
Validação cruzada em R: uso, modelos e medição
Publicados: 2020-10-19Quando você embarca em sua jornada no mundo da ciência de dados e aprendizado de máquina, sempre há uma tendência de começar com a criação de modelos e algoritmos. Você tende a evitar aprender ou saber como testar a eficácia dos modelos em dados do mundo real.
A validação cruzada em R é um tipo de validação de modelo que melhora os processos de validação de hold-out, dando preferência a subconjuntos de dados e entendendo a compensação de viés ou variância para obter uma boa compreensão do desempenho do modelo quando aplicado além dos dados que treinamos em. Este artigo será um guia do início ao fim para a validação do modelo de dados e elucidará a necessidade de validação do modelo.
Índice
A instabilidade dos modelos de aprendizagem
Para entender isso, usaremos essas imagens para ilustrar o ajuste da curva de aprendizado de vários modelos:
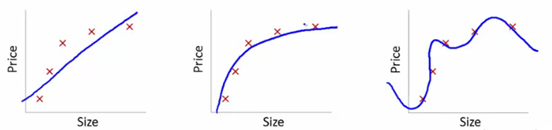
Fonte
Mostramos aqui o modelo aprendido de dependência do preço do artigo em relação ao tamanho.
Fizemos uma equação de transformação linear ajustando-se entre elas para mostrar os gráficos.
A partir de pontos de ajuste de treinamento, o primeiro gráfico é errôneo. Assim, no conjunto de teste, ele não tem um ótimo desempenho. Então, podemos dizer que isso é “Underfitting”. Aqui, o modelo não é capaz de entender o padrão real nos dados.
O próximo gráfico mostra a dependência correta do preço em relação ao tamanho. Ele descreve o erro de treinamento mínimo. Assim, a relação é generalizada.
No último gráfico, estabelecemos uma relação que quase não tem erro de treinamento. Construímos a relação considerando cada flutuação no ponto de dados e o ruído. O modelo de dados é muito vulnerável. O ajuste se organiza para minimizar o erro, gerando padrões complicados no conjunto de dados fornecido. Isso é conhecido como “overfitting”. Aqui, pode haver uma diferença maior entre os conjuntos de treinamento e teste.
No mundo da ciência de dados, entre vários modelos, há uma busca por um modelo com melhor desempenho. Mas, às vezes, é difícil entender se essa pontuação aprimorada é porque o relacionamento é capturado melhor ou apenas porque os dados são superajustados. Usamos essas técnicas de validação para ter as soluções corretas. Com isso, também obtemos um padrão mais generalizado por meio dessas técnicas.
O que é Overfitting e Underfitting?
Underfitting no aprendizado de máquina refere-se à captura de padrões insuficientes. Quando executamos o modelo em conjuntos de treinamento e teste, ele apresenta um desempenho muito ruim.
O overfitting no aprendizado de máquina significa capturar ruídos e padrões. Estes não generalizam bem para os dados que não foram treinados. Quando executamos o modelo no conjunto de treinamento, ele tem um desempenho extremamente bom, mas um desempenho ruim quando executado no conjunto de teste.
O que é validação cruzada?
A validação cruzada visa testar a capacidade do modelo de fazer uma previsão de novos dados não usados na estimativa, de modo que problemas como overfitting ou viés de seleção sejam sinalizados. Além disso, é fornecida uma visão sobre a generalização do banco de dados.
Etapas para organizar a validação cruzada :
- Mantemos de lado um conjunto de dados como uma amostra de amostra.
- Passamos pelo treinamento do modelo com a outra parte do conjunto de dados.
- Usamos o conjunto de amostras reservado para teste. Este conjunto ajuda a quantificar o desempenho atraente do modelo.
Validação do modelo estatístico
Em estatística, a validação do modelo confirma que as saídas aceitáveis de um modelo estatístico são geradas a partir dos dados reais. Ele garante que as saídas do modelo estatístico sejam derivadas das saídas do processo de geração de dados para que os principais objetivos do programa sejam completamente processados.
A validação geralmente não é avaliada apenas em dados que foram usados na construção do modelo, mas também em dados que não foram usados na construção. Assim, a validação geralmente testa algumas das previsões do modelo.
Para que serve a validação cruzada?
A validação cruzada é usada principalmente no aprendizado de máquina aplicado para estimar a habilidade do modelo em dados futuros. Ou seja, usamos uma determinada amostra para estimar o desempenho geral do modelo enquanto fazemos previsões sobre dados não utilizados durante o treinamento do modelo.
A validação cruzada reduz o overfitting?
A validação cruzada é uma forte ação de proteção contra overfitting. A ideia é que usemos nossos dados iniciais usados em conjuntos de treinamento para obter muitas divisões de teste de treinamento menores. Em seguida, usamos essas divisões para ajustar nosso modelo. Na validação cruzada normal de k dobras , dividimos os dados em k subconjuntos que são então chamados de dobras.
