
การตรวจสอบความถูกต้องข้ามใน R: การใช้งาน โมเดล และการวัด
เผยแพร่แล้ว: 2020-10-19เมื่อคุณเริ่มต้นการเดินทางสู่โลกของวิทยาศาสตร์ข้อมูลและการเรียนรู้ของเครื่อง มีแนวโน้มเสมอที่จะเริ่มต้นด้วยการสร้างแบบจำลองและอัลกอริธึม คุณมักจะหลีกเลี่ยงการเรียนรู้หรือรู้วิธีทดสอบประสิทธิภาพของตัวแบบในข้อมูลจริง
Cross-Validation ใน R เป็นประเภทของการตรวจสอบแบบจำลองที่ปรับปรุงกระบวนการตรวจสอบความถูกต้องโดยให้ความสำคัญกับชุดย่อยของข้อมูลและทำความเข้าใจกับอคติหรือการแลกเปลี่ยนความแปรปรวนเพื่อให้ได้ความเข้าใจที่ดีเกี่ยวกับประสิทธิภาพของแบบจำลองเมื่อนำไปใช้นอกเหนือจากข้อมูลที่เราฝึก บน. บทความนี้จะเป็นคู่มือเริ่มต้นถึงสิ้นสุดสำหรับการตรวจสอบความถูกต้องของแบบจำลองข้อมูลและชี้แจงความจำเป็นในการตรวจสอบความถูกต้องของแบบจำลอง
สารบัญ
ความไม่แน่นอนของรูปแบบการเรียนรู้
เพื่อให้เข้าใจสิ่งนี้ เราจะใช้รูปภาพเหล่านี้เพื่อแสดงเส้นโค้งการเรียนรู้ที่พอดีของแบบจำลองต่างๆ:
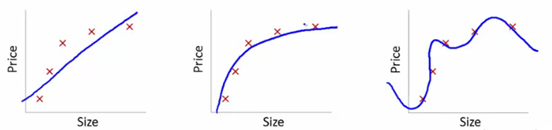
แหล่งที่มา
เราได้แสดงรูปแบบการเรียนรู้ของการพึ่งพาราคาบทความเกี่ยวกับขนาดไว้ที่นี่
เราสร้างสมการการแปลงเชิงเส้นที่เหมาะสมระหว่างสมการเหล่านี้เพื่อแสดงแผนภาพ
จากจุดกำหนดการฝึก โครงเรื่องแรกมีข้อผิดพลาด ดังนั้นในชุดทดสอบจึงทำงานได้ไม่ดีนัก ดังนั้นเราจึงสามารถพูดได้ว่านี่คือ "Underfitting" ที่นี่ โมเดลไม่สามารถเข้าใจรูปแบบที่แท้จริงในข้อมูลได้
พล็อตถัดไปแสดงการพึ่งพาราคาตามขนาดที่ถูกต้อง มันแสดงให้เห็นข้อผิดพลาดการฝึกอบรมน้อยที่สุด ดังนั้นความสัมพันธ์จึงเป็นลักษณะทั่วไป
ในโครงเรื่องสุดท้าย เราสร้างความสัมพันธ์ที่แทบไม่มีข้อผิดพลาดในการฝึกเลย เราสร้างความสัมพันธ์โดยพิจารณาจากความผันผวนของจุดข้อมูลและเสียง โมเดลข้อมูลมีความเสี่ยงสูง ความพอดีจะจัดเรียงตัวเองเพื่อลดข้อผิดพลาด ดังนั้นจึงสร้างรูปแบบที่ซับซ้อนในชุดข้อมูลที่กำหนด สิ่งนี้เรียกว่า ในที่นี้ อาจมีความแตกต่างระหว่างชุดการฝึกและชุดทดสอบสูงกว่า
ในโลกของวิทยาศาสตร์ข้อมูล จากโมเดลต่างๆ มีผู้มองหาโมเดลที่ทำงานได้ดีกว่า แต่บางครั้ง ก็ยากที่จะเข้าใจว่าคะแนนที่ได้รับการปรับปรุงนี้เป็นเพราะความสัมพันธ์ดีขึ้นหรือเพียงแค่ข้อมูลมากเกินไป เราใช้เทคนิคการตรวจสอบความถูกต้องเหล่านี้เพื่อให้มีวิธีแก้ปัญหาที่ถูกต้อง พร้อมกันนี้ เรายังได้รูปแบบทั่วไปที่ดีกว่าด้วยเทคนิคเหล่านี้
Overfitting & Underfitting คืออะไร?
