
Validation croisée dans R : utilisation, modèles et mesures
Publié: 2020-10-19Lorsque vous vous lancez dans votre voyage dans le monde de la science des données et de l'apprentissage automatique, vous avez toujours tendance à commencer par la création de modèles et les algorithmes. Vous avez tendance à éviter d'apprendre ou de savoir comment tester l'efficacité des modèles dans des données du monde réel.
La validation croisée dans R est un type de validation de modèle qui améliore les processus de validation en donnant la préférence à des sous-ensembles de données et en comprenant le biais ou le compromis de variance pour obtenir une bonne compréhension des performances du modèle lorsqu'il est appliqué au-delà des données que nous avons formées. au. Cet article sera un guide de bout en bout pour la validation du modèle de données et élucidera le besoin de validation du modèle.
Table des matières
L'instabilité des modèles d'apprentissage
Pour comprendre cela, nous utiliserons ces images pour illustrer l'ajustement de la courbe d'apprentissage de divers modèles :
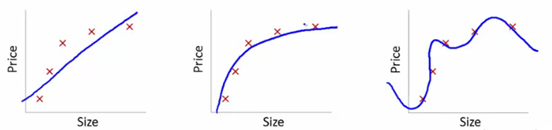
La source
Nous avons montré ici le modèle savant de dépendance du prix de l'article à la taille.
Nous avons créé une équation de transformation linéaire entre celles-ci pour montrer les tracés.
A partir des consignes d'apprentissage, le premier tracé est erroné. Ainsi, sur l'ensemble de test, il ne fonctionne pas très bien. Donc, nous pouvons dire que c'est "Underfitting". Ici, le modèle n'est pas en mesure de comprendre le modèle réel dans les données.
Le graphique suivant montre la dépendance correcte du prix à la taille. Il représente une erreur de formation minimale. Ainsi, la relation est généralisée.
Dans le dernier graphique, nous établissons une relation qui n'a presque aucune erreur d'apprentissage. Nous construisons la relation en considérant chaque fluctuation du point de données et le bruit. Le modèle de données est très vulnérable. L'ajustement s'organise pour minimiser l'erreur, générant ainsi des modèles compliqués dans l'ensemble de données donné. C'est ce qu'on appelle le "sur-ajustement". Ici, il pourrait y avoir une plus grande différence entre les ensembles d'entraînement et de test.
Dans le monde de la science des données, parmi divers modèles, on recherche un modèle plus performant. Mais parfois, il est difficile de comprendre si ce score amélioré est dû au fait que la relation est mieux capturée ou simplement à un ajustement excessif des données. Nous utilisons ces techniques de validation pour avoir les bonnes solutions. Par la présente, nous obtenons également un modèle mieux généralisé via ces techniques.
Qu'est-ce que le sur-ajustement et le sous-ajustement ?
Le sous-ajustement dans l'apprentissage automatique fait référence à la capture de modèles insuffisants. Lorsque nous exécutons le modèle sur des ensembles d'entraînement et de test, il fonctionne très mal.
Le surajustement dans l'apprentissage automatique signifie capturer le bruit et les modèles. Celles-ci ne se généralisent pas bien aux données qui n'ont pas subi d'apprentissage. Lorsque nous exécutons le modèle sur l'ensemble d'apprentissage, il fonctionne extrêmement bien, mais il fonctionne mal lorsqu'il est exécuté sur l'ensemble de test.
Qu'est-ce que la validation croisée ?
La validation croisée vise à tester la capacité du modèle à prédire de nouvelles données non utilisées dans l'estimation afin que des problèmes tels que le surajustement ou le biais de sélection soient signalés. En outre, un aperçu de la généralisation de la base de données est donné.
Étapes pour organiser la validation croisée :
- Nous gardons de côté un ensemble de données comme spécimen d'échantillon.
- Nous subissons la formation du modèle avec l'autre partie de l'ensemble de données.
- Nous utilisons le jeu d'échantillons réservé pour les tests. Cet ensemble aide à quantifier les performances convaincantes du modèle.