Leia: Salário R Developer na Índia
Métodos usados para validação cruzada em R
Existem muitos métodos que os cientistas de dados usam para o desempenho da validação cruzada . Discutimos alguns deles aqui.
1. Abordagem do Conjunto de Validação
A abordagem do conjunto de validação é um método usado para estimar a taxa de erro em um modelo criando um conjunto de dados de teste. Construímos o modelo usando o outro conjunto de observações, também conhecido como conjunto de dados de treinamento. O resultado do modelo é então aplicado ao conjunto de dados de teste. Podemos então calcular o erro do conjunto de dados de teste. Assim, permite que os modelos não se sobreponham.
Código R:
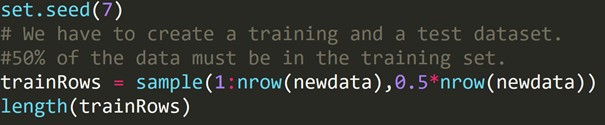
Escrevemos o código acima para criar um conjunto de dados de treinamento e um conjunto de dados de teste diferente. Portanto, usamos o conjunto de dados de treinamento para construir um modelo preditivo. Em seguida, ele será aplicado ao conjunto de dados de teste para verificar as taxas de erro.
2. Validação cruzada leave-one-out (LOOCV)
A validação cruzada leave-one-out (LOOCV) é um certo tipo multidimensional de validação cruzada de k dobras. Aqui, o número de dobras e o número de instância no conjunto de dados são os mesmos. Para cada instância, o algoritmo de aprendizado é executado apenas uma vez. Em estatística, existe um processo semelhante chamado estimativa de canivete.
Trecho de código R:
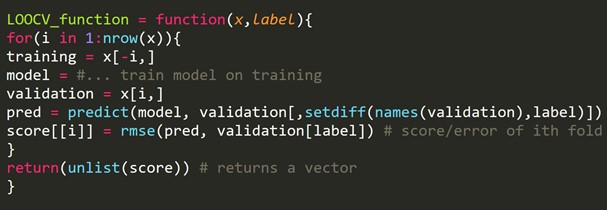
Podemos deixar de fora alguns exemplos de treinamento, que criarão um conjunto de validação do mesmo tamanho para cada iteração. Este processo é conhecido como LPOCV (Leave P Out Cross Validation)

3. Validação cruzada k-fold
Um procedimento de reamostragem foi usado em uma amostra de dados limitada para a avaliação de modelos de aprendizado de máquina.
O procedimento começa com a definição de um único parâmetro, que se refere ao número de grupos que uma determinada amostra de dados deve ser dividida. Assim, este procedimento é denominado como k-fold Cross-Validation .
Os cientistas de dados costumam usar a validação cruzada no aprendizado de máquina aplicado para estimar os recursos de um modelo de aprendizado de máquina em dados não utilizados.
É relativamente simples de entender. Isso geralmente resulta em uma estimativa menos tendenciosa ou superajustada da habilidade do modelo, como um conjunto de treinamento simples ou conjunto de teste.
O procedimento geral é construído com alguns passos simples:
- Temos que misturar o conjunto de dados para torná-lo aleatório.
- Em seguida, dividimos o conjunto de dados em k grupos de tamanho semelhante.
- Para cada grupo exclusivo:
Temos que tomar um grupo como um conjunto de dados de teste específico. Em seguida, consideramos todos os grupos restantes como um conjunto de dados de treinamento completo. Em seguida, ajustamos um modelo no conjunto de treinamento e confirmamos o resultado. Nós o executamos no conjunto de teste. Anotamos a nota de avaliação.
Fragmento de código R:

4. Validação cruzada de k-fold estratificada
A estratificação é um rearranjo de dados para garantir que cada dobra seja um representante saudável. Considere um problema de classificação binária, tendo cada classe de 50% de dados.
Ao lidar com viés e variância, a validação cruzada de k-folds estratificada é o melhor método.
Trecho de código R:

5. Validação Adversária
A ideia básica é verificar a porcentagem de similaridade nas características e sua distribuição entre treinamento e testes. Se eles não forem fáceis de diferenciar, a distribuição é, por todos os meios, semelhante, e os métodos gerais de validação devem funcionar.
Ao lidar com conjuntos de dados reais, às vezes há casos em que os conjuntos de teste e os conjuntos de treinamento são muito diferentes. As técnicas internas de validação cruzada geram pontuações, não dentro da arena da pontuação do teste. Aqui, a validação adversária entra em jogo.
Ele verifica o grau de similaridade dentro do treinamento e testes em relação à distribuição de recursos. Essa validação é caracterizada pela mesclagem de conjuntos de trem e teste, rotulando zero ou um (zero – trem, um-teste) e analisando uma tarefa de classificação de pontuações binárias.
Temos que criar uma nova variável de destino que é 1 para cada linha no conjunto de trens e 0 para cada linha no conjunto de teste.