Underfitting ในแมชชีนเลิร์นนิงหมายถึงการจับรูปแบบที่ไม่เพียงพอ เมื่อเรารันโมเดลในชุดการฝึกและชุดทดสอบ มันทำงานได้ไม่ดีนัก
การใส่แมชชีนเลิร์นนิงมากเกินไปหมายถึงการจับสัญญาณรบกวนและรูปแบบ สิ่งเหล่านี้ไม่ครอบคลุมถึงข้อมูลที่ไม่ผ่านการฝึกอบรม เมื่อเรารันโมเดลบนชุดการฝึก มันทำงานได้ดีมาก แต่ทำงานได้ไม่ดีเมื่อรันบนชุดทดสอบ
การตรวจสอบข้ามคืออะไร?
Cross-Validation มีจุดมุ่งหมายเพื่อทดสอบความสามารถของตัวแบบในการทำนายข้อมูลใหม่ที่ไม่ได้ใช้ในการประมาณค่า เพื่อจะได้ระบุปัญหาต่างๆ เช่น การใส่มากเกินไปหรืออคติในการเลือก นอกจากนี้ยังให้ข้อมูลเชิงลึกเกี่ยวกับลักษณะทั่วไปของฐานข้อมูล
ขั้นตอนในการจัดระเบียบ Cross-Validation :
- เราเก็บชุดข้อมูลไว้เป็นตัวอย่าง
- เราได้รับการฝึกอบรมแบบจำลองกับส่วนอื่น ๆ ของชุดข้อมูล
- เราใช้ชุดตัวอย่างที่สงวนไว้สำหรับการทดสอบ ชุดนี้ช่วยในการวัดประสิทธิภาพที่น่าสนใจของแบบจำลอง
การตรวจสอบแบบจำลองทางสถิติ
ในสถิติ การตรวจสอบความถูกต้องของแบบจำลองเป็นการยืนยันว่าผลลัพธ์ที่ยอมรับได้ของแบบจำลองทางสถิตินั้นถูกสร้างขึ้นจากข้อมูลจริง ทำให้แน่ใจว่าผลลัพธ์ของแบบจำลองทางสถิตินั้นได้มาจากผลลัพธ์ของกระบวนการสร้างข้อมูล เพื่อให้เป้าหมายหลักของโปรแกรมได้รับการประมวลผลอย่างละเอียด
โดยทั่วไป การตรวจสอบความถูกต้องไม่ได้ประเมินเฉพาะข้อมูลที่ใช้ในการสร้างแบบจำลองเท่านั้น แต่ยังใช้ข้อมูลที่ไม่ได้ใช้ในการก่อสร้างอีกด้วย ดังนั้น การตรวจสอบความถูกต้องมักจะทดสอบการคาดคะเนบางอย่างของแบบจำลอง
การใช้การตรวจสอบข้ามคืออะไร?
การตรวจสอบข้าม จะใช้เป็นหลักในการเรียนรู้ของเครื่องที่ใช้สำหรับการประเมินทักษะของแบบจำลองกับข้อมูลในอนาคต นั่นคือ เราใช้ตัวอย่างที่กำหนดเพื่อประเมินว่าโดยทั่วไปโมเดลคาดว่าจะทำงานอย่างไร ในขณะที่ทำการคาดคะเนข้อมูลที่ไม่ได้ใช้ระหว่างการฝึกแบบจำลอง
Cross-Validation ช่วยลด Overfitting ได้หรือไม่?
