
عبر التحقق من الصحة في R: الاستخدام والنماذج والقياس
نشرت: 2020-10-19عندما تشرع في رحلتك إلى عالم علوم البيانات والتعلم الآلي ، فهناك دائمًا ميل للبدء بإنشاء النماذج والخوارزميات. أنت تميل إلى تجنب التعلم أو معرفة كيفية اختبار فعالية النماذج في بيانات العالم الحقيقي.
التحقق المتقاطع في R هو نوع من التحقق من صحة النموذج الذي يحسن عمليات التحقق من الصلاحية من خلال إعطاء الأفضلية لمجموعات فرعية من البيانات وفهم التحيز أو مقايضة التباين للحصول على فهم جيد لأداء النموذج عند تطبيقه بعد البيانات التي قمنا بتدريبها على. ستكون هذه المقالة بمثابة دليل بداية إلى نهاية للتحقق من صحة نموذج البيانات وتوضيح الحاجة إلى التحقق من صحة النموذج.
جدول المحتويات
عدم استقرار نماذج التعلم
لفهم هذا ، سنستخدم هذه الصور لتوضيح منحنى التعلم المناسب للنماذج المختلفة:
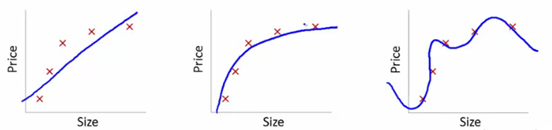
مصدر
لقد أظهرنا هنا النموذج الذي تعلمناه للاعتماد على سعر السلعة على الحجم.
قمنا بعمل معادلة تحويل خطية مناسبة بينهما لإظهار المؤامرات.
من نقاط مجموعة التدريب ، الحبكة الأولى خاطئة. وبالتالي ، في مجموعة الاختبار ، فإنه لا يعمل بشكل جيد. لذلك ، يمكننا القول أن هذا "غير ملائم". هنا ، النموذج غير قادر على فهم النمط الفعلي في البيانات.
يظهر الرسم التالي الاعتماد الصحيح على السعر على الحجم. يصور خطأ تدريب ضئيل. وبالتالي ، فإن العلاقة معممة.
في الحبكة الأخيرة ، أنشأنا علاقة تكاد لا تحتوي على أي خطأ تدريبي على الإطلاق. نبني العلاقة من خلال النظر في كل تقلب في نقطة البيانات والضوضاء. نموذج البيانات ضعيف للغاية. يرتب الملاءمة نفسه لتقليل الخطأ ، وبالتالي إنشاء أنماط معقدة في مجموعة البيانات المحددة. هذا هو المعروف باسم "Overfitting". هنا ، قد يكون هناك فرق أكبر بين مجموعات التدريب والاختبار.
في عالم علم البيانات ، من بين النماذج المختلفة ، هناك بحث عن نموذج يعمل بشكل أفضل. لكن في بعض الأحيان ، يكون من الصعب فهم ما إذا كانت هذه النتيجة المحسّنة ناتجة عن التقاط العلاقة بشكل أفضل أم أنها مجرد بيانات أكثر من اللازم. نستخدم تقنيات التحقق هذه للحصول على الحلول الصحيحة. طيه نحصل أيضًا على نمط معمم بشكل أفضل عبر هذه التقنيات.
ما هو الانقطاع والتركيب؟
يشير عدم الملائمة في التعلم الآلي إلى التقاط أنماط غير كافية. عندما نقوم بتشغيل النموذج على مجموعات التدريب والاختبار ، يكون أداؤه ضعيفًا للغاية.
يعني التجاوز في التعلم الآلي التقاط الضوضاء والأنماط. هذه لا تعمم جيدًا على البيانات التي لم تخضع للتدريب. عندما نقوم بتشغيل النموذج على مجموعة التدريب ، فإنه يعمل بشكل جيد للغاية ، لكنه يعمل بشكل ضعيف عند تشغيله على مجموعة الاختبار.
ما هو التحقق المتقاطع؟
يهدف التحقق المتقاطع إلى اختبار قدرة النموذج على التنبؤ ببيانات جديدة غير مستخدمة في التقدير بحيث يتم وضع علامة على مشكلات مثل التحيز الزائد أو التحيز في التحديد. أيضا ، يتم إعطاء نظرة ثاقبة على تعميم قاعدة البيانات.
خطوات تنظيم المصادقة المتقاطعة :
- نبقي جانبا مجموعة بيانات كعينة عينة.
- نجري تدريب النموذج مع الجزء الآخر من مجموعة البيانات.
- نحن نستخدم مجموعة العينات المحجوزة للاختبار. تساعد هذه المجموعة في تحديد الأداء المقنع للنموذج.
