
Перекрестная проверка в R: использование, модели и измерения
Опубликовано: 2020-10-19Когда вы начинаете свое путешествие в мир науки о данных и машинного обучения, всегда есть тенденция начинать с создания моделей и алгоритмов. Вы склонны избегать изучения или знания того, как проверить эффективность моделей на реальных данных.
Перекрестная проверка в R — это тип проверки модели, который улучшает процессы проверки задержек, отдавая предпочтение подмножествам данных и понимая компромисс смещения или дисперсии, чтобы получить хорошее представление о производительности модели при применении за пределами данных, которые мы ее обучили. на. Эта статья будет начальным руководством по проверке модели данных и разъяснению необходимости проверки модели.
Оглавление
Нестабильность моделей обучения
Чтобы понять это, мы будем использовать эти изображения, чтобы проиллюстрировать соответствие кривой обучения различных моделей:
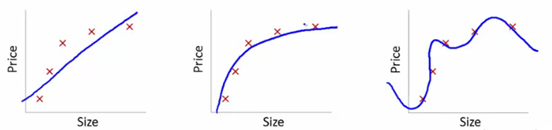
Источник
Мы показали здесь изученную модель зависимости цены товара от размера.
Мы составили уравнение линейного преобразования, подходящее между ними, чтобы показать графики.
Из тренировочных заданных точек первый график ошибочен. Таким образом, на тестовом наборе он работает не очень хорошо. Таким образом, можно сказать, что это «недообучение». Здесь модель не может понять фактическую закономерность в данных.
На следующем графике показана правильная зависимость цены от размера. Он изображает минимальную ошибку обучения. Таким образом, отношения являются обобщенными.
На последнем графике мы устанавливаем отношение, которое почти не имеет ошибки обучения. Мы строим взаимосвязь, рассматривая каждое колебание в точке данных и шум. Модель данных очень уязвима. Подгонка организуется так, чтобы свести к минимуму ошибку, тем самым создавая сложные шаблоны в данном наборе данных. Это известно как «Переоснащение». Здесь может быть более высокая разница между тренировочным и тестовым наборами.
В мире науки о данных среди различных моделей ищется модель, которая работает лучше. Но иногда трудно понять, связано ли это улучшение оценки с тем, что отношения фиксируются лучше, или просто с переобучением данных. Мы используем эти методы проверки, чтобы иметь правильные решения. При этом мы также получаем более обобщенный шаблон с помощью этих методов.
Что такое переобучение и недообучивание?
Недостаточное приспособление в машинном обучении относится к захвату недостаточных шаблонов. Когда мы запускаем модель на обучающих и тестовых наборах, она работает очень плохо.
Переоснащение в машинном обучении означает захват шума и закономерностей. Они плохо обобщаются на данные, которые не прошли обучение. Когда мы запускаем модель на тренировочном наборе, она работает очень хорошо, но плохо работает на тестовом наборе.
Что такое перекрестная проверка?
Перекрестная проверка направлена на проверку способности модели прогнозировать новые данные, не используемые при оценке, чтобы выявить такие проблемы, как переобучение или систематическая ошибка выбора. Также дается представление об обобщении базы данных.
Шаги по организации перекрестной проверки :
- Мы сохраняем набор данных в качестве образца.
- Мы проходим обучение модели с другой частью набора данных.
- Мы используем зарезервированный набор образцов для тестирования. Этот набор помогает количественно оценить убедительную производительность модели.
Проверка статистической модели
В статистике проверка модели подтверждает, что приемлемые результаты статистической модели получены из реальных данных. Это гарантирует, что выходные данные статистической модели получены из выходных данных процесса генерации данных, так что основные цели программы тщательно обрабатываются.
Проверка обычно проводится не только на основе данных, которые использовались при построении модели, но также использует данные, которые не использовались при построении. Таким образом, проверка обычно проверяет некоторые предсказания модели.
Какая польза от перекрестной проверки?
Перекрестная проверка в основном используется в прикладном машинном обучении для оценки навыков модели на будущих данных. То есть мы используем данную выборку, чтобы оценить, как модель обычно должна работать, делая прогнозы на неиспользованных данных во время обучения модели.
Уменьшает ли перекрестная проверка переоснащение?
Перекрестная проверка — сильное защитное действие против переобучения. Идея состоит в том, что мы используем наши исходные данные, используемые в обучающих наборах, для получения множества меньших разделений поезд-тест. Затем мы используем эти расщепления для настройки нашей модели. В обычной k-кратной перекрестной проверке мы делим данные на k подмножеств, которые затем называются складками.