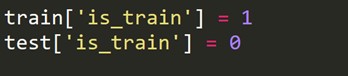
Agora combinamos os conjuntos de dados de treinamento e teste.
![]()
Usando a variável de destino recém-criada acima, ajustamos um modelo de classificação e prevemos as probabilidades de cada linha de estar no conjunto de teste.
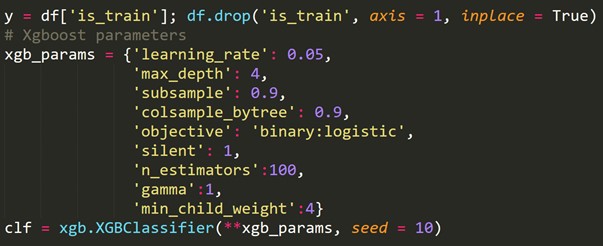
6. Validação cruzada para séries temporais
Um conjunto de dados de série temporal não pode ser dividido aleatoriamente, pois a seção de tempo atrapalha os dados. Em um problema de série temporal, realizamos a validação cruzada conforme mostrado abaixo.
Para validação cruzada de séries temporais , criamos dobras na forma de cadeias de encaminhamento.
Se, por exemplo, para n anos, tivermos uma série temporal para a demanda anual do consumidor por um determinado produto. Fazemos as dobras assim:
dobra 1: grupo de treinamento 1, grupo de teste 2
dobra 2: grupo de treinamento 1,2, grupo de teste 3
dobra 3: grupo de treinamento 1,2,3, grupo de teste 4
dobra 4: grupo de treinamento 1,2,3,4, grupo de teste 5
dobra 5: grupo de treinamento 1,2,3,4,5, grupo de teste 6
.
.
.
fold n: grupo de treinamento 1 a n-1, grupo de teste n
Um novo conjunto de treinamento e teste é selecionado progressivamente. Inicialmente, começamos com um conjunto de trens com um número mínimo de observações necessárias para o ajuste do modelo. Gradualmente, a cada dobra, mudamos nossos conjuntos de trem e teste.
Trecho de código R:

h = 1 significa que levamos em consideração o erro para previsões de 1 passo à frente.
Aprenda cursos de ciência de dados das melhores universidades do mundo. Ganhe Programas PG Executivos, Programas de Certificado Avançado ou Programas de Mestrado para acelerar sua carreira.
Como medir a variância de viés do modelo?
Com k-fold Cross-Validation , obtemos vários k erros de estimativa do modelo. Para um modelo ideal, os erros somam zero. Para que o modelo retorne seu viés, a média de todos os erros é obtida e dimensionada. A média mais baixa é considerada apreciável para o modelo.
Para o cálculo da variância do modelo, tomamos o desvio padrão de todos os erros. Nosso modelo não é variável com diferentes subconjuntos de dados de treinamento se o desvio padrão for menor.
O foco deve estar em ter um equilíbrio entre viés e variância. Se reduzirmos a variância e o viés do modelo de controle, podemos alcançar o equilíbrio até certo ponto. Ele acabará por fazer um modelo para uma melhor previsão.
Leia também: Validação cruzada em Python: tudo o que você precisa saber
Empacotando
Neste artigo, discutimos a validação cruzada e sua aplicação em R. Também aprendemos métodos para evitar o overfitting. Também discutimos diferentes procedimentos como a abordagem do conjunto de validação, LOOCV, k-fold Cross-Validation e k-fold estratificado, seguidos pela implementação de cada abordagem em R realizada no conjunto de dados Iris.
O que é programação R?
A programação R é uma linguagem de computação e uma configuração de software que pode ser usada para análise matemática, representação gráfica e relatórios. Foi inventado na Universidade de Auckland, na Nova Zelândia, por Ross Ihaka e Robert Gentleman, e o R Development Core Team está atualmente desenvolvendo-o. A programação R é um software disponível abertamente sob a licença GNU e versões binárias pré-compiladas para vários sistemas operacionais estão disponíveis.
Onde é necessária a validação cruzada?
Quando não conseguimos ajustar o modelo aos dados de treinamento no aprendizado de máquina, não podemos garantir que o modelo opere efetivamente em dados reais. Para isso, devemos garantir que nosso modelo extraiu os padrões corretos dos dados e não gerou ruído excessivo. Por esse motivo, usamos o método de validação cruzada. Podemos garantir que nossos modelos tenham o padrão de dados correto e não estejam gerando ruído excessivo com validação cruzada.
Quais são as aplicações do R?
A programação R é usada em uma ampla gama de indústrias. Cálculos e análises estatísticas são realizados por estatísticos e estudantes usando R. Diferentes setores como Banco, Saúde, Manufatura, Setor de TI, Finanças, E-commerce e Mídias Sociais fazem uso da linguagem de programação R. O R é usado até mesmo para fins governamentais, como manutenção de registros e processamento de censos.