację po prostu dzielimy zdanie na pojedyncze słowa i przechowujemy je na liście jako [I, love, machine, learning]
- Usuwanie słów stop, takich jak „i”, „jestem”, „lub”, „ja” itp.
- Pytanie: przekształcamy każde słowo w jego formę rdzenia. Słowa takie jak „dostrojenie”, „dostrojenie” i „dostrojenie” mają semantycznie to samo znaczenie, więc sprowadzenie ich do formy rdzenia, czyli „tun”, zmniejszy rozmiar słownictwa
- Konwersja wszystkich słów na małe litery
Aby podsumować etap przetwarzania wstępnego, spójrzmy na przykład: powiedzmy, że mamy pozytywny ciąg „Kocham nowy produkt na upGrad.com” . Końcowy wstępnie przetworzony ciąg jest uzyskiwany przez usunięcie adresu URL, tokenizację zdania na pojedynczą listę słów, usunięcie słów stop, takich jak „ja, jestem, the, at”, a następnie podzielenie słów „kocham” na „kocham” i „produkt” na „produ” i ostatecznie konwertując wszystko na małe litery, co daje w wyniku listę [lov, new, produ] .
Ekstrakcja funkcji
Po wstępnym przetworzeniu korpusu następnym krokiem byłoby wyodrębnienie cech z listy zdań. Podobnie jak wszystkie inne sieci neuronowe, modele uczenia głębokiego nie przyjmują jako wejściowego nieprzetworzonego tekstu: działają tylko z tensorami numerycznymi. Wstępnie przetworzona lista słów musi zatem zostać przekonwertowana na wartości liczbowe. Można to zrobić w następujący sposób. Załóżmy, że podaliśmy kompilację ciągów z ciągami dodatnimi i ujemnymi, takimi jak (przyjmijmy to jako zbiór danych) :
| Dodatnie ciągi | Negatywne struny |
|
|
Teraz, aby przekonwertować każdy z tych ciągów na wektor numeryczny o wymiarze 3, tworzymy słownik, aby odwzorować słowo i klasę, w której się pojawiło (dodatnią lub ujemną) na liczbę wystąpień tego słowa w odpowiadającej mu klasie.
| Słownictwo | Dodatnia częstotliwość | Ujemna częstotliwość |
| i | 3 | 3 |
| jestem | 3 | 3 |
| szczęśliwy | 2 | 0 |
| dlatego | 1 | 0 |
| uczenie się | 1 | 1 |
| NLP | 1 | 1 |
| smutny | 0 | 2 |
| nie | 0 | 1 |
Po wygenerowaniu w/w słownika patrzymy na każdy z ciągów z osobna, a następnie sumujemy liczbę dodatnią i ujemną częstości występowania słów występujących w ciągu pozostawiając słowa, które w ciągu nie występują. Weźmy ciąg „Jestem smutny, nie uczę się NLP” i wygenerujmy wektor wymiaru 3.

„Jestem smutny, nie uczę się NLP”
| Słownictwo | Dodatnia częstotliwość | Ujemna częstotliwość |
| i | 3 | 3 |
| jestem | 3 | 3 |
| szczęśliwy | 2 | 0 |
| dlatego | 1 | 0 |
| uczenie się | 1 | 1 |
| NLP | 1 | 1 |
| smutny | 0 | 2 |
| nie | 0 | 1 |
| Suma = 8 | Suma = 11 |
Widzimy, że dla ciągu „jest mi smutno, nie uczę się NLP” tylko dwa słowa „szczęśliwy, bo” nie są zawarte w słowniku, teraz aby wyodrębnić cechy i stworzyć wspomniany wektor, sumujemy częstotliwość dodatnią i ujemną kolumny osobno pomijając numer częstotliwości słów, które nie występują w ciągu, w tym przypadku zostawiamy „szczęśliwy, ponieważ”. Otrzymujemy sumę jako 8 dla częstotliwości dodatniej i 9 dla częstotliwości ujemnej.
Stąd ciąg „Jestem smutny, nie uczę się NLP” można przedstawić jako wektor Liczba „1” obecna w indeksie 0 jest jednostką odchylenia, która pozostanie „1” dla wszystkich przyszłych ciągów, a liczby „8”, „11” reprezentują odpowiednio sumę częstotliwości dodatnich i ujemnych.
W podobny sposób wszystkie łańcuchy w zbiorze danych można wygodnie przekonwertować na wektor o wymiarze 3.
