
Validación cruzada en R: uso, modelos y medidas
Publicado: 2020-10-19Cuando se embarca en su viaje al mundo de la ciencia de datos y el aprendizaje automático, siempre hay una tendencia a comenzar con la creación de modelos y algoritmos. Tiende a evitar aprender o saber cómo probar la efectividad de los modelos en datos del mundo real.
La validación cruzada en R es un tipo de validación de modelos que mejora los procesos de validación de espera dando preferencia a los subconjuntos de datos y comprendiendo el sesgo o la compensación de la varianza para obtener una buena comprensión del rendimiento del modelo cuando se aplica más allá de los datos que entrenamos. en. Este artículo será una guía de principio a fin para la validación del modelo de datos y aclarará la necesidad de la validación del modelo.
Tabla de contenido
La inestabilidad de los modelos de aprendizaje
Para entender esto, usaremos estas imágenes para ilustrar el ajuste de la curva de aprendizaje de varios modelos:
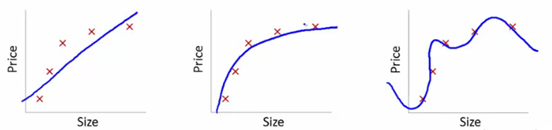
Fuente
Hemos mostrado aquí el modelo aprendido de dependencia del precio del artículo sobre el tamaño.
Hicimos una ecuación de transformación lineal que se ajustaba entre estos para mostrar las gráficas.
A partir de los puntos de ajuste de entrenamiento, el primer gráfico es erróneo. Por lo tanto, en el conjunto de prueba, no funciona muy bien. Entonces, podemos decir que esto es "Underfitting". Aquí, el modelo no puede comprender el patrón real en los datos.
El siguiente gráfico muestra la dependencia correcta del precio del tamaño. Representa un error de entrenamiento mínimo. Por lo tanto, la relación es generalizada.
En el último gráfico, establecemos una relación que casi no tiene ningún error de entrenamiento. Construimos la relación considerando cada fluctuación en el punto de datos y el ruido. El modelo de datos es muy vulnerable. El ajuste se organiza para minimizar el error, generando patrones complicados en el conjunto de datos dado. Esto se conoce como "Sobreajuste". Aquí, podría haber una mayor diferencia entre los conjuntos de entrenamiento y prueba.
En el mundo de la ciencia de datos, entre varios modelos, se busca un modelo que funcione mejor. Pero a veces, es difícil entender si esta puntuación mejorada se debe a que la relación se captura mejor o simplemente a que los datos se ajustan demasiado. Usamos estas técnicas de validación para tener las soluciones correctas. Adjunto también obtenemos un patrón mejor generalizado a través de estas técnicas.
¿Qué es Overfitting & Underfitting?
El desajuste en el aprendizaje automático se refiere a la captura de patrones insuficientes. Cuando ejecutamos el modelo en conjuntos de entrenamiento y prueba, funciona muy mal.
El sobreajuste en el aprendizaje automático significa capturar el ruido y los patrones. Estos no se generalizan bien a los datos que no se sometieron a entrenamiento. Cuando ejecutamos el modelo en el conjunto de entrenamiento, funciona extremadamente bien, pero funciona mal cuando se ejecuta en el conjunto de prueba.
¿Qué es la validación cruzada?
La validación cruzada tiene como objetivo probar la capacidad del modelo para hacer una predicción de nuevos datos no utilizados en la estimación, de modo que se marquen problemas como el sobreajuste o el sesgo de selección. Además, se da una idea de la generalización de la base de datos.
Pasos para organizar la validación cruzada :
- Reservamos un conjunto de datos como muestra.
- Nos sometemos al entrenamiento del modelo con la otra parte del conjunto de datos.
- Utilizamos el conjunto de muestras reservado para las pruebas. Este conjunto ayuda a cuantificar el rendimiento convincente del modelo.
Validación de modelos estadísticos
En estadística, la validación del modelo confirma que los resultados aceptables de un modelo estadístico se generan a partir de datos reales. Se asegura de que los resultados del modelo estadístico se deriven de los resultados del proceso de generación de datos para que los objetivos principales del programa se procesen a fondo.
Por lo general, la validación no solo se evalúa en los datos que se usaron en la construcción del modelo, sino que también usa datos que no se usaron en la construcción. Entonces, la validación generalmente prueba algunas de las predicciones del modelo.
¿Cuál es el uso de la validación cruzada?
La validación cruzada se usa principalmente en el aprendizaje automático aplicado para estimar la habilidad del modelo en datos futuros. Es decir, usamos una muestra dada para estimar cómo se espera que funcione el modelo en general mientras hacemos predicciones sobre los datos no utilizados durante el entrenamiento del modelo.
¿La validación cruzada reduce el sobreajuste?
La validación cruzada es una fuerte acción protectora contra el sobreajuste. La idea es que usemos nuestros datos iniciales utilizados en conjuntos de entrenamiento para obtener muchas divisiones de prueba de tren más pequeñas. Luego usamos estas divisiones para ajustar nuestro modelo. En la validación cruzada normal de k-pliegues , dividimos los datos en k subconjuntos que luego se denominan pliegues.
