
Convalida incrociata in R: utilizzo, modelli e misurazioni
Pubblicato: 2020-10-19Quando ti imbarchi nel mondo della scienza dei dati e dell'apprendimento automatico, c'è sempre la tendenza a iniziare con la creazione di modelli e algoritmi. Tendi a evitare di imparare o di sapere come testare l'efficacia dei modelli nei dati del mondo reale.
La convalida incrociata in R è un tipo di convalida del modello che migliora i processi di convalida di mantenimento dando la preferenza a sottoinsiemi di dati e comprendendo il compromesso di distorsione o varianza per ottenere una buona comprensione delle prestazioni del modello quando applicato oltre i dati che abbiamo addestrato su. Questo articolo sarà una guida dall'inizio alla fine per la convalida del modello di dati e chiarirà la necessità della convalida del modello.
Sommario
L'instabilità dei modelli di apprendimento
Per capire questo, utilizzeremo queste immagini per illustrare l'adattamento della curva di apprendimento di vari modelli:
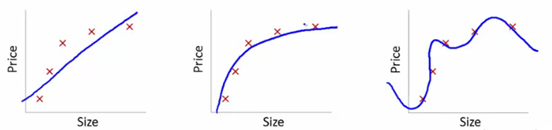
Fonte
Abbiamo mostrato qui il modello appreso di dipendenza dal prezzo dell'articolo sulla taglia.
Abbiamo creato un'equazione di trasformazione lineare adatta tra queste per mostrare i grafici.
Dai set point di allenamento, la prima trama è erronea. Pertanto, sul set di prova, non ha prestazioni eccezionali. Quindi, possiamo dire che questo è "Underfitting". In questo caso, il modello non è in grado di comprendere il modello effettivo nei dati.
Il grafico successivo mostra la corretta dipendenza dal prezzo e dalle dimensioni. Rappresenta un errore di addestramento minimo. Pertanto, la relazione è generalizzata.
Nell'ultima trama, stabiliamo una relazione che non ha quasi nessun errore di allenamento. Costruiamo la relazione considerando ogni fluttuazione nel punto dati e il rumore. Il modello di dati è molto vulnerabile. L'adattamento si organizza per ridurre al minimo l'errore, generando quindi schemi complicati nel set di dati fornito. Questo è noto come "Overfitting". In questo caso, potrebbe esserci una differenza maggiore tra i set di allenamento e di test.
Nel mondo della scienza dei dati, tra i vari modelli, c'è alla ricerca di un modello che funzioni meglio. Ma a volte, è difficile capire se questo punteggio migliorato è dovuto al fatto che la relazione viene catturata meglio o semplicemente i dati si adattano troppo. Usiamo queste tecniche di validazione per avere le soluzioni corrette. Con la presente otteniamo anche un modello più generalizzato tramite queste tecniche.
Che cos'è l'overfitting e l'underfitting?
L'underfitting nell'apprendimento automatico si riferisce all'acquisizione di modelli insufficienti. Quando eseguiamo il modello su set di addestramento e test, le prestazioni sono molto scarse.
Overfitting nell'apprendimento automatico significa catturare rumore e schemi. Questi non si generalizzano bene ai dati che non sono stati sottoposti a training. Quando eseguiamo il modello sul set di allenamento, si comporta molto bene, ma si comporta male quando viene eseguito sul set di prova.
Che cos'è la convalida incrociata?
La convalida incrociata mira a testare la capacità del modello di fare una previsione di nuovi dati non utilizzati nella stima in modo da segnalare problemi come overfitting o bias di selezione. Inoltre, vengono fornite informazioni sulla generalizzazione del database.
Passaggi per organizzare la convalida incrociata :
- Teniamo da parte un set di dati come campione.
- Ci sottoponiamo all'addestramento del modello con l'altra parte del set di dati.
- Usiamo il set di campioni riservato per i test. Questo set aiuta a quantificare le prestazioni convincenti del modello.
