
Walidacja krzyżowa w R: użycie, modele i pomiar
Opublikowany: 2020-10-19Kiedy wyruszasz w podróż do świata nauki o danych i uczenia maszynowego, zawsze istnieje tendencja do rozpoczynania od tworzenia modeli i algorytmów. Masz tendencję do unikania uczenia się lub wiedzy, jak testować skuteczność modeli na rzeczywistych danych.
Cross-Validation w R to rodzaj walidacji modelu, który usprawnia procesy walidacji wstrzymywania poprzez preferowanie podzbiorów danych i zrozumienie kompromisu błędu systematycznego lub wariancji, aby uzyskać dobre zrozumienie wydajności modelu, gdy jest stosowany poza danymi, które go wyszkoliliśmy na. Ten artykuł będzie przewodnikiem od początku do końca dotyczącym walidacji modelu danych i wyjaśnieniem potrzeby walidacji modelu.
Spis treści
Niestabilność modeli uczenia się
Aby to zrozumieć, użyjemy tych zdjęć, aby zilustrować dopasowanie krzywej uczenia się różnych modeli:
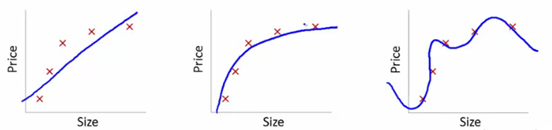
Źródło
Pokazaliśmy tutaj wyuczony model zależności ceny artykułu od rozmiaru.
Stworzyliśmy równanie transformacji liniowej pasujące między nimi, aby pokazać wykresy.
Z punktów uczących pierwszy wykres jest błędny. W związku z tym na zestawie testowym nie spisuje się zbyt dobrze. Możemy więc powiedzieć, że jest to „niedopasowanie”. Tutaj model nie jest w stanie zrozumieć rzeczywistego wzorca w danych.
Kolejny wykres pokazuje prawidłową zależność ceny od rozmiaru. Przedstawia minimalny błąd treningu. W ten sposób relacja jest uogólniona.
W ostatnim wątku nawiązujemy relację, w której prawie nie ma żadnego błędu treningowego. Budujemy relację, biorąc pod uwagę każdą fluktuację w punkcie danych i szumie. Model danych jest bardzo wrażliwy. Dopasowanie organizuje się tak, aby zminimalizować błąd, generując w ten sposób skomplikowane wzorce w danym zestawie danych. Jest to znane jako „przesadne dopasowanie”. Tutaj może być większa różnica między zbiorem uczącym a testowym.
W świecie data science spośród różnych modeli poszukuje się modelu, który działa lepiej. Czasami jednak trudno jest zrozumieć, czy ten lepszy wynik wynika z tego, że związek jest lepiej uchwycony, czy też jest to po prostu nadmierne dopasowanie danych. Używamy tych technik walidacji, aby uzyskać właściwe rozwiązania. Dzięki tym technikom uzyskujemy również lepiej uogólniony wzór.
Co to jest overfitting i underfitting?
Niedopasowanie w uczeniu maszynowym odnosi się do przechwytywania niewystarczających wzorców. Kiedy uruchamiamy model na zbiorach uczących i testowych, działa on bardzo słabo.
Nadmierne dopasowanie w uczeniu maszynowym oznacza przechwytywanie szumów i wzorców. Nie uogólniają one dobrze danych, które nie zostały przeszkolone. Kiedy uruchamiamy model na zbiorze uczącym, działa on bardzo dobrze, ale działa słabo, gdy jest uruchamiany na zbiorze testowym.
Co to jest walidacja krzyżowa?
Walidacja krzyżowa ma na celu przetestowanie zdolności modelu do przewidywania nowych danych, które nie są wykorzystywane w estymacji, tak aby problemy, takie jak nadmierne dopasowanie lub błąd selekcji, były oznaczane. Podano również wgląd w uogólnienie bazy danych.
Kroki organizowania weryfikacji krzyżowej :
- Zachowujemy zestaw danych jako próbkę.
- Przechodzimy szkolenie modelowe z drugą częścią zbioru danych.
- Do testów używamy zarezerwowanego zestawu próbek. Ten zestaw pomaga w ilościowym określeniu przekonującej wydajności modelu.