Cross-Validation เป็นการป้องกันการใส่มากเกินไป แนวคิดคือเราใช้ข้อมูลเริ่มต้นของเราที่ใช้ในชุดการฝึกเพื่อรับการทดสอบแยกย่อยจำนวนมาก จากนั้นเราใช้การแยกเหล่านี้เพื่อปรับแต่งโมเดลของเรา ใน k-fold Cross-Validation ปกติ เราแบ่งข้อมูลออกเป็น k เซตย่อย ซึ่งจากนั้นจะเรียกว่า folds
อ่าน: เงินเดือนนักพัฒนา R ในอินเดีย
วิธีการที่ใช้สำหรับการตรวจสอบข้ามใน R
มีหลายวิธีที่นักวิทยาศาสตร์ข้อมูลใช้สำหรับ ประสิทธิภาพการ ตรวจสอบข้าม เราพูดถึงบางส่วนของพวกเขาที่นี่
1. วิธีตั้งค่าการตรวจสอบ
วิธีการตรวจสอบชุดตรวจสอบคือวิธีการที่ใช้ในการประเมินอัตราข้อผิดพลาดในแบบจำลองโดยการสร้างชุดข้อมูลการทดสอบ เราสร้างแบบจำลองโดยใช้การสังเกตอีกชุดหนึ่ง หรือที่เรียกว่าชุดข้อมูลการฝึกอบรม ผลลัพธ์ของแบบจำลองจะถูกนำไปใช้กับชุดข้อมูลการทดสอบ จากนั้นเราสามารถคำนวณข้อผิดพลาดชุดข้อมูลการทดสอบได้ ดังนั้นจึงช่วยให้โมเดลไม่สวมทับ
รหัสอาร์:
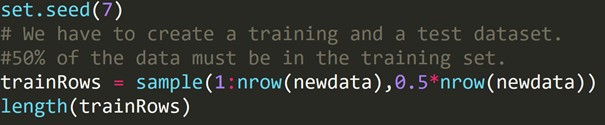
เราได้เขียนโค้ดข้างต้นเพื่อสร้างชุดข้อมูลการฝึกอบรมและชุดข้อมูลการทดสอบอื่น ดังนั้นเราจึงใช้ชุดข้อมูลการฝึกอบรมเพื่อสร้างแบบจำลองการคาดการณ์ จากนั้นจะนำไปใช้กับชุดข้อมูลการทดสอบเพื่อตรวจสอบอัตราข้อผิดพลาด
2. การตรวจสอบความถูกต้องแบบปล่อยครั้งเดียวออก (LOOCV)
Leave-one-out Cross-Validation (LOOCV) เป็นรูปแบบหลายมิติของ Cross-Validation ของ k เท่า จำนวนการพับและหมายเลขอินสแตนซ์ในชุดข้อมูลจะเท่ากัน อัลกอริทึมการเรียนรู้จะทำงานเพียงครั้งเดียวในทุกกรณี ในสถิติ มีกระบวนการคล้ายคลึงกันที่เรียกว่าการประมาณค่าแจ็คมีด
ข้อมูลโค้ด R:
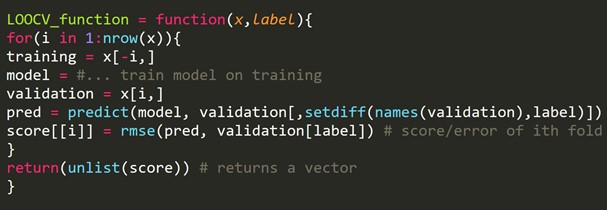
เราสามารถปล่อยตัวอย่างการฝึกอบรมออกไป ซึ่งจะสร้างชุดการตรวจสอบความถูกต้องที่มีขนาดเท่ากันสำหรับการทำซ้ำแต่ละครั้ง กระบวนการนี้เรียกว่า LPOCV (Leave P Out Cross Validation)

3. k-Fold Cross-Validation
