
Validasi Silang dalam R: Penggunaan, Model & Pengukuran
Diterbitkan: 2020-10-19Saat Anda memulai perjalanan Anda ke dunia ilmu data dan pembelajaran mesin, selalu ada kecenderungan untuk memulai dengan pembuatan model dan algoritme. Anda cenderung menghindari belajar atau mengetahui cara menguji keefektifan model dalam data dunia nyata.
Cross-Validation di R adalah jenis validasi model yang meningkatkan proses validasi hold-out dengan memberikan preferensi pada subset data dan memahami trade-off bias atau varians untuk mendapatkan pemahaman yang baik tentang kinerja model ketika diterapkan di luar data yang kami latih. di. Artikel ini akan menjadi panduan awal hingga akhir untuk validasi model data dan menjelaskan perlunya validasi model.
Daftar isi
Ketidakstabilan Model Pembelajaran
Untuk memahami hal ini, kita akan menggunakan gambar-gambar ini untuk mengilustrasikan kurva pembelajaran yang sesuai dari berbagai model:
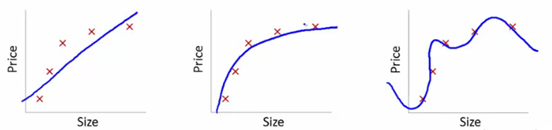
Sumber
Kami telah menunjukkan di sini model ketergantungan yang dipelajari pada harga artikel pada ukuran.
Kami membuat persamaan transformasi linier yang pas antara ini untuk menunjukkan plot.
Dari titik setel pelatihan, plot pertama salah. Jadi, pada set tes, itu tidak berkinerja bagus. Jadi, kita bisa mengatakan ini adalah "Underfitting". Di sini, model tidak dapat memahami pola sebenarnya dalam data.
Plot berikutnya menunjukkan ketergantungan yang benar pada harga pada ukuran. Ini menggambarkan kesalahan pelatihan minimal. Dengan demikian, hubungan digeneralisasikan.
Di plot terakhir, kami membangun hubungan yang hampir tidak memiliki kesalahan pelatihan sama sekali. Kami membangun hubungan dengan mempertimbangkan setiap fluktuasi titik data dan noise. Model data sangat rentan. Kesesuaian mengatur dirinya sendiri untuk meminimalkan kesalahan, sehingga menghasilkan pola yang rumit dalam kumpulan data yang diberikan. Ini dikenal sebagai "Overfitting". Di sini, mungkin ada perbedaan yang lebih tinggi antara set pelatihan dan tes.
Di dunia ilmu data, dari berbagai model, ada model yang berkinerja lebih baik. Namun terkadang, sulit untuk memahami apakah peningkatan skor ini karena hubungan yang ditangkap lebih baik atau hanya data yang terlalu pas. Kami menggunakan teknik validasi ini untuk mendapatkan solusi yang benar. Dengan ini kami juga mendapatkan pola umum yang lebih baik melalui teknik ini.
Apa itu Overfitting & Underfitting?
Underfitting dalam pembelajaran mesin mengacu pada menangkap pola yang tidak mencukupi. Saat kami menjalankan model pada set pelatihan dan pengujian, performanya sangat buruk.
Overfitting dalam pembelajaran mesin berarti menangkap kebisingan dan pola. Ini tidak menggeneralisasi dengan baik ke data yang tidak menjalani pelatihan. Saat kami menjalankan model di set pelatihan, performanya sangat baik, tetapi performanya buruk saat dijalankan di set tes.
Apa itu Cross-Validasi?
Cross-Validation bertujuan untuk menguji kemampuan model untuk membuat prediksi data baru yang tidak digunakan dalam estimasi sehingga masalah seperti overfitting atau bias seleksi ditandai. Juga, wawasan tentang generalisasi database diberikan.
Langkah-langkah untuk mengatur Cross-Validation :
- Kami menyisihkan satu set data sebagai spesimen sampel.
- Kami menjalani pelatihan model dengan bagian lain dari dataset.
- Kami menggunakan kumpulan sampel yang dicadangkan untuk pengujian. Set ini membantu dalam mengukur kinerja model yang menarik.