Validazione del modello statistico
Nelle statistiche, la convalida del modello conferma che i risultati accettabili di un modello statistico sono generati dai dati reali. Assicura che gli output del modello statistico siano derivati dagli output del processo di generazione dei dati in modo che gli obiettivi principali del programma siano elaborati in modo completo.
La convalida generalmente non viene valutata solo sui dati che sono stati utilizzati nella costruzione del modello, ma utilizza anche i dati che non sono stati utilizzati nella costruzione. Quindi, la convalida di solito verifica alcune delle previsioni del modello.
A cosa serve la convalida incrociata?
La convalida incrociata viene utilizzata principalmente nell'apprendimento automatico applicato per la stima dell'abilità del modello sui dati futuri. In altre parole, utilizziamo un determinato campione per stimare le prestazioni generalmente previste del modello mentre si effettuano previsioni sui dati non utilizzati durante l'addestramento del modello.
La convalida incrociata riduce l'overfitting?
La Cross-Validation è una forte azione protettiva contro l'overfitting. L'idea è che utilizziamo i nostri dati iniziali utilizzati nei set di addestramento per ottenere molte divisioni di test treno più piccole. Quindi usiamo queste divisioni per mettere a punto il nostro modello. Nella normale convalida incrociata di k-fold , dividiamo i dati in k sottoinsiemi che vengono quindi chiamati fold.
Leggi: Stipendio per sviluppatori R in India
Metodi utilizzati per la convalida incrociata in R
Esistono molti metodi utilizzati dai data scientist per le prestazioni di convalida incrociata . Ne discutiamo alcuni qui.
1. Approccio al set di convalida
L'approccio del set di convalida è un metodo utilizzato per stimare il tasso di errore in un modello creando un set di dati di test. Costruiamo il modello utilizzando l'altro set di osservazioni, noto anche come set di dati di addestramento. Il risultato del modello viene quindi applicato al set di dati di test. Possiamo quindi calcolare l'errore del set di dati di test. Pertanto, consente ai modelli di non adattarsi troppo.
Codice R:
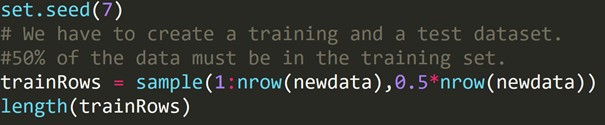
Abbiamo scritto il codice sopra per creare un set di dati di addestramento e un set di dati di test diverso. Pertanto, utilizziamo il set di dati di addestramento per costruire un modello predittivo. Quindi verrà applicato al set di dati di test per verificare i tassi di errore.
2. Convalida incrociata leave-one-out (LOOCV)
La convalida incrociata leave-one-out (LOOCV) è un certo tipo multidimensionale di convalida incrociata di k pieghe. Qui il numero di pieghe e il numero di istanza nel set di dati sono gli stessi. Per ogni istanza, l'algoritmo di apprendimento viene eseguito solo una volta. Nelle statistiche, esiste un processo simile chiamato stima del coltello a serramanico.
Frammento di codice R:
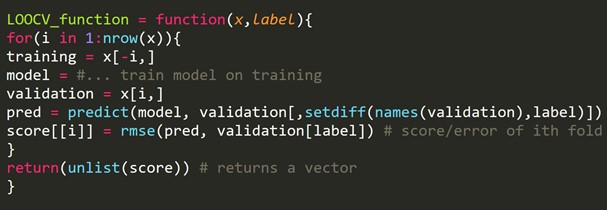
Possiamo tralasciare alcuni esempi di addestramento, che creeranno un set di convalida della stessa dimensione per ogni iterazione. Questo processo è noto come LPOCV (Leave P Out Cross Validation)

3. Convalida incrociata k-Fold
Una procedura di ricampionamento è stata utilizzata in un campione di dati limitato per la valutazione di modelli di apprendimento automatico.
La procedura inizia con la definizione di un singolo parametro, che si riferisce al numero di gruppi che un dato campione di dati deve essere suddiviso. Pertanto, questa procedura è denominata k-fold Cross-Convalidation .