ขั้นตอนการสุ่มตัวอย่างถูกใช้ในตัวอย่างข้อมูลที่จำกัดสำหรับการประเมินแบบจำลองการเรียนรู้ของเครื่อง
ขั้นตอนเริ่มต้นด้วยการกำหนดพารามิเตอร์เดียว ซึ่งหมายถึงจำนวนกลุ่มที่จะแยกตัวอย่างข้อมูลที่กำหนด ดังนั้น โพรซีเดอร์นี้จึงถูกตั้งชื่อเป็น k-fold Cross -Validation
นักวิทยาศาสตร์ด้านข้อมูลมักใช้ Cross-Validation ในแมชชีนเลิร์นนิงประยุกต์เพื่อประเมินคุณสมบัติของโมเดลแมชชีนเลิร์นนิงกับข้อมูลที่ไม่ได้ใช้
ค่อนข้างเข้าใจง่าย มักจะส่งผลให้การประเมินทักษะแบบจำลองมีความลำเอียงน้อยลงหรือมากเกินไป เช่น ชุดรถไฟธรรมดาหรือชุดทดสอบ
ขั้นตอนทั่วไปสร้างขึ้นด้วยขั้นตอนง่ายๆ ไม่กี่ขั้นตอน:
- เราต้องผสมชุดข้อมูลเพื่อสุ่ม
- จากนั้นเราแบ่งชุดข้อมูลออกเป็น k กลุ่มที่มีขนาดใกล้เคียงกัน
- สำหรับแต่ละกลุ่มที่ไม่ซ้ำกัน:
เราต้องใช้กลุ่มเป็นชุดข้อมูลทดสอบเฉพาะ จากนั้นเราจะพิจารณากลุ่มที่เหลือทั้งหมดเป็นชุดข้อมูลการฝึกอบรมทั้งหมด จากนั้นเราก็ใส่โมเดลในชุดการฝึกและเพื่อยืนยันผลลัพธ์ เรารันบนชุดทดสอบ เราจดคะแนนการประเมินไว้
ข้อมูลโค้ด R:

4. Stratified k-fold Cross-Validation
การแบ่งชั้นเป็นการจัดเรียงข้อมูลใหม่เพื่อให้แน่ใจว่าการพับแต่ละครั้งเป็นตัวแทนที่มีประโยชน์ พิจารณาปัญหาการจัดประเภทไบนารี โดยมีข้อมูลแต่ละชั้น 50%
เมื่อต้องรับมือกับทั้งอคติและความแปรปรวน stratified k-fold Cross Validation เป็นวิธีที่ดีที่สุด
ข้อมูลโค้ด R:

5. การตรวจสอบฝ่ายตรงข้าม
แนวคิดพื้นฐานคือการตรวจสอบเปอร์เซ็นต์ของความคล้ายคลึงกันในคุณสมบัติและการกระจายระหว่างการฝึกอบรมและการทดสอบ ถ้ามันไม่ง่ายที่จะแยกความแตกต่าง การแจกแจงก็เหมือนกันทุกวิถีทาง และวิธีการตรวจสอบทั่วไปก็ควรจะได้ผล
ในขณะที่จัดการกับชุดข้อมูลจริง มีบางกรณีที่ชุดทดสอบและชุดฝึกแตกต่างกันมาก เทคนิคการ ตรวจสอบข้าม ภายใน จะสร้างคะแนน ไม่ใช่ภายในขอบเขตของคะแนนการทดสอบ ที่นี่ การตรวจสอบฝ่ายตรงข้ามเข้ามามีบทบาท