Validasi model statistik
Dalam statistik, validasi model menegaskan bahwa keluaran model statistik yang dapat diterima dihasilkan dari data nyata. Itu memastikan bahwa keluaran model statistik berasal dari keluaran proses pembuatan data sehingga tujuan utama program diproses secara menyeluruh.
Validasi umumnya tidak hanya dievaluasi pada data yang digunakan dalam konstruksi model, tetapi juga menggunakan data yang tidak digunakan dalam konstruksi. Jadi, validasi biasanya menguji beberapa prediksi model.
Apa gunanya validasi silang?
Cross-Validation terutama digunakan dalam pembelajaran mesin terapan untuk estimasi keterampilan model pada data masa depan. Artinya, kami menggunakan sampel yang diberikan untuk memperkirakan bagaimana model secara umum diharapkan tampil saat membuat prediksi pada data yang tidak digunakan selama pelatihan model.
Apakah Cross-Validation mengurangi Overfitting?
Cross-Validation adalah tindakan perlindungan yang kuat terhadap overfitting. Idenya adalah bahwa kami menggunakan data awal kami yang digunakan dalam set pelatihan untuk mendapatkan banyak pemisahan uji-latihan yang lebih kecil. Kemudian kami menggunakan pemisahan ini untuk menyetel model kami. Dalam k-fold normal Cross-Validation , kami membagi data menjadi k subset yang kemudian disebut folds.
Baca: Gaji Pengembang R di India
Metode yang Digunakan untuk Validasi Silang di R
Ada banyak metode yang digunakan ilmuwan data untuk kinerja Cross-Validation . Kami membahas beberapa di antaranya di sini.
1. Pendekatan Set Validasi
Pendekatan Set Validasi adalah metode yang digunakan untuk memperkirakan tingkat kesalahan dalam model dengan membuat dataset pengujian. Kami membangun model menggunakan kumpulan pengamatan lain, yang juga dikenal sebagai kumpulan data pelatihan. Hasil model kemudian diterapkan pada dataset pengujian. Kami kemudian dapat menghitung kesalahan dataset pengujian. Dengan demikian, memungkinkan model untuk tidak overfit.
kode R:
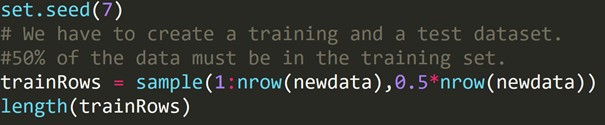
Kami telah menulis kode di atas untuk membuat dataset pelatihan dan dataset pengujian yang berbeda. Oleh karena itu, kami menggunakan dataset pelatihan untuk membangun model prediktif. Kemudian akan diterapkan pada dataset pengujian untuk memeriksa tingkat kesalahan.
2. Validasi silang tanpa cuti (LOOCV)
Leave-one-out Cross-Validation (LOOCV) adalah jenis Multi-dimensi tertentu dari Cross-Validation dari k folds. Di sini jumlah lipatan dan nomor instans dalam kumpulan data adalah sama. Untuk setiap contoh, algoritma pembelajaran hanya berjalan sekali. Dalam statistik, ada proses serupa yang disebut estimasi jack-knife.
Cuplikan Kode R:
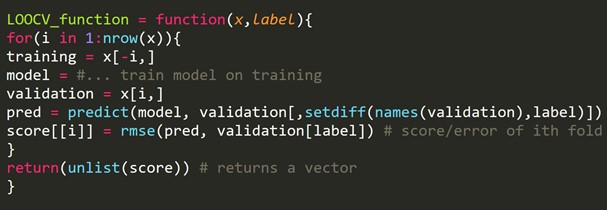
Kita dapat mengabaikan beberapa contoh pelatihan, yang akan membuat set validasi dengan ukuran yang sama untuk setiap iterasi. Proses ini dikenal sebagai LPOCV (Leave P Out Cross Validation)

3. k-Fold Cross-Validation
Prosedur pengambilan sampel ulang digunakan dalam sampel data terbatas untuk evaluasi model pembelajaran mesin.