التحقق من صحة النموذج الإحصائي
في الإحصاء ، يؤكد التحقق من صحة النموذج أن المخرجات المقبولة للنموذج الإحصائي يتم إنشاؤها من البيانات الحقيقية. يتأكد من أن مخرجات النموذج الإحصائي مستمدة من مخرجات عملية توليد البيانات بحيث تتم معالجة الأهداف الرئيسية للبرنامج بشكل كامل.
بشكل عام ، لا يتم تقييم التحقق من الصحة فقط على البيانات التي تم استخدامها في بناء النموذج ، ولكنه يستخدم أيضًا البيانات التي لم يتم استخدامها في الإنشاء. لذلك ، عادةً ما يختبر التحقق من الصحة بعض تنبؤات النموذج.
ما هو استخدام المصادقة المتقاطعة؟
يستخدم التحقق المتقاطع بشكل أساسي في التعلم الآلي التطبيقي لتقدير مهارة النموذج على البيانات المستقبلية. أي أننا نستخدم عينة معينة لتقدير كيفية توقع أداء النموذج بشكل عام أثناء إجراء تنبؤات بشأن البيانات غير المستخدمة أثناء تدريب النموذج.
هل يقلل التحقق المتقاطع من فرط التجهيز؟
التحقق المتقاطع إجراء وقائي قوي ضد فرط التجهيز. الفكرة هي أننا نستخدم بياناتنا الأولية المستخدمة في مجموعات التدريب للحصول على العديد من تقسيمات اختبار القطار الأصغر. ثم نستخدم هذه الانقسامات لضبط نموذجنا. في التحقق المتقاطع العادي من k-fold ، نقسم البيانات إلى مجموعات فرعية k والتي تسمى فيما بعد الطيات.
قراءة: راتب R Developer في الهند
الطرق المستخدمة للتحقق المتقاطع في R.
هناك العديد من الطرق التي يستخدمها علماء البيانات لأداء التحقق المتبادل . نناقش بعض منهم هنا.
1. نهج مجموعة التحقق
نهج مجموعة التحقق من الصحة هو طريقة تستخدم لتقدير معدل الخطأ في نموذج عن طريق إنشاء مجموعة بيانات اختبار. نقوم ببناء النموذج باستخدام مجموعة الملاحظات الأخرى ، والمعروفة أيضًا باسم مجموعة بيانات التدريب. ثم يتم تطبيق نتيجة النموذج على مجموعة بيانات الاختبار. يمكننا بعد ذلك حساب خطأ مجموعة بيانات الاختبار. وبالتالي ، فإنه لا يسمح للنماذج بالملء الزائد.
كود R:
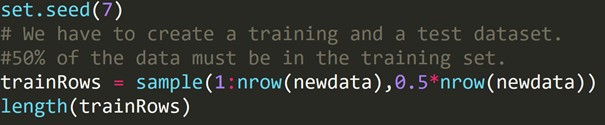
لقد كتبنا الكود أعلاه لإنشاء مجموعة بيانات تدريبية ومجموعة بيانات اختبار مختلفة. لذلك ، نستخدم مجموعة بيانات التدريب لبناء نموذج تنبؤي. ثم سيتم تطبيقه على مجموعة بيانات الاختبار للتحقق من معدلات الخطأ.
2. (LOOCV)
يُعد التحقق المتقاطع (LOOCV) من عدم الخروج مرة واحدة نوعًا معينًا متعدد الأبعاد من التحقق المتقاطع من طيات k. هنا عدد الطيات ورقم المثيل في مجموعة البيانات هو نفسه. لكل حالة ، تعمل خوارزمية التعلم مرة واحدة فقط. في الإحصاء ، هناك عملية مماثلة تسمى تقدير جاك سكين.
مقتطف رمز R:
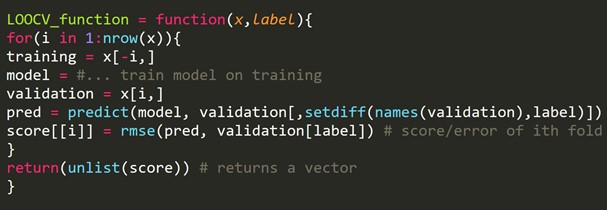
يمكننا ترك بعض الأمثلة التدريبية ، والتي ستنشئ مجموعة تحقق من نفس الحجم لكل تكرار. تُعرف هذه العملية باسم LPOCV (اترك P Out Cross Validation)

3. k-fold Cross-Validation
تم استخدام إجراء إعادة التشكيل في عينة بيانات محدودة لتقييم نماذج التعلم الآلي.
