
R 中的交叉驗證:使用、模型和測量
已發表: 2020-10-19當您踏上數據科學和機器學習世界的旅程時,總是傾向於從模型創建和算法開始。 您傾向於避免學習或知道如何在真實數據中測試模型的有效性。
R 中的交叉驗證是一種模型驗證,它通過優先考慮數據子集並理解偏差或方差權衡來改進保留驗證過程,以便在應用超出我們訓練的數據時獲得對模型性能的良好理解在。 本文將作為數據模型驗證的自始至終指南,並闡明模型驗證的必要性。
目錄
學習模型的不穩定性
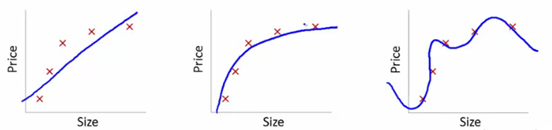
為了理解這一點,我們將使用這些圖片來說明各種模型的學習曲線擬合:
資源
我們在這裡展示了文章價格依賴於大小的學習模型。
我們在這些之間建立了一個線性變換方程來顯示這些圖。
從訓練集點來看,第一個圖是錯誤的。 因此,在測試集上,它的表現並不好。 所以,我們可以說這是“欠擬合”。 在這裡,模型無法理解數據中的實際模式。
下圖顯示了價格對大小的正確依賴性。 它描述了最小的訓練錯誤。 因此,這種關係是廣義的。
在最後一個圖中,我們建立了一個幾乎沒有訓練誤差的關係。 我們通過考慮數據點的每個波動和噪聲來建立這種關係。 數據模型非常脆弱。 擬合會自行安排以最小化誤差,從而在給定數據集中生成複雜的模式。 這被稱為“過度擬合”。 在這裡,訓練集和測試集之間可能存在更大的差異。
在數據科學的世界中,在各種模型中,總有人在尋找性能更好的模型。 但有時,很難理解這種提高的分數是因為更好地捕捉到了關係,還是僅僅因為數據過度擬合。 我們使用這些驗證技術來獲得正確的解決方案。 因此,我們還通過這些技術獲得了更好的泛化模式。
什麼是過擬合和欠擬合?
機器學習中的欠擬合是指捕獲不足的模式。 當我們在訓練集和測試集上運行模型時,它的表現非常糟糕。
機器學習中的過度擬合意味著捕獲噪聲和模式。 這些不能很好地推廣到沒有經過訓練的數據。 當我們在訓練集上運行模型時,它表現得非常好,但在測試集上運行時表現不佳。
什麼是交叉驗證?
交叉驗證旨在測試模型對未用於估計的新數據進行預測的能力,以便標記過度擬合或選擇偏差等問題。 此外,還給出了關於數據庫泛化的見解。
組織交叉驗證的步驟:
- 我們保留一個數據集作為樣本。
- 我們使用數據集的另一部分進行模型訓練。
- 我們使用保留的樣本集進行測試。 這組有助於量化模型的引人注目的性能。
統計模型驗證
在統計中,模型驗證確認統計模型的可接受輸出是從真實數據生成的。 它確保統計模型輸出來自數據生成過程的輸出,以便徹底處理程序的主要目標。
驗證通常不僅對模型構建中使用的數據進行評估,而且還使用構建中未使用的數據。 因此,驗證通常會測試模型的一些預測。
交叉驗證有什麼用?
交叉驗證主要用於應用機器學習,以估計模型對未來數據的技能。 也就是說,我們使用給定的樣本來估計模型在模型訓練期間對未使用的數據進行預測時通常預期的表現。
交叉驗證會減少過擬合嗎?