Читайте: Зарплата разработчиков R в Индии
Методы, используемые для перекрестной проверки в R
Существует множество методов, которые специалисты по данным используют для повышения эффективности перекрестной проверки . Мы обсуждаем некоторые из них здесь.
1. Подход к набору валидации
Подход набора валидации — это метод, используемый для оценки частоты ошибок в модели путем создания набора данных для тестирования. Мы строим модель, используя другой набор наблюдений, также известный как набор обучающих данных. Затем результат модели применяется к набору данных тестирования. Затем мы можем рассчитать ошибку набора данных тестирования. Таким образом, это позволяет моделям не переобуваться.
R-код:
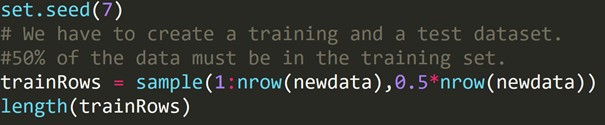
Мы написали приведенный выше код для создания набора данных для обучения и другого набора данных для тестирования. Поэтому мы используем обучающий набор данных для построения прогностической модели. Затем он будет применен к набору данных тестирования для проверки частоты ошибок.
2. Перекрестная проверка с исключением одного (LOOCV)
Перекрестная проверка с исключением одного (LOOCV) — это определенный многомерный тип перекрестной проверки k складок. Здесь количество складок и номер экземпляра в наборе данных совпадают. Для каждого экземпляра алгоритм обучения запускается только один раз. В статистике есть аналогичный процесс, называемый оценкой складного ножа.
Фрагмент кода R:
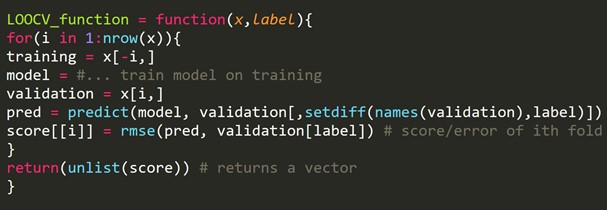
Мы можем опустить некоторые обучающие примеры, что создаст проверочный набор одинакового размера для каждой итерации. Этот процесс известен как LPOCV (Leave P Out Cross Validation).

3. Перекрестная проверка k-Fold
Процедура повторной выборки использовалась в ограниченной выборке данных для оценки моделей машинного обучения.
Процедура начинается с определения одного параметра, который относится к числу групп, на которые должна быть разделена данная выборка данных. Таким образом, эта процедура называется k-fold Cross-Validation .
Исследователи данных часто используют перекрестную проверку в прикладном машинном обучении для оценки характеристик модели машинного обучения на неиспользуемых данных.
Это сравнительно просто понять. Это часто приводит к менее предвзятой или переобученной оценке навыков модели, такой как простой набор поездов или тестовый набор.
Общая процедура состоит из нескольких простых шагов:
- Мы должны смешать набор данных, чтобы рандомизировать его.
- Затем мы разделяем набор данных на k групп одинакового размера.
- Для каждой уникальной группы:
Мы должны взять группу в качестве определенного набора тестовых данных. Затем мы рассматриваем все оставшиеся группы как единое обучающее множество данных. Затем мы подгоняем модель к тренировочному набору и подтверждаем результат. Мы запускаем его на тестовом наборе. Записываем оценочный балл.
Фрагмент кода R:

4. Стратифицированная k-кратная перекрестная проверка
Стратификация — это перегруппировка данных, чтобы убедиться, что каждая складка является полноценным представителем. Рассмотрим задачу бинарной классификации, в которой каждый класс состоит из 50 % данных.
При работе как со смещением, так и с дисперсией стратифицированная k-кратная перекрестная проверка является лучшим методом.
Фрагмент кода R:

5. Состязательная проверка
Основная идея заключается в проверке процента сходства признаков и их распределения между обучением и тестами. Если их нелегко отличить, распределение во всех смыслах похоже, и общие методы проверки должны сработать.
При работе с фактическими наборами данных иногда бывают случаи, когда наборы тестов и наборы поездов сильно различаются. Внутренние методы перекрестной проверки генерируют баллы, выходящие за рамки результатов теста. Здесь в игру вступает состязательная проверка.
Он проверяет степень сходства в рамках обучения и тестов относительно распределения признаков. Эта проверка характеризуется объединением наборов поездов и тестов, маркировкой нуля или единицы (ноль - поезд, один тест) и анализом задачи классификации двоичных оценок.
Мы должны создать новую целевую переменную, которая равна 1 для каждой строки в наборе поездов и 0 для каждой строки в тестовом наборе.
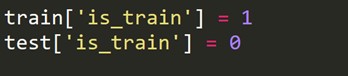
Теперь мы объединяем наборы данных поезда и теста.