Prosedur dimulai dengan mendefinisikan satu parameter, yang mengacu pada jumlah kelompok yang sampel data yang diberikan akan dibagi. Dengan demikian, prosedur ini disebut sebagai k-fold Cross-Validation .
Ilmuwan data sering menggunakan Validasi Silang dalam pembelajaran mesin terapan untuk memperkirakan fitur model pembelajaran mesin pada data yang tidak digunakan.
Hal ini relatif sederhana untuk dipahami. Ini sering menghasilkan perkiraan keterampilan model yang kurang bias atau terlalu pas seperti set kereta sederhana atau set tes.
Prosedur umum dibangun dengan beberapa langkah sederhana:
- Kita harus mencampur dataset untuk mengacaknya.
- Kemudian kami membagi dataset menjadi k grup dengan ukuran yang sama.
- Untuk setiap grup unik:
Kita harus mengambil grup sebagai kumpulan data uji tertentu. Kemudian kami mempertimbangkan semua grup yang tersisa sebagai kumpulan data pelatihan secara keseluruhan. Kemudian kami memasang model pada set pelatihan dan mengkonfirmasi hasilnya. Kami menjalankannya di set tes. Kami mencatat skor evaluasi.
Cuplikan kode R:

4. Validasi Silang k-fold bertingkat
Stratifikasi adalah penataan ulang data untuk memastikan bahwa setiap lipatan adalah perwakilan yang sehat. Pertimbangkan masalah klasifikasi biner, memiliki setiap kelas dari 50% data.
Ketika berhadapan dengan bias dan varians, Stratified k-fold Cross Validation adalah metode terbaik.
Cuplikan Kode R:

5. Validasi Bermusuhan
Ide dasarnya adalah untuk memeriksa persentase kesamaan fitur dan distribusinya antara pelatihan dan pengujian. Jika mereka tidak mudah dibedakan, distribusinya, tentu saja, serupa, dan metode validasi umum harus berhasil.
Saat berurusan dengan kumpulan data aktual, terkadang ada kasus di mana kumpulan tes dan kumpulan kereta sangat berbeda. Teknik Cross-Validasi internal menghasilkan skor, bukan dalam arena skor tes. Di sini, validasi permusuhan ikut bermain.
Ini memeriksa tingkat kesamaan dalam pelatihan dan pengujian mengenai distribusi fitur. Validasi ini ditampilkan dengan menggabungkan rangkaian rangkaian dan rangkaian pengujian, memberi label nol atau satu (nol – rangkaian, satu pengujian), dan menganalisis tugas klasifikasi skor biner.
Kita harus membuat variabel target baru yaitu 1 untuk setiap baris dalam rangkaian kereta dan 0 untuk setiap baris dalam rangkaian pengujian.
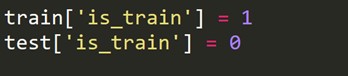
Sekarang kami menggabungkan dataset kereta dan pengujian.
![]()
Dengan menggunakan variabel target yang baru dibuat di atas, kami menyesuaikan model klasifikasi dan memprediksi probabilitas setiap baris untuk berada di set pengujian.
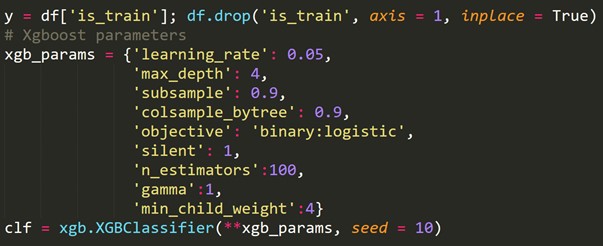
6. Validasi Silang untuk deret waktu
Kumpulan data deret waktu tidak dapat dibagi secara acak karena bagian waktu mengacaukan data. Dalam masalah time series, kami melakukan Cross-Validation seperti yang ditunjukkan di bawah ini.
Untuk Validasi Silang deret waktu , kami membuat lipatan dengan cara rantai penerusan.