Leer: Salario de desarrollador R en India
Métodos utilizados para la validación cruzada en R
Hay muchos métodos que los científicos de datos utilizan para el rendimiento de la validación cruzada . Discutimos algunos de ellos aquí.
1. Enfoque del conjunto de validación
El enfoque del conjunto de validación es un método utilizado para estimar la tasa de error en un modelo mediante la creación de un conjunto de datos de prueba. Construimos el modelo usando el otro conjunto de observaciones, también conocido como el conjunto de datos de entrenamiento. El resultado del modelo se aplica luego al conjunto de datos de prueba. Entonces podemos calcular el error del conjunto de datos de prueba. Por lo tanto, permite que los modelos no se sobreajusten.
Código R:
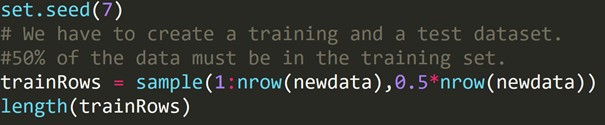
Hemos escrito el código anterior para crear un conjunto de datos de entrenamiento y un conjunto de datos de prueba diferente. Por lo tanto, usamos el conjunto de datos de entrenamiento para construir un modelo predictivo. Luego se aplicará al conjunto de datos de prueba para verificar las tasas de error.
2. Validación cruzada de dejar uno fuera (LOOCV)
La validación cruzada Leave-one-out (LOOCV) es un cierto tipo multidimensional de validación cruzada de k pliegues. Aquí el número de pliegues y el número de instancia en el conjunto de datos son los mismos. Para cada instancia, el algoritmo de aprendizaje se ejecuta solo una vez. En estadística, existe un proceso similar llamado estimación de navaja.
Fragmento de código R:
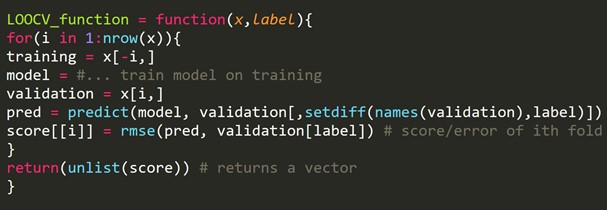
Podemos omitir algunos ejemplos de entrenamiento, que crearán un conjunto de validación del mismo tamaño para cada iteración. Este proceso se conoce como LPOCV (Leave P Out Cross Validation)

3. Validación cruzada de k-fold
Se utilizó un procedimiento de remuestreo en una muestra de datos limitada para la evaluación de modelos de aprendizaje automático.
El procedimiento comienza con la definición de un único parámetro, que se refiere al número de grupos en los que se dividirá una muestra de datos determinada. Por lo tanto, este procedimiento se denomina validación cruzada de k-fold .
Los científicos de datos a menudo usan la validación cruzada en el aprendizaje automático aplicado para estimar las características de un modelo de aprendizaje automático en datos no utilizados.
Es comparativamente simple de entender. A menudo da como resultado una estimación menos sesgada o sobreajustada de la habilidad del modelo, como un simple conjunto de trenes o un conjunto de prueba.
El procedimiento general se construye con unos simples pasos:
- Tenemos que mezclar el conjunto de datos para aleatorizarlo.
- Luego dividimos el conjunto de datos en k grupos de tamaño similar.
- Para cada grupo único:
Tenemos que tomar un grupo como un conjunto de datos de prueba particular. Luego consideramos todos los grupos restantes como un conjunto completo de datos de entrenamiento. Luego ajustamos un modelo en el conjunto de entrenamiento y confirmamos el resultado. Lo ejecutamos en el equipo de prueba. Anotamos la puntuación de la evaluación.
Fragmento de código R:

4. Validación cruzada estratificada de k-fold
La estratificación es una reorganización de los datos para asegurarse de que cada pliegue sea un representante completo. Considere un problema de clasificación binaria, con cada clase de 50% de datos.
Cuando se trata tanto de sesgo como de varianza, la validación cruzada estratificada de k-fold es el mejor método.
Fragmento de código R:

5. Validación contradictoria
La idea básica es comprobar el porcentaje de similitud de características y su distribución entre entrenamiento y pruebas. Si no son fáciles de diferenciar, la distribución es, por supuesto, similar, y los métodos generales de validación deberían funcionar.
Al tratar con conjuntos de datos reales, a veces hay casos en los que los conjuntos de prueba y los conjuntos de trenes son muy diferentes. Las técnicas internas de validación cruzada generan puntuaciones, no dentro del ámbito de la puntuación de la prueba. Aquí entra en juego la validación contradictoria.
Comprueba el grado de similitud dentro del entrenamiento y las pruebas relacionadas con la distribución de características. Esta validación se caracteriza por la combinación de conjuntos de entrenamiento y prueba, el etiquetado de cero o uno (cero: entrenamiento, una prueba) y el análisis de una tarea de clasificación de puntajes binarios.
Tenemos que crear una nueva variable de destino que sea 1 para cada fila en el conjunto de trenes y 0 para cada fila en el conjunto de prueba.