จะตรวจสอบระดับความคล้ายคลึงกันในการฝึกอบรมและการทดสอบเกี่ยวกับการกระจายคุณลักษณะ การตรวจสอบนี้มีจุดเด่นโดยการรวมชุดฝึกและชุดทดสอบ ติดป้ายกำกับศูนย์หรือหนึ่ง (ศูนย์ – ฝึก การทดสอบครั้งเดียว) และการวิเคราะห์งานการจัดหมวดหมู่คะแนนไบนารี
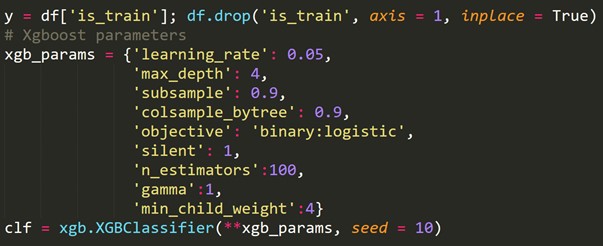
เราต้องสร้างตัวแปรเป้าหมายใหม่ ซึ่งก็คือ 1 สำหรับแต่ละแถวในชุดรถไฟ และ 0 สำหรับแต่ละแถวในชุดทดสอบ
ตอนนี้เรารวมชุดข้อมูลรถไฟและทดสอบ
![]()
เมื่อใช้ตัวแปรเป้าหมายที่สร้างขึ้นใหม่ข้างต้น เราจะปรับโมเดลการจำแนกประเภทและคาดการณ์ความน่าจะเป็นของแต่ละแถวให้อยู่ในชุดทดสอบ
6. การตรวจสอบข้ามสำหรับอนุกรมเวลา
ไม่สามารถแบ่งชุดข้อมูลอนุกรมเวลาแบบสุ่มได้เนื่องจากส่วนเวลาทำให้ข้อมูลยุ่งเหยิง ในปัญหาอนุกรมเวลา เราทำ Cross-Validation ดังที่แสดงด้านล่าง
สำหรับอนุกรมเวลา Cross-Validation เราสร้างการพับในรูปแบบของการส่งต่อโซ่
ตัวอย่างเช่น หากเป็นเวลา n ปี เรามีอนุกรมเวลาสำหรับความต้องการของผู้บริโภครายปีสำหรับผลิตภัณฑ์หนึ่งๆ เราทำการพับดังนี้:
พับ 1: กลุ่มฝึกอบรม 1, กลุ่มทดสอบ 2
พับ 2: กลุ่มฝึกอบรม 1,2 กลุ่มทดสอบ 3
พับ 3: กลุ่มฝึก 1,2,3, กลุ่มทดสอบ 4
พับ 4: กลุ่มฝึกอบรม 1,2,3,4 กลุ่มทดสอบ 5
พับ 5: กลุ่มฝึกอบรม 1,2,3,4,5, กลุ่มทดสอบ 6
.
.
.
พับ n: กลุ่มฝึกอบรม 1 ถึง n-1, กลุ่มทดสอบ n
รถไฟขบวนใหม่และชุดทดสอบจะถูกเลือกไปเรื่อย ๆ เริ่มแรก เราเริ่มต้นด้วยชุดรถไฟที่มีจำนวนการสังเกตขั้นต่ำที่จำเป็นสำหรับการปรับโมเดล เราจะค่อยๆ เปลี่ยนรถไฟและชุดทดสอบของเราทีละน้อย
ข้อมูลโค้ด R:

ชั่วโมง = 1 หมายความว่าเราคำนึงถึงข้อผิดพลาดสำหรับการคาดการณ์ล่วงหน้า 1 ก้าว
เรียนรู้ หลักสูตรวิทยาศาสตร์ข้อมูล จากมหาวิทยาลัยชั้นนำของโลก รับโปรแกรม PG สำหรับผู้บริหาร โปรแกรมประกาศนียบัตรขั้นสูง หรือโปรแกรมปริญญาโท เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
จะวัดความแปรปรวนอคติของแบบจำลองได้อย่างไร?