Validation du modèle statistique
En statistique, la validation du modèle confirme que les sorties acceptables d'un modèle statistique sont générées à partir des données réelles. Il s'assure que les sorties du modèle statistique sont dérivées des sorties du processus de génération de données afin que les principaux objectifs du programme soient traités de manière approfondie.
La validation est généralement non seulement évaluée sur des données qui ont été utilisées dans la construction du modèle, mais elle utilise également des données qui n'ont pas été utilisées dans la construction. Ainsi, la validation teste généralement certaines des prédictions du modèle.
A quoi sert la validation croisée ?
La validation croisée est principalement utilisée dans l'apprentissage automatique appliqué pour estimer la compétence du modèle sur les données futures. Autrement dit, nous utilisons un échantillon donné pour estimer les performances attendues du modèle tout en faisant des prédictions sur les données inutilisées pendant la formation du modèle.
La validation croisée réduit-elle le surajustement ?
La validation croisée est une action protectrice forte contre le surajustement. L'idée est que nous utilisons nos données initiales utilisées dans les ensembles d'apprentissage pour obtenir de nombreuses fractions de train-test plus petites. Ensuite, nous utilisons ces divisions pour ajuster notre modèle. Dans la validation croisée k-fold normale , nous divisons les données en k sous-ensembles qui sont ensuite appelés folds.
Lire : Salaire d'un développeur R en Inde
Méthodes utilisées pour la validation croisée dans R
Il existe de nombreuses méthodes que les data scientists utilisent pour les performances de validation croisée . Nous en discutons ici quelques-uns.
1. Approche de l'ensemble de validation
L'approche de l'ensemble de validation est une méthode utilisée pour estimer le taux d'erreur dans un modèle en créant un ensemble de données de test. Nous construisons le modèle en utilisant l'autre ensemble d'observations, également connu sous le nom d'ensemble de données d'apprentissage. Le résultat du modèle est ensuite appliqué à l'ensemble de données de test. Nous pouvons ensuite calculer l'erreur de l'ensemble de données de test. Ainsi, cela permet aux modèles de ne pas sur-ajuster.
Code R :
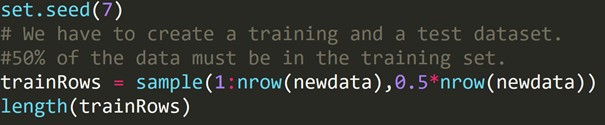
Nous avons écrit le code ci-dessus pour créer un ensemble de données d'entraînement et un autre ensemble de données de test. Par conséquent, nous utilisons l'ensemble de données d'apprentissage pour construire un modèle prédictif. Ensuite, il sera appliqué à l'ensemble de données de test pour vérifier les taux d'erreur.
2. Validation croisée Leave-One-Out (LOOCV)
La validation croisée Leave-one-out (LOOCV) est un certain type multidimensionnel de validation croisée de k plis. Ici, le nombre de plis et le numéro d'instance dans l'ensemble de données sont les mêmes. Pour chaque instance, l'algorithme d'apprentissage ne s'exécute qu'une seule fois. En statistique, il existe un processus similaire appelé estimation jack-knife.
Extrait de code R :
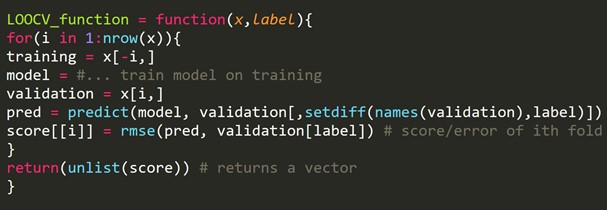
Nous pouvons omettre quelques exemples de formation, ce qui créera un ensemble de validation de la même taille pour chaque itération. Ce processus est connu sous le nom de LPOCV (Leave P Out Cross Validation)

3. Validation croisée en k
Une procédure de rééchantillonnage a été utilisée dans un échantillon de données limité pour l'évaluation des modèles d'apprentissage automatique.