交叉驗證是防止過度擬合的強有力的保護措施。 這個想法是我們使用我們在訓練集中使用的初始數據來獲得許多較小的訓練測試分割。 然後我們使用這些拆分來調整我們的模型。 在正常的 k-fold交叉驗證中,我們將數據分成 k 個子集,然後稱為折疊。
閱讀:印度的 R 開發人員薪水
R中用於交叉驗證的方法
數據科學家有許多方法用於交叉驗證性能。 我們在這裡討論其中的一些。
1. 驗證集方法
驗證集方法是一種通過創建測試數據集來估計模型中錯誤率的方法。 我們使用另一組觀察結果構建模型,也稱為訓練數據集。 然後將模型結果應用於測試數據集。 然後我們可以計算測試數據集的誤差。 因此,它允許模型不會過度擬合。
代碼:
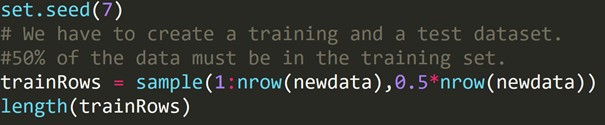
我們編寫了上面的代碼來創建一個訓練數據集和一個不同的測試數據集。 因此,我們使用訓練數據集來構建預測模型。 然後將其應用於測試數據集以檢查錯誤率。
2. 留一法交叉驗證(LOOCV)
留一法交叉驗證(LOOCV)是某種多維類型的 k 折交叉驗證。 這裡的折疊數和數據集中的實例數是相同的。 對於每個實例,學習算法只運行一次。 在統計學中,有一個類似的過程稱為折刀估計。
R 代碼片段:
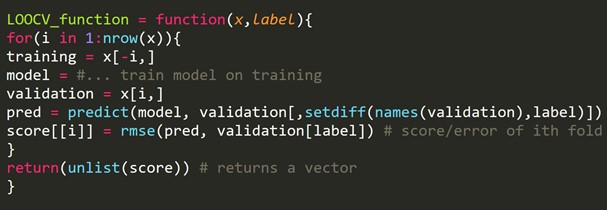
我們可以省略一些訓練示例,這將為每次迭代創建一個相同大小的驗證集。 這個過程被稱為 LPOCV(Leave P Out Cross Validation)

3. k 折交叉驗證
在有限的數據樣本中使用重採樣程序來評估機器學習模型。
該過程從定義單個參數開始,該參數指的是給定數據樣本要拆分的組數。 因此,這個過程被命名為 k-fold Cross-Validation 。
數據科學家經常在應用機器學習中使用交叉驗證來估計機器學習模型在未使用數據上的特徵。
理解起來比較簡單。 它通常會導致對模型技能的偏差較小或過度擬合的估計,例如簡單的訓練集或測試集。
一般程序由幾個簡單的步驟組成:
- 我們必須混合數據集以使其隨機化。
- 然後我們將數據集分成大小相似的 k 組。
- 對於每個唯一組:
我們必須將一個組作為一個特定的測試數據集。 然後我們將所有剩餘的組視為一個完整的訓練數據集。 然後我們在訓練集上擬合一個模型並確認結果。 我們在測試集上運行它。 我們記下評估分數。
R代碼片段:

4. 分層 k 折交叉驗證
分層是對數據的重新排列,以確保每個折疊都是有益的代表。 考慮一個二元分類問題,每類有 50% 的數據。
在處理偏差和方差時,分層 k 折交叉驗證是最好的方法。
R 代碼片段:

5. 對抗性驗證
基本思想是檢查特徵相似性的百分比及其在訓練和測試之間的分佈。 如果它們不容易區分,那麼分佈無論如何都是相似的,並且一般的驗證方法應該可行。
在處理實際數據集時,有時測試集和訓練集有很大不同。 內部交叉驗證技術生成分數,而不是在測試分數的範圍內。 在這裡,對抗性驗證開始發揮作用。
它檢查有關特徵分佈的訓練和測試中的相似度。 此驗證的特點是合併訓練集和測試集,標記零或一(零 - 訓練,一測試),以及分析二進制分數的分類任務。
我們必須創建一個新的目標變量,訓練集中的每一行為 1,測試集中的每一行為 0。