Walidacja modelu statystycznego
W statystyce walidacja modelu potwierdza, że dopuszczalne wyniki modelu statystycznego są generowane na podstawie danych rzeczywistych. Zapewnia, że dane wyjściowe modelu statystycznego pochodzą z danych wyjściowych procesu generowania danych, tak aby główne cele programu zostały dokładnie przetworzone.
Walidacja jest generalnie oceniana nie tylko na danych, które zostały użyte w konstrukcji modelu, ale także wykorzystuje dane, które nie zostały użyte w konstrukcji. Tak więc walidacja zwykle testuje niektóre prognozy modelu.
Jaki jest pożytek z walidacji krzyżowej?
Cross-Validation jest używany przede wszystkim w stosowanym uczeniu maszynowym do szacowania umiejętności modelu na przyszłych danych. Oznacza to, że używamy danej próbki, aby oszacować, jak ogólnie oczekuje się, że model będzie działał podczas dokonywania prognoz na nieużywanych danych podczas uczenia modelu.
Czy walidacja krzyżowa zmniejsza nadmierne dopasowanie?
Cross-Validation to silne działanie chroniące przed nadmiernym dopasowaniem. Pomysł polega na tym, że używamy naszych danych początkowych wykorzystywanych w zestawach uczących, aby uzyskać wiele mniejszych podziałów testowych. Następnie używamy tych szpagatów do tuningu naszego modelu. W normalnej k-krotnej weryfikacji krzyżowej dzielimy dane na k podzbiorów, które są następnie nazywane fałdami.
Przeczytaj: Wynagrodzenie programisty R w Indiach
Metody stosowane do walidacji krzyżowej w R
Istnieje wiele metod używanych przez analityków danych do wykonywania walidacji krzyżowej . Niektóre z nich omawiamy tutaj.
1. Podejście zestawu walidacyjnego
Metoda zestawu walidacyjnego to metoda używana do szacowania poziomu błędów w modelu poprzez tworzenie testowego zestawu danych. Model budujemy przy użyciu drugiego zestawu obserwacji, znanego również jako zestaw danych uczących. Wynik modelu jest następnie stosowany do testowego zestawu danych. Możemy wtedy obliczyć błąd zestawu danych testowych. Dzięki temu modele nie przesadzają.
Kod R:
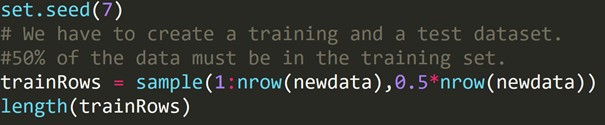
Napisaliśmy powyższy kod, aby utworzyć treningowy zestaw danych i inny testowy zestaw danych. Dlatego używamy szkoleniowego zestawu danych do budowania modelu predykcyjnego. Następnie zostanie zastosowany do testowego zestawu danych w celu sprawdzenia wskaźników błędów.
2. Weryfikacja krzyżowa typu Leave-one-out (LOOCV)
Cross - Validation (LOOCV) to pewien wielowymiarowy rodzaj Cross-Validation k fałdów. Tutaj liczba fałd i numer instancji w zestawie danych są takie same. W każdym przypadku algorytm uczenia działa tylko raz. W statystyce istnieje podobny proces zwany szacowaniem scyzoryka.
Fragment kodu R:
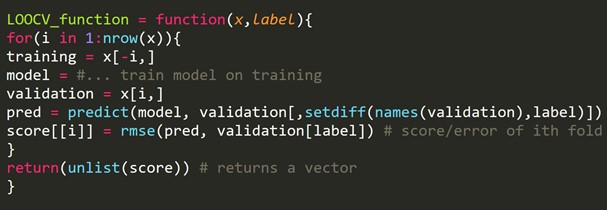
Możemy pominąć kilka przykładów szkoleniowych, które utworzą zestaw walidacyjny o tym samym rozmiarze dla każdej iteracji. Ten proces jest znany jako LPOCV (Leave P Out Cross Validation)

3. Weryfikacja krzyżowa k-fold
W przypadku ograniczonej próbki danych do oceny modeli uczenia maszynowego zastosowano procedurę ponownego próbkowania.