La procédure commence par la définition d'un seul paramètre, qui fait référence au nombre de groupes qu'un échantillon de données donné doit être divisé. Ainsi, cette procédure est nommée k-fold Cross-Validation .
Les scientifiques des données utilisent souvent la validation croisée dans l'apprentissage automatique appliqué pour estimer les caractéristiques d'un modèle d'apprentissage automatique sur des données inutilisées.
C'est relativement simple à comprendre. Cela se traduit souvent par une estimation moins biaisée ou surajustée de la compétence du modèle, comme un simple ensemble de trains ou un ensemble de tests.
La procédure générale est constituée de quelques étapes simples :
- Nous devons mélanger l'ensemble de données pour le randomiser.
- Ensuite, nous avons divisé le jeu de données en k groupes de taille similaire.
- Pour chaque groupe unique :
Nous devons prendre un groupe comme un ensemble de données de test particulier. Ensuite, nous considérons tous les groupes restants comme un ensemble de données d'apprentissage complet. Ensuite, nous adaptons un modèle sur l'ensemble d'entraînement et confirmons le résultat. Nous l'exécutons sur l'ensemble de test. Nous notons la note d'évaluation.
Extrait de code R :

4. Validation croisée stratifiée k-fold
La stratification est un réarrangement des données pour s'assurer que chaque pli est un représentant sain. Considérons un problème de classification binaire, ayant chaque classe de 50 % de données.
Lorsqu'il s'agit à la fois de biais et de variance, la validation croisée stratifiée k-fold est la meilleure méthode.
Extrait de code R :

5. Validation contradictoire
L'idée de base est de vérifier le pourcentage de similitude des fonctionnalités et leur répartition entre l'apprentissage et les tests. S'ils ne sont pas faciles à différencier, la distribution est, par tous les moyens, similaire, et les méthodes générales de validation devraient fonctionner.
Tout en traitant des ensembles de données réels, il existe parfois des cas où les ensembles de test et les ensembles de train sont très différents. Les techniques internes de validation croisée génèrent des scores, pas dans l'arène du score du test. Ici, la validation contradictoire entre en jeu.
Il vérifie le degré de similitude dans la formation et les tests concernant la distribution des fonctionnalités. Cette validation est caractérisée par la fusion d'ensembles de train et de test, l'étiquetage zéro ou un (zéro - train, un test) et l'analyse d'une tâche de classification de scores binaires.
Nous devons créer une nouvelle variable cible qui vaut 1 pour chaque ligne de l'ensemble de train et 0 pour chaque ligne de l'ensemble de test.
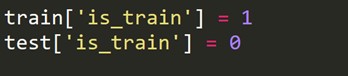
Maintenant, nous combinons les ensembles de données d'apprentissage et de test.
![]()
En utilisant la variable cible nouvellement créée ci-dessus, nous ajustons un modèle de classification et prédisons les probabilités de chaque ligne d'être dans l'ensemble de test.
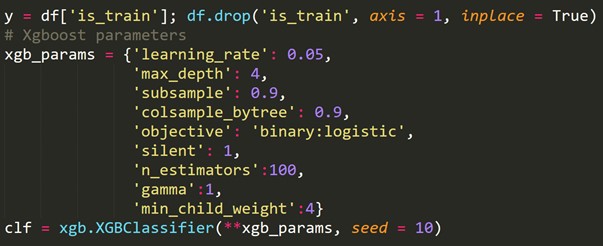
6. Validation croisée pour les séries chronologiques
Un ensemble de données de séries chronologiques ne peut pas être divisé de manière aléatoire car la section temporelle perturbe les données. Dans un problème de série chronologique, nous effectuons une validation croisée comme indiqué ci-dessous.
Pour la validation croisée de séries chronologiques , nous créons des plis à la manière de chaînes de transmission.