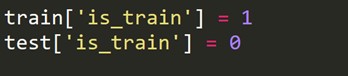
Ahora combinamos los conjuntos de datos de tren y prueba.
![]()
Usando la variable de destino recién creada anterior, ajustamos un modelo de clasificación y predecimos las probabilidades de cada fila de estar en el conjunto de prueba.
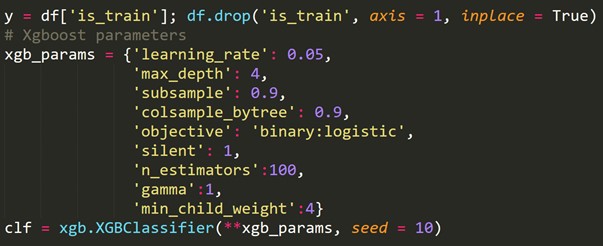
6. Validación cruzada para series temporales
Un conjunto de datos de series de tiempo no se puede dividir aleatoriamente ya que la sección de tiempo estropea los datos. En un problema de serie de tiempo, realizamos una validación cruzada como se muestra a continuación.
Para la validación cruzada de series temporales , creamos pliegues a modo de cadenas de reenvío.
Si, por ejemplo, durante n años, tenemos una serie de tiempo para la demanda anual del consumidor de un producto en particular. Hacemos los pliegues así:
pliegue 1: grupo de entrenamiento 1, grupo de prueba 2
pliegue 2: grupo de entrenamiento 1,2, grupo de prueba 3
pliegue 3: grupo de entrenamiento 1,2,3, grupo de prueba 4
pliegue 4: grupo de entrenamiento 1,2,3,4, grupo de prueba 5
pliegue 5: grupo de entrenamiento 1,2,3,4,5, grupo de prueba 6
.
.
.
pliegue n: grupo de entrenamiento 1 a n-1, grupo de prueba n
Se seleccionan progresivamente un nuevo tren y un nuevo conjunto de pruebas. Inicialmente, comenzamos con un conjunto de trenes con un número mínimo de observaciones requeridas para ajustar el modelo. Poco a poco, con cada pliegue, cambiamos nuestro tren y conjuntos de prueba.
Fragmento de código R:

h = 1 significa que tomamos en consideración el error para los pronósticos de 1 paso adelante.
Aprenda cursos de ciencia de datos de las mejores universidades del mundo. Obtenga programas Executive PG, programas de certificados avanzados o programas de maestría para acelerar su carrera.
¿Cómo medir el sesgo-varianza del modelo?
Con la validación cruzada k-fold , obtenemos varios errores de estimación del modelo k. Para un modelo ideal, los errores suman cero. Para que el modelo devuelva su sesgo, se toma el promedio de todos los errores y se escala. El promedio más bajo se considera apreciable para el modelo.
Para el cálculo de la varianza del modelo, tomamos la desviación estándar de todos los errores. Nuestro modelo no es variable con diferentes subconjuntos de datos de entrenamiento si la desviación estándar es menor.
El enfoque debe estar en tener un equilibrio entre el sesgo y la varianza. Si reducimos la varianza y el sesgo del modelo de control, podemos alcanzar el equilibrio hasta cierto punto. Eventualmente creará un modelo para una mejor predicción.
Lea también: Validación cruzada en Python: todo lo que necesita saber
Terminando
En este artículo, discutimos la validación cruzada y su aplicación en R. También aprendimos métodos para evitar el sobreajuste. También discutimos diferentes procedimientos como el enfoque del conjunto de validación, LOOCV, k-fold Cross-Validation y k-fold estratificado, seguido de la implementación de cada enfoque en R realizada en el conjunto de datos Iris.
¿Qué es la programación R?
La programación R es un lenguaje informático y una configuración de software que se puede utilizar para el análisis matemático, la representación gráfica y la creación de informes. Fue inventado en la Universidad de Auckland en Nueva Zelanda por Ross Ihaka y Robert Gentleman, y el equipo central de desarrollo de R lo está desarrollando actualmente. La programación R es un software disponible abiertamente bajo la licencia GNU y hay disponibles versiones binarias precompiladas para varios sistemas operativos.
¿Dónde se requiere validación cruzada?
Cuando no podemos ajustar el modelo a los datos de entrenamiento en el aprendizaje automático, no podemos garantizar que el modelo funcione de manera efectiva con datos reales. Para ello, debemos garantizar que nuestro modelo extrajo los patrones correctos de los datos y no generó un ruido excesivo. Por esta razón, utilizamos el método de validación cruzada. Podemos garantizar que nuestros modelos tienen el patrón de datos correcto y no generan ruido excesivo con la validación cruzada.
¿Cuáles son las aplicaciones de R?
La programación R se utiliza en una amplia gama de industrias. Los cálculos y análisis estadísticos los realizan estadísticos y estudiantes que utilizan R. Diferentes sectores, como la banca, la atención médica, la fabricación, el sector de TI, las finanzas, el comercio electrónico y las redes sociales, utilizan el lenguaje de programación R. R incluso se usa para fines gubernamentales, como el mantenimiento de registros y el procesamiento del censo.