Procedura rozpoczyna się od zdefiniowania pojedynczego parametru, który odnosi się do liczby grup, na które dana próbka danych ma zostać podzielona. W związku z tym ta procedura nosi nazwę k-fold Cross-Validation .
Analitycy danych często używają weryfikacji krzyżowej w stosowanym uczeniu maszynowym do szacowania funkcji modelu uczenia maszynowego na nieużywanych danych.
Jest to stosunkowo proste do zrozumienia. Często skutkuje to mniej obciążoną lub przesadnie dopasowaną oceną umiejętności modelowania, taką jak prosty zestaw pociągów lub zestaw testowy.
Ogólna procedura składa się z kilku prostych kroków:
- Musimy wymieszać zbiór danych, aby go zrandomizować.
- Następnie dzielimy zbiór danych na k grup o podobnej wielkości.
- Dla każdej unikalnej grupy:
Musimy wziąć grupę jako konkretny zestaw danych testowych. Następnie traktujemy wszystkie pozostałe grupy jako cały zestaw danych treningowych. Następnie dopasowujemy model do zestawu treningowego i potwierdzamy wynik. Przeprowadzamy to na zestawie testowym. Notujemy wynik oceny.
Fragment kodu R:

4. Stratyfikowana k-krotna walidacja krzyżowa
Stratyfikacja to przeorganizowanie danych w celu upewnienia się, że każda fałda jest pełnowartościowym reprezentantem. Rozważ problem z klasyfikacją binarną, w której każda klasa zawiera 50% danych.
W przypadku zarówno stronniczości, jak i wariancji najlepszą metodą jest warstwowa k-krotna walidacja krzyżowa .
Fragment kodu R:

5. Walidacja kontradyktoryjności
Podstawowym pomysłem jest sprawdzenie procentu podobieństwa cech i ich rozmieszczenia między treningiem a testami. Jeśli nie są one łatwe do odróżnienia, rozkład jest jak najbardziej podobny i ogólne metody walidacji powinny się sprawdzić.
Podczas pracy z rzeczywistymi zestawami danych zdarzają się przypadki, w których zestawy testowe i zestawy pociągowe są bardzo różne. Wewnętrzne techniki walidacji krzyżowej generują wyniki, a nie w obszarze wyniku testu. Tutaj w grę wchodzi weryfikacja kontradyktoryjności.
Sprawdza stopień podobieństwa w ramach szkoleń i testów dotyczących rozkładu cech. Ta walidacja polega na łączeniu zestawów pociągów i testów, oznaczaniu zera lub jedynki (zero – pociąg, jeden test) i analizowaniu zadania klasyfikacji wyników binarnych.
Musimy utworzyć nową zmienną docelową, która wynosi 1 dla każdego wiersza w zestawie pociągu i 0 dla każdego wiersza w zestawie testowym.
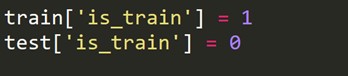
Teraz łączymy zestawy danych o pociągu i testach.
![]()
Używając powyższej nowo utworzonej zmiennej docelowej, dopasowujemy model klasyfikacji i przewidujemy prawdopodobieństwo, że każdy wiersz znajdzie się w zestawie testowym.
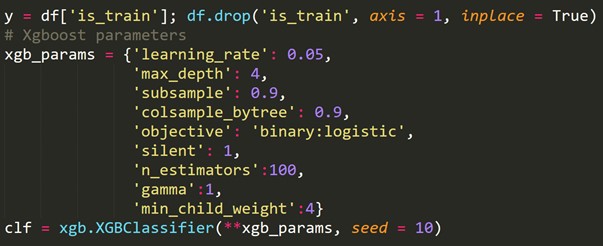
6. Walidacja krzyżowa dla szeregów czasowych
Zbiór danych szeregów czasowych nie może być losowo dzielony, ponieważ sekcja czasowa miesza dane. W przypadku problemu z szeregiem czasowym przeprowadzamy walidację krzyżową, jak pokazano poniżej.
Do walidacji krzyżowej serii czasowych tworzymy fałdy na wzór łańcuchów spedycyjnych.