يبدأ الإجراء بتحديد معلمة واحدة ، والتي تشير إلى عدد المجموعات التي سيتم تقسيم عينة بيانات معينة. وبالتالي ، يُطلق على هذا الإجراء اسم k-fold Cross-Validation .
غالبًا ما يستخدم علماء البيانات التحقق المتقاطع في التعلم الآلي التطبيقي لتقدير ميزات نموذج التعلم الآلي على البيانات غير المستخدمة.
إنه سهل الفهم نسبيًا. غالبًا ما ينتج عنه تقدير أقل تحيزًا أو أكثر من اللازم لمهارة النموذج مثل مجموعة قطار بسيطة أو مجموعة اختبار.
تم بناء الإجراء العام ببضع خطوات بسيطة:
- علينا مزج مجموعة البيانات عشوائياً.
- ثم قمنا بتقسيم مجموعة البيانات إلى مجموعات k ذات الحجم المماثل.
- لكل مجموعة فريدة:
علينا أن نأخذ مجموعة كمجموعة بيانات اختبار معينة. ثم نعتبر جميع المجموعات المتبقية مجموعة بيانات تدريب كاملة. ثم نقوم بوضع نموذج على مجموعة التدريب وتأكيد النتيجة. نقوم بتشغيله على مجموعة الاختبار. نلاحظ أسفل درجة التقييم.
مقتطف رمز R:

4. طبقية k-أضعاف Cross-Validation
التقسيم الطبقي هو إعادة ترتيب البيانات للتأكد من أن كل طية تمثيلية سليمة. ضع في اعتبارك مشكلة التصنيف الثنائي ، حيث تحتوي كل فئة على 50٪ من البيانات.
عند التعامل مع كل من التحيز والتباين ، فإن التحقق المتقاطع من k-fold الطبقي هو أفضل طريقة.
مقتطف رمز R:

5. التحقق من صحة الخصومة
الفكرة الأساسية هي التحقق من نسبة التشابه في الميزات وتوزيعها بين التدريب والاختبارات. إذا لم يكن من السهل التفريق بينها ، فسيكون التوزيع ، بكل الوسائل ، متشابهًا ، ويجب أن تنجح طرق التحقق العامة.
أثناء التعامل مع مجموعات البيانات الفعلية ، توجد أحيانًا حالات تختلف فيها مجموعات الاختبار ومجموعات القطار اختلافًا كبيرًا. تُنشئ تقنيات التحقق المتقاطع الداخلي الدرجات ، وليس ضمن نطاق درجة الاختبار. هنا ، يأتي دور التحقق العدائي.
يتحقق من درجة التشابه في التدريب والاختبارات المتعلقة بتوزيع الميزات. يتميز هذا التحقق من الصحة بدمج مجموعات التدريب والاختبار ، ووضع علامة على الصفر أو واحد (صفر - قطار ، اختبار واحد) ، وتحليل مهمة تصنيف الدرجات الثنائية.
يتعين علينا إنشاء متغير هدف جديد وهو 1 لكل صف في مجموعة القطار و 0 لكل صف في مجموعة الاختبار.
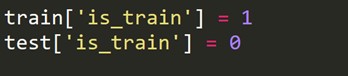
الآن نقوم بدمج مجموعات البيانات الخاصة بالقطار واختبارها.
![]()
باستخدام المتغير المستهدف الذي تم إنشاؤه حديثًا أعلاه ، نلائم نموذج التصنيف ونتوقع أن تكون احتمالات كل صف في مجموعة الاختبار.
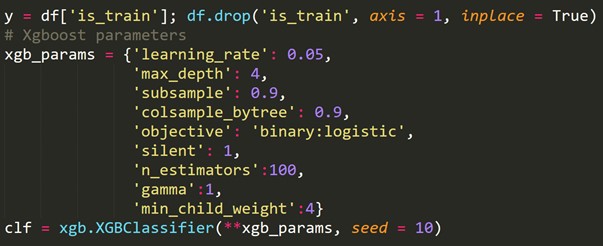
6. عبر التحقق من صحة السلاسل الزمنية
لا يمكن تقسيم مجموعة بيانات السلاسل الزمنية بشكل عشوائي لأن القسم الزمني يعبث بالبيانات. في مشكلة السلاسل الزمنية ، نقوم بإجراء التحقق المتقاطع كما هو موضح أدناه.
بالنسبة للتحقق المتقاطع من السلاسل الزمنية ، نقوم بإنشاء طيات بطريقة إعادة توجيه السلاسل.
