
Rでの相互検証:使用法、モデル、測定
公開: 2020-10-19データサイエンスと機械学習の世界への旅に出るときは、常にモデルの作成とアルゴリズムから始める傾向があります。 実際のデータでモデルの有効性をテストする方法を学習したり、知ったりすることは避けがちです。
Rの相互検証は、データのサブセットを優先し、バイアスまたは分散のトレードオフを理解して、トレーニングしたデータを超えて適用した場合のモデルのパフォーマンスを十分に理解することにより、ホールドアウト検証プロセスを改善するモデル検証の一種です。オン。 この記事は、データモデルの検証と、モデルの検証の必要性を解明するための最初から最後までのガイドになります。
目次
学習モデルの不安定性
これを理解するために、これらの写真を使用して、さまざまなモデルの学習曲線の適合を説明します。
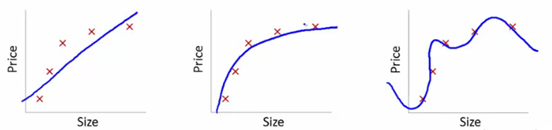
ソース
ここでは、サイズに対する商品価格への依存の学習モデルを示しました。
プロットを表示するために、これらの間に線形変換方程式をフィッティングしました。
トレーニングセットポイントから、最初のプロットは誤りです。 したがって、テストセットでは、パフォーマンスは高くありません。 つまり、これは「アンダーフィッティング」と言えます。 ここでは、モデルはデータの実際のパターンを理解できません。
次のプロットは、サイズに対する価格の正しい依存関係を示しています。 最小限のトレーニングエラーを示しています。 したがって、関係は一般化されます。
最後のプロットでは、トレーニングエラーがほとんどない関係を確立します。 データポイントの各変動とノイズを考慮して関係を構築します。 データモデルは非常に脆弱です。 近似は、エラーを最小限に抑えるように調整されるため、特定のデータセットに複雑なパターンが生成されます。 これは「過剰適合」として知られています。 ここでは、トレーニングセットとテストセットの間に大きな違いがある可能性があります。
データサイエンスの世界では、さまざまなモデルの中から、より優れたパフォーマンスを発揮するモデルが求められています。 ただし、この改善されたスコアが、関係がより適切にキャプチャされたためなのか、データの過剰適合によるものなのかを理解するのが難しい場合があります。 これらの検証手法を使用して、正しいソリューションを提供します。 これにより、これらの手法を使用して、より一般化されたパターンも取得できます。
過剰適合と過適合とは何ですか?
機械学習の不適合とは、不十分なパターンをキャプチャすることを指します。 トレーニングセットとテストセットでモデルを実行すると、パフォーマンスが非常に低下します。
機械学習での過剰適合とは、ノイズとパターンをキャプチャすることを意味します。 これらは、トレーニングを受けていないデータにうまく一般化されていません。 トレーニングセットでモデルを実行すると、パフォーマンスは非常に高くなりますが、テストセットで実行するとパフォーマンスが低下します。
相互検証とは何ですか?
交差検定は、推定に使用されない新しいデータを予測するモデルの能力をテストして、過剰適合や選択バイアスなどの問題にフラグを立てることを目的としています。 また、データベースの一般化に関する洞察も提供されます。
相互検証を整理する手順:
- サンプル標本としてデータセットを取っておきます。
- データセットの他の部分を使用してモデルトレーニングを行います。
- テストには予約済みのサンプルセットを使用します。 このセットは、モデルの魅力的なパフォーマンスを定量化するのに役立ちます。
統計モデルの検証
統計では、モデル検証により、統計モデルの許容可能な出力が実際のデータから生成されていることが確認されます。 プログラムの主な目的が完全に処理されるように、統計モデルの出力がデータ生成プロセスの出力から派生していることを確認します。
検証は通常、モデル構築で使用されたデータで評価されるだけでなく、構築で使用されなかったデータも使用します。 したがって、検証は通常、モデルの予測の一部をテストします。
相互検証の使用は何ですか?
相互検証は、主に、将来のデータでモデルのスキルを推定するための応用機械学習で使用されます。 つまり、特定のサンプルを使用して、モデルのトレーニング中に未使用のデータを予測しながら、モデルが一般的にどのように実行されると予想されるかを推定します。
交差検定は過剰適合を減らしますか?