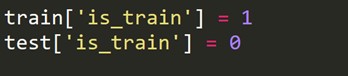
現在我們結合訓練和測試數據集。
![]()
使用上面新創建的目標變量,我們擬合一個分類模型並預測每一行在測試集中的概率。
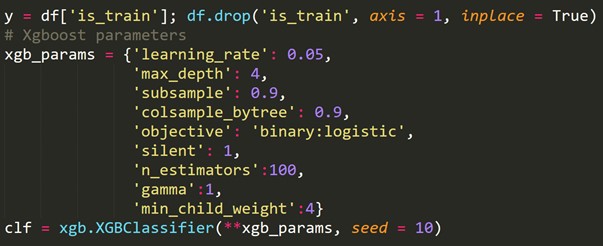
6.時間序列的交叉驗證
時間序列數據集不能隨機拆分,因為時間段會弄亂數據。 在時間序列問題中,我們執行如下所示的交叉驗證。
對於時間序列交叉驗證,我們以轉發鏈的方式創建折疊。
例如,如果對於 n 年,我們有一個特定產品的年度消費者需求的時間序列。 我們做這樣的折疊:
折疊 1:訓練組 1,測試組 2
fold 2:訓練組 1,2,測試組 3
fold 3:訓練組 1,2,3,測試組 4
fold 4:訓練組 1,2,3,4,測試組 5
5折:訓練組1、2、3、4、5,測試組6
.
.
.
fold n:訓練組 1 到 n-1,測試組 n
逐步選擇新的訓練集和測試集。 最初,我們從一個訓練集開始,該訓練集具有擬合模型所需的最少觀察次數。 逐漸地,隨著每一折,我們改變我們的訓練和測試集。
R 代碼片段:

h = 1 意味著我們考慮了提前 1 步預測的誤差。
學習世界頂尖大學的數據科學課程。 獲得行政 PG 課程、高級證書課程或碩士課程,以加快您的職業生涯。
如何衡量模型的偏差方差?
通過 k-fold Cross-Validation ,我們獲得了各種 k 模型估計誤差。 對於理想模型,誤差總和為零。 為了使模型返回其偏差,所有誤差的平均值被取並縮放。 該模型認為較低的平均值是可觀的。
對於模型方差計算,我們取所有誤差的標準差。 如果標準偏差很小,我們的模型不會隨著訓練數據的不同子集而變化。
重點應該是在偏差和方差之間取得平衡。 如果我們減少方差並控制模型偏差,我們可以在一定程度上達到平衡。 它最終會為更好的預測建立一個模型。
另請閱讀: Python 中的交叉驗證:您需要知道的一切
包起來
在本文中,我們討論了交叉驗證及其在 R 中的應用。我們還學習了避免過度擬合的方法。 我們還討論了不同的過程,例如驗證集方法、LOOCV、k-fold Cross-Validation和分層 k-fold,然後是在 Iris 數據集上執行的每種方法在 R 中的實現。
什麼是 R 編程?
R 編程是一種計算語言和軟件設置,可用於數學分析、圖形表示和報告。 它是由 Ross Ihaka 和 Robert Gentleman 在新西蘭奧克蘭大學發明的,目前 R 開發核心團隊正在開發它。 R 編程是一個在 GNU 許可下開放可用的軟件,並且可以使用用於多個操作系統的預編譯二進製版本。
哪裡需要交叉驗證?
當我們無法將模型擬合到機器學習中的訓練數據上時,我們無法保證模型能夠在真實數據上有效運行。 為此,我們必須保證我們的模型從數據中提取了正確的模式並且不會產生過多的噪聲。 為此,我們使用交叉驗證方法。 我們可以保證我們的模型具有正確的數據模式,並且不會通過交叉驗證產生過多的噪聲。
R的應用有哪些?
R 編程用於廣泛的行業。 統計人員和學生使用 R 進行統計計算和分析。銀行、醫療保健、製造、IT 部門、金融、電子商務和社交媒體等不同部門都使用 R 編程語言。 R 甚至用於記錄保存和人口普查處理等政府目的。