إذا ، على سبيل المثال ، لعدد n من السنوات ، لدينا سلسلة زمنية لطلب المستهلك السنوي على منتج معين. نصنع الطيات مثل هذا:
أضعاف 1: مجموعة التدريب 1 ، مجموعة الاختبار 2
أضعاف 2: مجموعة التدريب 1،2 ، مجموعة الاختبار 3
أضعاف 3: مجموعة التدريب 1،2،3 ، مجموعة الاختبار 4
أضعاف 4: مجموعة التدريب 1،2،3،4 ، مجموعة الاختبار 5
أضعاف 5: مجموعة التدريب 1،2،3،4،5 ، مجموعة الاختبار 6
.
.
.
أضعاف n: مجموعة تدريب 1 إلى n-1 ، مجموعة اختبار n
يتم تحديد مجموعة قطار واختبار جديدة بشكل تدريجي. في البداية ، نبدأ بمجموعة قطار مع الحد الأدنى من الملاحظات المطلوبة لتناسب النموذج. تدريجيًا ، مع كل طية ، نقوم بتغيير مجموعات القطار والاختبار الخاصة بنا.
مقتطف رمز R:

h = 1 يعني أننا نأخذ في الاعتبار الخطأ للتنبؤات بخطوة واحدة.
تعلم دورات علوم البيانات من أفضل الجامعات في العالم. اربح برامج PG التنفيذية أو برامج الشهادات المتقدمة أو برامج الماجستير لتتبع حياتك المهنية بشكل سريع.
كيف تقيس التباين التحيز للنموذج؟
مع التحقق المتقاطع k-fold ، نحصل على العديد من أخطاء تقدير النموذج k. للحصول على نموذج مثالي ، مجموع الأخطاء يصل إلى الصفر. لكي يقوم النموذج بإرجاع انحيازه ، يتم أخذ متوسط جميع الأخطاء وقياسها. يعتبر المتوسط الأدنى ملحوظًا بالنسبة للنموذج.
لحساب تباين النموذج ، نأخذ الانحراف المعياري لجميع الأخطاء. نموذجنا غير متغير مع مجموعات فرعية مختلفة من بيانات التدريب إذا كان الانحراف المعياري طفيفًا.
يجب أن يكون التركيز على التوازن بين التحيز والتباين. إذا قللنا من تحيز نموذج التباين والتحكم ، فيمكننا الوصول إلى التوازن إلى حد ما. سيصنع في النهاية نموذجًا لتوقع أفضل.
اقرأ أيضًا: التحقق المتقاطع في Python: كل ما تحتاج إلى معرفته
تغليف
في هذه المقالة ، ناقشنا التحقق المتقاطع وتطبيقه في R. وتعلمنا أيضًا طرقًا لتجنب الإفراط في التجهيز. ناقشنا أيضًا إجراءات مختلفة مثل نهج مجموعة التحقق ، و LOOCV ، و k-fold Cross-Validation ، و k-fold ، متبوعًا بتنفيذ كل نهج في R الذي تم إجراؤه على مجموعة بيانات Iris.
ما هي برمجة R؟
البرمجة R هي لغة حوسبة وإعداد برمجي يمكن استخدامه للتحليل الرياضي والتمثيل الرسومي وإعداد التقارير. تم اختراعه في جامعة أوكلاند في نيوزيلندا بواسطة روس إيهاكا وروبرت جنتلمان ، ويعمل فريق R Development Core على تطويره حاليًا. برمجة R هي برنامج متاح علنًا بموجب ترخيص GNU والإصدارات الثنائية المجمعة مسبقًا للعديد من أنظمة التشغيل متاحة.
أين يتطلب التحقق المتبادل؟
عندما لا نتمكن من ملاءمة النموذج مع بيانات التدريب في التعلم الآلي ، لا يمكننا ضمان أن النموذج سيعمل بشكل فعال على بيانات حقيقية. للقيام بذلك ، يجب أن نضمن أن نموذجنا قد استخرج الأنماط الصحيحة من البيانات ولم ينتج عنه ضوضاء مفرطة. لهذا السبب ، نستخدم طريقة التحقق المتبادل. يمكننا أن نضمن أن نماذجنا لديها نمط البيانات الصحيح ولا تصدر ضوضاء مفرطة مع التحقق المتقاطع.
ما هي تطبيقات R؟
تستخدم برمجة R في مجموعة واسعة من الصناعات. يتم إجراء الحسابات والتحليلات الإحصائية من قبل الإحصائيين والطلاب باستخدام R. القطاعات المختلفة مثل البنوك والرعاية الصحية والتصنيع وقطاع تكنولوجيا المعلومات والتمويل والتجارة الإلكترونية ووسائل التواصل الاجتماعي تستخدم لغة البرمجة R. يستخدم R حتى للأغراض الحكومية مثل حفظ السجلات ومعالجة التعداد.