Przeczytaj więcej: Analiza nastrojów za pomocą Pythona: praktyczny przewodnik
Stosowanie regresji logistycznej
Wyodrębnianie cech ułatwia zrozumienie istoty zdania, ale maszyny nadal potrzebują bardziej wyrazistego sposobu oznaczania niewidocznego ciągu jako dodatniego lub ujemnego. Tutaj w grę wchodzi regresja logistyczna, która wykorzystuje funkcję sigmoidalną, która wyprowadza prawdopodobieństwo od 0 do 1 dla każdego zwektoryzowanego łańcucha.

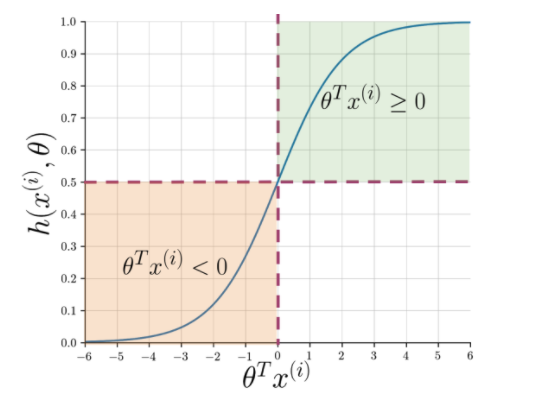
Rysunek 1: Graficzna notacja funkcji sigmoidalnej
Rysunek 1 pokazuje, że ilekroć iloczyn skalarny teta i Przeczytaj także: 4 najlepsze pomysły na projekty dotyczące analizy danych: poziom od początkującego do eksperta
Co następne?
Analiza nastrojów jest istotnym tematem w uczeniu maszynowym. Ma wiele zastosowań w wielu dziedzinach. Jeśli chcesz dowiedzieć się więcej na ten temat, możesz udać się na nasz blog i znaleźć wiele nowych zasobów.
Z drugiej strony, jeśli chcesz uzyskać wszechstronne i zorganizowane doświadczenie uczenia się, również jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, sprawdź IIIT-B i upGrad's PG Diploma in Machine Learning & AI, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznego szkolenia, ponad 30 studiów przypadków i zadań, status absolwentów IIIT-B, ponad 5 praktycznych praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Q1. Dlaczego algorytm losowego lasu jest najlepszy do uczenia maszynowego?
Algorytm Random Forest należy do kategorii algorytmów uczenia nadzorowanego, które są szeroko stosowane w tworzeniu różnych modeli uczenia maszynowego. Algorytm lasu losowego może być stosowany zarówno do modeli klasyfikacji, jak i regresji. To, co sprawia, że ten algorytm jest najbardziej odpowiedni do uczenia maszynowego, to fakt, że doskonale współpracuje z informacjami wielowymiarowymi, ponieważ uczenie maszynowe zajmuje się głównie podzbiorami danych. Co ciekawe, algorytm losowego lasu wywodzi się z algorytmu drzew decyzyjnych. Ale możesz nauczyć się korzystania z tego algorytmu w znacznie krótszym czasie niż przy użyciu drzew decyzyjnych, ponieważ używa on tylko określonych funkcji. Oferuje większą wydajność w modelach uczenia maszynowego, dlatego jest bardziej preferowany.
Q2. Czym różni się uczenie maszynowe od uczenia głębokiego?
Zarówno uczenie głębokie, jak i uczenie maszynowe to poddziedziny całego parasola, który nazywamy sztuczną inteligencją. Jednak te dwa podpola mają swoje własne różnice. Głębokie uczenie jest zasadniczo podzbiorem uczenia maszynowego. Jednak dzięki głębokiemu uczeniu maszyny mogą analizować filmy, obrazy i inne formy nieustrukturyzowanych danych, co może być trudne do osiągnięcia przy użyciu samego uczenia maszynowego. Uczenie maszynowe polega na umożliwieniu komputerom samodzielnego myślenia i działania przy minimalnej interwencji człowieka. W przeciwieństwie do tego, głębokie uczenie jest wykorzystywane, aby pomóc maszynom myśleć w oparciu o struktury przypominające ludzki mózg.
Q3. Dlaczego naukowcy zajmujący się danymi preferują algorytm losowego lasu?
Istnieje wiele korzyści z używania algorytmu losowego lasu, co sprawia, że jest to preferowany wybór wśród naukowców zajmujących się danymi. Po pierwsze, zapewnia bardzo dokładne wyniki w porównaniu z innymi algorytmami liniowymi, takimi jak regresja logistyczna i liniowa. Chociaż wyjaśnienie tego algorytmu może być trudne, łatwiej jest sprawdzić i zinterpretować wyniki na podstawie leżących u jego podstaw drzew decyzyjnych. Możesz używać tego algorytmu z równą łatwością, nawet jeśli zostaną do niego dodane nowe próbki i funkcje. Jest łatwy w użyciu, nawet gdy brakuje niektórych danych.