ด้วย k-fold Cross-Validation เราได้รับข้อผิดพลาดในการประมาณค่าโมเดล k ที่หลากหลาย สำหรับโมเดลในอุดมคติ ข้อผิดพลาดจะรวมกันเป็นศูนย์ สำหรับโมเดลที่จะส่งคืนอคติ ค่าเฉลี่ยของข้อผิดพลาดทั้งหมดจะถูกนำมาและปรับขนาด ค่าเฉลี่ยที่ต่ำกว่าถือว่ามีค่าสำหรับโมเดล
สำหรับการคำนวณความแปรปรวนของแบบจำลอง เราใช้ค่าเบี่ยงเบนมาตรฐานของข้อผิดพลาดทั้งหมด โมเดลของเราไม่มีตัวแปรด้วยชุดย่อยของข้อมูลการฝึกที่แตกต่างกัน หากค่าเบี่ยงเบนมาตรฐานมีค่าน้อย
ควรเน้นที่ความสมดุลระหว่างอคติและความแปรปรวน หากเราลดความแปรปรวนและควบคุมความเอนเอียงของแบบจำลอง เราจะสามารถเข้าถึงสมดุลได้ในระดับหนึ่ง ในที่สุดก็จะสร้างแบบจำลองสำหรับการทำนายที่ดีขึ้น
อ่านเพิ่มเติม: Cross-Validation ใน Python: ทุกสิ่งที่คุณจำเป็นต้องรู้
ห่อ
ในบทความนี้ เราได้กล่าวถึง Cross-Validation และการประยุกต์ใช้ใน R นอกจากนี้ เรายังได้เรียนรู้วิธีหลีกเลี่ยงการใช้มากเกินไป เรายังกล่าวถึงขั้นตอนต่างๆ เช่น แนวทางชุดตรวจสอบความถูกต้อง LOOCV k-fold Cross-Validation และ stratified k-fold ตามด้วยการนำแต่ละวิธีไปใช้ใน R ที่ทำกับชุดข้อมูล Iris
การเขียนโปรแกรม R คืออะไร?
การเขียนโปรแกรม R เป็นภาษาคอมพิวเตอร์และการตั้งค่าซอฟต์แวร์ที่สามารถใช้สำหรับการวิเคราะห์ทางคณิตศาสตร์ การแสดงกราฟิก และการรายงาน มันถูกคิดค้นขึ้นที่มหาวิทยาลัยโอ๊คแลนด์ในนิวซีแลนด์โดย Ross Ihaka และ Robert Gentleman และขณะนี้ทีม R Development Core กำลังพัฒนา การเขียนโปรแกรม R เป็นซอฟต์แวร์ที่เปิดเผยภายใต้สัญญาอนุญาต GNU และมีเวอร์ชันไบนารีที่คอมไพล์ล่วงหน้าสำหรับระบบปฏิบัติการหลายระบบ
จำเป็นต้องมีการตรวจสอบข้ามที่ไหน?
เมื่อเราไม่สามารถปรับโมเดลให้พอดีกับข้อมูลการฝึกอบรมในการเรียนรู้ของเครื่อง เราไม่สามารถรับประกันได้ว่าแบบจำลองจะทำงานอย่างมีประสิทธิภาพกับข้อมูลจริง ในการทำเช่นนั้น เราต้องรับประกันว่าแบบจำลองของเราดึงรูปแบบที่ถูกต้องออกจากข้อมูลและไม่ก่อให้เกิดสัญญาณรบกวนมากเกินไป ด้วยเหตุนี้ เราจึงใช้วิธีการตรวจสอบข้าม เราสามารถรับประกันได้ว่าแบบจำลองของเรามีรูปแบบข้อมูลที่ถูกต้องและไม่ก่อให้เกิดสัญญาณรบกวนมากเกินไปด้วยการตรวจสอบความถูกต้อง
แอพพลิเคชั่นของ R คืออะไร?
การเขียนโปรแกรม R ใช้ในหลากหลายอุตสาหกรรม การคำนวณและการวิเคราะห์ทางสถิติดำเนินการโดยนักสถิติและนักศึกษาโดยใช้ R ภาคส่วนต่างๆ เช่น การธนาคาร การดูแลสุขภาพ การผลิต ภาคไอที การเงิน อีคอมเมิร์ซ และโซเชียลมีเดีย ใช้ประโยชน์จากภาษาการเขียนโปรแกรม R R ยังใช้เพื่อวัตถุประสงค์ของรัฐบาล เช่น การเก็บบันทึกและการประมวลผลสำมะโน