Jeżeli np. za n lat mamy szereg czasowy dla rocznego zapotrzebowania konsumentów na dany produkt. Fałdy wykonujemy w ten sposób:
złóż 1: grupa treningowa 1, grupa testowa 2
zakładka 2: grupa treningowa 1,2, grupa testowa 3
krotnie 3: grupa treningowa 1,2,3, grupa testowa 4
krotnie 4: grupa treningowa 1,2,3,4, grupa testowa 5
krotnie 5: grupa treningowa 1,2,3,4,5, grupa testowa 6
.
.
.
krotnie n: grupa treningowa 1 do n-1, grupa testowa n
Progresywnie wybierany jest nowy pociąg i zestaw testowy. Początkowo zaczynamy od zestawu pociągów z minimalną liczbą obserwacji wymaganych do dopasowania modelu. Stopniowo, z każdym złożeniem, zmieniamy nasz pociąg i zestawy testowe.
Fragment kodu R:

h = 1 oznacza, że bierzemy pod uwagę błąd dla prognoz o 1 krok do przodu.
Ucz się kursów nauki o danych z najlepszych światowych uniwersytetów. Zdobywaj programy Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.
Jak zmierzyć wariancję obciążenia modelu?
Dzięki k-krotnej walidacji krzyżowej uzyskujemy różne błędy estymacji modelu k. W przypadku idealnego modelu błędy sumują się do zera. Aby model zwrócił swoje obciążenie, średnia wszystkich błędów jest pobierana i skalowana. Niższa średnia jest uważana za istotną dla modelu.
Do obliczenia wariancji modelu bierzemy odchylenie standardowe wszystkich błędów. Nasz model nie jest zmienny z różnymi podzbiorami danych uczących, jeśli odchylenie standardowe jest niewielkie.
Należy skupić się na równowadze między stronniczością a wariancją. Jeśli zmniejszymy obciążenie modelu wariancji i kontroli, możemy w pewnym stopniu osiągnąć równowagę. W końcu stworzy model do lepszego przewidywania.
Przeczytaj także: Walidacja krzyżowa w Pythonie: wszystko, co musisz wiedzieć
Zawijanie
W tym artykule omówiliśmy walidację krzyżową i jej zastosowanie w R. Poznaliśmy również metody unikania nadmiernego dopasowania. Omówiliśmy również różne procedury, takie jak podejście zestawu walidacyjnego, LOOCV, k-krotna walidacja krzyżowa i stratyfikowana k-krotność, a następnie implementacja każdego podejścia w R wykonywana na zestawie danych Iris.
Co to jest programowanie w języku R?
Programowanie w języku R to język obliczeniowy i ustawienie oprogramowania, które można wykorzystać do analizy matematycznej, reprezentacji graficznej i raportowania. Został wynaleziony na Uniwersytecie Auckland w Nowej Zelandii przez Rossa Ihakę i Roberta Gentlemana, a R Development Core Team obecnie go rozwija. Programowanie w języku R jest ogólnodostępnym oprogramowaniem na licencji GNU i dostępne są wstępnie skompilowane wersje binarne dla kilku systemów operacyjnych.
Gdzie wymagana jest walidacja krzyżowa?
Gdy nie jesteśmy w stanie dopasować modelu do danych uczących w uczeniu maszynowym, nie możemy zagwarantować, że model będzie działał skutecznie na rzeczywistych danych. Aby to zrobić, musimy zagwarantować, że nasz model wyodrębnił z danych prawidłowe wzorce i nie generował nadmiernego szumu. Z tego powodu stosujemy metodę walidacji krzyżowej. Możemy zagwarantować, że nasze modele mają prawidłowy wzorzec danych i nie generują nadmiernego szumu dzięki walidacji krzyżowej.
Jakie są zastosowania R?
Programowanie R jest stosowane w wielu gałęziach przemysłu. Obliczenia i analizy statystyczne są wykonywane przez statystyków i studentów korzystających z języka R. Różne sektory, takie jak bankowość, opieka zdrowotna, produkcja, sektor IT, finanse, handel elektroniczny i media społecznościowe, wykorzystują język programowania R. R jest nawet używany do celów rządowych, takich jak prowadzenie rejestrów i przetwarzanie spisów.