Jika, misalnya, selama n tahun, kami memiliki deret waktu untuk permintaan konsumen tahunan untuk produk tertentu. Kami membuat lipatan seperti ini:
lipat 1: kelompok pelatihan 1, kelompok uji 2
lipat 2: kelompok pelatihan 1,2, kelompok uji 3
lipat 3: kelompok pelatihan 1,2,3, kelompok uji 4
lipat 4: kelompok pelatihan 1,2,3,4, kelompok uji 5
lipat 5: kelompok pelatihan 1,2,3,4,5, kelompok tes 6
.
.
.
lipat n: kelompok pelatihan 1 hingga n-1, kelompok uji n
Rangkaian kereta dan pengujian baru dipilih secara progresif. Awalnya, kita mulai dengan rangkaian kereta dengan jumlah pengamatan minimum yang diperlukan untuk menyesuaikan model. Secara bertahap, dengan setiap lipatan, kami mengubah rangkaian kereta dan pengujian kami.
Cuplikan Kode R:

h = 1 berarti kita mempertimbangkan kesalahan untuk prakiraan 1 langkah ke depan.
Pelajari kursus ilmu data dari Universitas top dunia. Dapatkan Program PG Eksekutif, Program Sertifikat Tingkat Lanjut, atau Program Magister untuk mempercepat karier Anda.
Bagaimana mengukur bias-varians model?
Dengan k-fold Cross-Validation , diperoleh berbagai k error estimasi model. Untuk model yang ideal, kesalahan berjumlah nol. Agar model mengembalikan biasnya, rata-rata semua kesalahan diambil dan diskalakan. Rata-rata yang lebih rendah dianggap cukup untuk model.
Untuk perhitungan varians model, kami mengambil standar deviasi dari semua kesalahan. Model kami tidak variabel dengan himpunan bagian yang berbeda dari data pelatihan jika standar deviasi kecil.
Fokusnya harus pada keseimbangan antara bias dan varians. Jika kita mengurangi varians dan bias model kontrol, kita dapat mencapai keseimbangan sampai batas tertentu. Ini pada akhirnya akan membuat model untuk prediksi yang lebih baik.
Baca Juga: Validasi Silang dengan Python: Semua yang Perlu Anda Ketahui
Membungkus
Pada artikel ini, kami membahas Cross-Validation dan penerapannya di R. Kami juga mempelajari metode untuk menghindari overfitting. Kami juga membahas prosedur yang berbeda seperti pendekatan set validasi, LOOCV, k-fold Cross-Validation , dan k-fold bertingkat, diikuti oleh implementasi setiap pendekatan dalam R yang dilakukan pada dataset Iris.
Apa itu pemrograman R?
Pemrograman R adalah bahasa komputasi dan pengaturan perangkat lunak yang dapat digunakan untuk analisis matematis, representasi grafis, dan pelaporan. Itu ditemukan di Universitas Auckland di Selandia Baru oleh Ross Ihaka dan Robert Gentleman, dan Tim Inti Pengembangan R saat ini sedang mengembangkannya. Pemrograman R adalah perangkat lunak yang tersedia secara terbuka di bawah Lisensi GNU dan tersedia versi biner yang telah dikompilasi sebelumnya untuk beberapa sistem operasi.
Di mana validasi silang diperlukan?
Ketika kami tidak dapat menyesuaikan model pada data pelatihan dalam pembelajaran mesin, kami tidak dapat menjamin bahwa model akan beroperasi secara efektif pada data nyata. Untuk melakukannya, kami harus menjamin bahwa model kami mengekstrak pola yang benar dari data dan tidak menghasilkan noise yang berlebihan. Untuk alasan ini, kami menggunakan metode validasi silang. Kami dapat menjamin bahwa model kami memiliki pola data yang benar dan tidak menghasilkan noise yang berlebihan dengan validasi silang.
Apa saja aplikasi dari R?
Pemrograman R digunakan di berbagai industri. Perhitungan dan analisis statistik dilakukan oleh ahli statistik dan mahasiswa menggunakan R. Berbagai sektor seperti Perbankan, Kesehatan, Manufaktur, Sektor IT, Keuangan, E-commerce, dan Media Sosial menggunakan bahasa pemrograman R. R bahkan digunakan untuk keperluan pemerintah seperti pencatatan dan pemrosesan sensus.