相互検証は、過剰適合に対する強力な保護アクションです。 アイデアは、トレーニングセットで使用された初期データを使用して、多くの小さなトレインテスト分割を取得することです。 次に、これらの分割を使用してモデルを調整します。 通常のk分割交差検定では、データをk個のサブセットに分割します。これらのサブセットは分割と呼ばれます。
読む:インドのR開発者給与
Rの交差検定に使用される方法
データサイエンティストが相互検証のパフォーマンスに使用する方法はたくさんあります。 ここではそれらのいくつかについて説明します。
1.検証セットアプローチ
検証セットアプローチは、テストデータセットを作成することによってモデルのエラー率を推定するために使用される方法です。 トレーニングデータセットとも呼ばれる他の一連の観測値を使用してモデルを構築します。 次に、モデルの結果がテストデータセットに適用されます。 次に、テストデータセットエラーを計算できます。 したがって、モデルが過剰適合しないようにします。
Rコード:
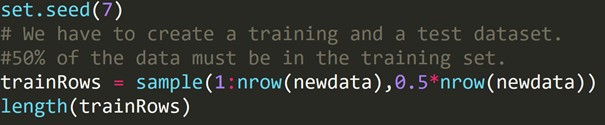
上記のコードを記述して、トレーニングデータセットと別のテストデータセットを作成しました。 したがって、トレーニングデータセットを使用して予測モデルを構築します。 次に、エラー率をチェックするためにテストデータセットに適用されます。
2. Leave-one-out cross-validation(LOOCV)
Leave-one-out Cross-Validation (LOOCV)は、k分割の特定の多次元タイプのCross-Validationです。 ここでは、データセット内のフォールド数とインスタンス数は同じです。 すべてのインスタンスで、学習アルゴリズムは1回だけ実行されます。 統計では、ジャックナイフ推定と呼ばれる同様のプロセスがあります。
Rコードスニペット:
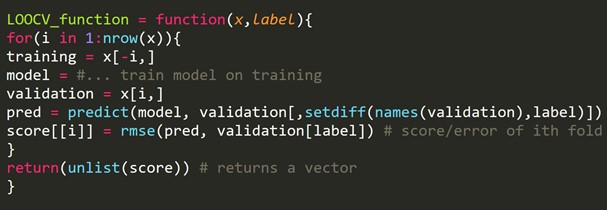

いくつかのトレーニング例を省くことができます。これにより、反復ごとに同じサイズの検証セットが作成されます。 このプロセスは、LPOCV(Leave P Out Cross Validation)として知られています。
3.k-Fold相互検証
機械学習モデルを評価するために、限られたデータサンプルでリサンプリング手順が使用されました。
手順は、特定のデータサンプルが分割されるグループの数を参照する単一のパラメーターを定義することから始まります。 したがって、この手順はk-foldCross -Validationと呼ばれます。
データサイエンティストは、適用された機械学習で相互検証を使用して、未使用のデータの機械学習モデルの特徴を推定することがよくあります。
理解するのは比較的簡単です。 多くの場合、単純な列車セットやテストセットのように、モデルスキルのバイアスや過剰適合の推定値が少なくなります。
一般的な手順は、いくつかの簡単な手順で構成されています。
- データセットを混合してランダム化する必要があります。
- 次に、データセットを同様のサイズのk個のグループに分割します。
- 一意のグループごとに:
グループを特定のテストデータセットとして取得する必要があります。 次に、残りのすべてのグループをトレーニングデータセット全体と見なします。 次に、モデルをトレーニングセットに適合させ、結果を確認します。 テストセットで実行します。 評価スコアを書き留めます。
Rコードスニペット:

4.層化k分割交差検定
階層化とは、各フォールドが健全な代表であることを確認するためのデータの再配置です。 50%のデータの各クラスを持つバイナリ分類問題を考えてみましょう。
バイアスと分散の両方を処理する場合は、層化されたk分割交差検定が最良の方法です。
Rコードスニペット:

5.敵対的検証
基本的な考え方は、機能の類似性のパーセンテージと、トレーニングとテストの間のそれらの分布をチェックすることです。 それらを区別するのが容易でない場合、分布は必ず類似しており、一般的な検証方法がうまくいくはずです。
実際のデータセットを処理しているときに、テストセットとトレインセットが大きく異なる場合があります。 内部相互検証手法は、テストスコアの範囲内ではなく、スコアを生成します。 ここで、敵対的な検証が機能します。
特徴分布に関するトレーニングとテスト内の類似度をチェックします。 この検証は、トレインセットとテストセットをマージし、0または1(ゼロ–トレイン、1テスト)にラベルを付け、バイナリスコアの分類タスクを分析することで特徴づけられます。