![]()
Используя вышеприведенную вновь созданную целевую переменную, мы подгоняем модель классификации и прогнозируем вероятность того, что каждая строка будет в тестовом наборе.
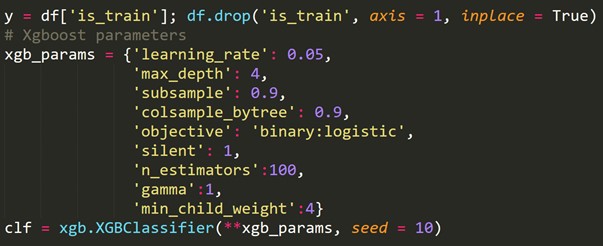
6. Перекрестная проверка временных рядов
Набор данных временных рядов не может быть разделен случайным образом, поскольку временной раздел искажает данные. В задаче временных рядов мы выполняем перекрестную проверку, как показано ниже.
Для перекрестной проверки временных рядов мы создаем складки в виде цепочек пересылки.
Если, например, за n лет у нас есть временной ряд годового потребительского спроса на тот или иной товар. Складки делаем так:
1 раз: тренировочная группа 1, тестовая группа 2
складка 2: тренировочная группа 1,2, тестовая группа 3
складка 3: тренировочная группа 1,2,3, тестовая группа 4
складка 4: тренировочная группа 1,2,3,4, тестовая группа 5
складка 5: тренировочная группа 1,2,3,4,5, тестовая группа 6
.
.
.
сложите n: тренировочная группа с 1 по n-1, тестовая группа n
Постепенно выбираются новый поезд и тестовый набор. Первоначально мы начинаем с набора поездов с минимальным количеством наблюдений, необходимых для подбора модели. Постепенно, с каждым разом, мы меняем наши наборы поездов и тестов.
Фрагмент кода R:

h = 1 означает, что мы учитываем ошибку для прогнозов на 1 шаг вперед.
Изучите курсы по науке о данных в лучших университетах мира. Участвуйте в программах Executive PG, Advanced Certificate Programs или Master Programs, чтобы ускорить свою карьеру.
Как измерить дисперсию смещения модели?
С k-кратной перекрестной проверкой мы получаем различные k ошибок оценки модели. Для идеальной модели сумма ошибок равна нулю. Чтобы модель вернула свое смещение, берется среднее значение всех ошибок и масштабируется. Нижний средний показатель считается заметным для модели.
Для расчета дисперсии модели мы берем стандартное отклонение всех ошибок. Наша модель не является переменной с различными подмножествами обучающих данных, если стандартное отклонение незначительно.
В центре внимания должен быть баланс между предвзятостью и дисперсией. Если мы уменьшим дисперсию и контролируем смещение модели, мы сможем в некоторой степени достичь равновесия. В конечном итоге он создаст модель для лучшего прогнозирования.
Читайте также: Перекрестная проверка в Python: все, что вам нужно знать
Подведение итогов
В этой статье мы обсудили перекрестную проверку и ее применение в R. Мы также узнали, как избежать переобучения. Мы также обсудили различные процедуры, такие как подход с набором проверочных данных, LOOCV, k-кратную перекрестную проверку и стратифицированную k-кратную, после чего последовала реализация каждого подхода в R, выполненная для набора данных Iris.
Что такое R-программирование?
Программирование R — это язык вычислений и настройка программного обеспечения, которые можно использовать для математического анализа, графического представления и составления отчетов. Он был изобретен в Университете Окленда в Новой Зеландии Россом Ихакой и Робертом Джентльменом, и в настоящее время его разрабатывает основная группа разработчиков R. Программирование на R является общедоступным программным обеспечением под лицензией GNU, и доступны предварительно скомпилированные двоичные версии для нескольких операционных систем.
Где требуется перекрестная проверка?
Когда мы не можем подогнать модель к обучающим данным в машинном обучении, мы не можем гарантировать, что модель будет эффективно работать с реальными данными. Для этого мы должны гарантировать, что наша модель извлекает из данных правильные шаблоны и не создает чрезмерного шума. По этой причине мы используем метод перекрестной проверки. Мы можем гарантировать, что наши модели имеют правильную структуру данных и не создают чрезмерного шума при перекрестной проверке.
Каковы приложения R?
Программирование на R используется в самых разных отраслях. Статистические расчеты и анализ выполняются статистиками и студентами с использованием R. В различных секторах, таких как банковское дело, здравоохранение, производство, ИТ-сектор, финансы, электронная коммерция и социальные сети, используется язык программирования R. R даже используется в правительственных целях, таких как ведение записей и обработка переписи.