Si, par exemple, pendant n années, nous disposons d'une série chronologique de la demande annuelle des consommateurs pour un produit particulier. Nous faisons les plis comme ceci :
pli 1 : groupe d'entraînement 1, groupe de test 2
pli 2 : groupe d'entraînement 1,2, groupe de test 3
pli 3 : groupe d'entraînement 1,2,3, groupe de test 4
pli 4 : groupe d'entraînement 1,2,3,4, groupe de test 5
pli 5 : groupe d'entraînement 1,2,3,4,5, groupe de test 6
.
.
.
pli n : groupe d'entraînement 1 à n-1, groupe de test n
Un nouveau train et un ensemble de test sont progressivement sélectionnés. Initialement, nous commençons avec un train avec un nombre minimum d'observations nécessaires pour ajuster le modèle. Progressivement, à chaque pli, nous changeons nos ensembles d'entraînement et de test.
Extrait de code R :

h = 1 signifie que l'on prend en compte l'erreur pour les prévisions à 1 pas d'avance.
Apprenez des cours de science des données dans les meilleures universités du monde. Gagnez des programmes Executive PG, des programmes de certificat avancés ou des programmes de maîtrise pour accélérer votre carrière.
Comment mesurer le biais-variance du modèle ?
Avec k-fold Cross-Validation , nous obtenons diverses erreurs d'estimation du modèle k. Pour un modèle idéal, les erreurs totalisent zéro. Pour que le modèle renvoie son biais, la moyenne de toutes les erreurs est prise et mise à l'échelle. La moyenne inférieure est considérée comme appréciable pour le modèle.
Pour le calcul de la variance du modèle, nous prenons l'écart type de toutes les erreurs. Notre modèle n'est pas variable avec différents sous-ensembles de données d'entraînement si l'écart type est mineur.
L'accent devrait être mis sur l'équilibre entre le biais et la variance. Si nous réduisons la variance et contrôlons le biais du modèle, nous pouvons atteindre l'équilibre dans une certaine mesure. Il finira par créer un modèle pour une meilleure prédiction.
Lisez aussi : Cross-Validation en Python : tout ce que vous devez savoir
Emballer
Dans cet article, nous avons discuté de la validation croisée et de son application dans R. Nous avons également appris des méthodes pour éviter le surajustement. Nous avons également discuté de différentes procédures telles que l'approche de l'ensemble de validation, LOOCV, k-fold Cross-Validation et k-fold stratifié, suivies de la mise en œuvre de chaque approche dans R effectuée sur l'ensemble de données Iris.
Qu'est-ce que la programmation R ?
La programmation R est un langage informatique et un paramètre logiciel qui peut être utilisé pour l'analyse mathématique, la représentation graphique et la création de rapports. Il a été inventé à l'Université d'Auckland en Nouvelle-Zélande par Ross Ihaka et Robert Gentleman, et l'équipe R Development Core Team le développe actuellement. La programmation R est un logiciel librement disponible sous la licence GNU et des versions binaires pré-compilées pour plusieurs systèmes d'exploitation sont disponibles.
Où la validation croisée est-elle requise ?
Lorsque nous ne sommes pas en mesure d'adapter le modèle aux données d'apprentissage en machine learning, nous ne pouvons pas garantir que le modèle fonctionnera efficacement sur des données réelles. Pour ce faire, nous devons garantir que notre modèle a extrait les modèles corrects des données et n'a pas généré de bruit excessif. Pour cette raison, nous utilisons la méthode de validation croisée. Nous pouvons garantir que nos modèles ont le modèle de données correct et ne génèrent pas de bruit excessif avec la validation croisée.
Quelles sont les applications de R ?
La programmation R est utilisée dans un large éventail d'industries. Les calculs et analyses statistiques sont effectués par des statisticiens et des étudiants utilisant R. Différents secteurs tels que la banque, la santé, la fabrication, le secteur informatique, la finance, le commerce électronique et les médias sociaux utilisent le langage de programmation R. R est même utilisé à des fins gouvernementales comme la tenue de registres et le traitement du recensement.