トレインセットの各行に1、テストセットの各行に0の新しいターゲット変数を作成する必要があります。
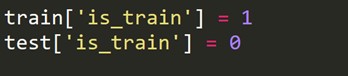
次に、トレインデータセットとテストデータセットを組み合わせます。
![]()
上記で新しく作成されたターゲット変数を使用して、分類モデルを適合させ、各行の確率がテストセットに含まれることを予測します。
6.時系列の相互検証
時系列データセットは、時間セクションがデータを台無しにするため、ランダムに分割することはできません。 時系列問題では、以下に示すように交差検定を実行します。
時系列の相互検証では、転送チェーンの方法でフォールドを作成します。
たとえば、n年間、特定の製品の年間消費者需要の時系列があるとします。 私たちはこのように折り目を作ります:
フォールド1:トレーニンググループ1、テストグループ2
フォールド2:トレーニンググループ1、2、テストグループ3
フォールド3:トレーニンググループ1、2、3、テストグループ4
フォールド4:トレーニンググループ1、2、3、4、テストグループ5
フォールド5:トレーニンググループ1、2、3、4、5、テストグループ6
。
。
。
フォールドn:トレーニンググループ1からn-1、テストグループn
新しいトレインとテストセットが徐々に選択されます。 最初に、モデルをフィッティングするために必要な最小限の観測数を持つトレインセットから始めます。 徐々に、すべての折り畳みで、私たちは列車とテストセットを変更します。
Rコードスニペット:

h = 1は、1ステップ先の予測の誤差を考慮に入れることを意味します。
世界のトップ大学からデータサイエンスコースを学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。
モデルの偏りと分散を測定する方法は?
k分割交差検定を使用すると、さまざまなkモデル推定誤差が得られます。 理想的なモデルの場合、誤差の合計はゼロになります。 モデルがバイアスを返すために、すべてのエラーの平均が取得され、スケーリングされます。 低い平均は、モデルにとってかなりのものと見なされます。
モデル分散の計算では、すべてのエラーの標準偏差を使用します。 標準偏差が小さい場合、トレーニングデータのサブセットが異なるとモデルは可変ではありません。
偏りと分散のバランスを取ることに焦点を当てる必要があります。 分散を減らし、モデルのバイアスを制御すると、ある程度平衡に達することができます。 最終的には、より良い予測のためのモデルが作成されます。
また読む: Pythonでの相互検証:あなたが知る必要があるすべて
まとめ
この記事では、交差検定とそのRでの適用について説明しました。また、過剰適合を回避する方法についても学びました。 また、検証セットアプローチ、LOOCV、k分割交差検証、層化k分割などのさまざまな手順について説明した後、Irisデータセットで実行されたRでの各アプローチの実装について説明しました。
Rプログラミングとは何ですか?
Rプログラミングは、計算言語であり、数学的分析、グラフィック表現、およびレポートに使用できるソフトウェア設定です。 ニュージーランドのオークランド大学でロス・イハカとロバート・ジェントルマンによって発明され、現在R開発コアチームが開発中です。 RプログラミングはGNUライセンスの下で公開されているソフトウェアであり、いくつかのオペレーティングシステム用にコンパイル済みのバイナリバージョンが利用可能です。
相互検証はどこで必要ですか?
機械学習のトレーニングデータにモデルを適合させることができない場合、モデルが実際のデータで効果的に動作することを保証できません。 そのためには、モデルがデータから正しいパターンを抽出し、過度のノイズを生成しないことを保証する必要があります。 このため、交差検定法を使用します。 モデルが正しいデータパターンを持ち、交差検定で過度のノイズを生成していないことを保証できます。
Rの用途は何ですか?
Rプログラミングは幅広い業界で使用されています。 統計計算と分析は、Rを使用する統計学者と学生によって実行されます。銀行、ヘルスケア、製造、ITセクター、金融、Eコマース、ソーシャルメディアなどのさまざまなセクターがRプログラミング言語を使用します。 Rは、記録管理や国勢調査処理などの政府の目的にも使用されます。