I data scientist utilizzano spesso la convalida incrociata nell'apprendimento automatico applicato per stimare le caratteristiche di un modello di apprendimento automatico sui dati non utilizzati.
È relativamente semplice da capire. Spesso si traduce in una stima meno distorta o sovradimensionata dell'abilità del modello come un semplice treno o un set di test.
La procedura generale si costruisce con pochi semplici passaggi:
- Dobbiamo mescolare il set di dati per randomizzarlo.
- Quindi dividiamo il set di dati in k gruppi di dimensioni simili.
- Per ogni gruppo unico:
Dobbiamo prendere un gruppo come un particolare set di dati di test. Quindi consideriamo tutti i gruppi rimanenti come un intero set di dati di allenamento. Quindi inseriamo un modello sul set di allenamento e confermiamo il risultato. Lo eseguiamo sul set di prova. Prendiamo nota del punteggio di valutazione.
Frammento di codice R:

4. Convalida incrociata k-fold stratificata
La stratificazione è una riorganizzazione dei dati per assicurarsi che ogni piega sia un rappresentante sano. Considera un problema di classificazione binaria, con ogni classe del 50% di dati.
Quando si tratta di bias e varianza, la convalida incrociata k-fold stratificata è il metodo migliore.
Frammento di codice R:

5. Convalida in contraddittorio
L'idea di base è quella di verificare la percentuale di somiglianza nelle caratteristiche e la loro distribuzione tra formazione e test. Se non sono facili da differenziare, la distribuzione è, in ogni caso, simile e i metodi generali di convalida dovrebbero funzionare.
Durante la gestione di set di dati effettivi, a volte ci sono casi in cui i set di test e i set di treni sono molto diversi. Le tecniche interne di convalida incrociata generano punteggi, non all'interno dell'arena del punteggio del test. Qui entra in gioco la convalida del contraddittorio.
Verifica il grado di somiglianza all'interno della formazione e verifica la distribuzione delle caratteristiche. Questa convalida è caratterizzata dall'unione di treni e set di test, etichettando zero o uno (treno zero, un test) e analizzando un'attività di classificazione dei punteggi binari.
Dobbiamo creare una nuova variabile target che è 1 per ogni riga nel set di treni e 0 per ogni riga nel set di test.
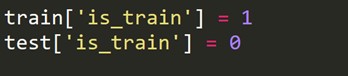
Ora combiniamo i set di dati del treno e del test.
![]()
Utilizzando la variabile target appena creata sopra, adattiamo un modello di classificazione e prevediamo che le probabilità di ogni riga siano nel set di test.
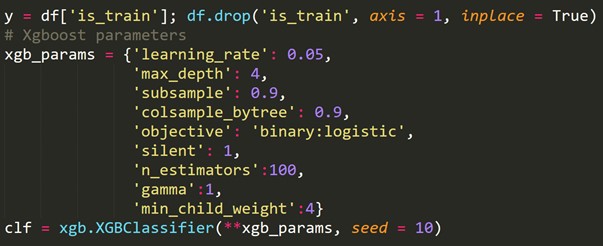
6. Convalida incrociata per serie temporali
Un set di dati di serie temporali non può essere suddiviso in modo casuale poiché la sezione temporale confonde i dati. In un problema di serie temporali, eseguiamo la convalida incrociata come mostrato di seguito.
Per la convalida incrociata delle serie temporali , creiamo pieghe come catene di inoltro.
Se, ad esempio, per n anni, abbiamo una serie temporale per la domanda annuale dei consumatori per un particolare prodotto. Facciamo le pieghe in questo modo:
piega 1: gruppo di allenamento 1, gruppo di prova 2
piega 2: gruppo di allenamento 1,2, gruppo di prova 3
piega 3: gruppo di allenamento 1,2,3, gruppo di prova 4
piega 4: gruppo di allenamento 1,2,3,4, gruppo di prova 5
piega 5: gruppo di allenamento 1,2,3,4,5, gruppo di prova 6
.
.
.
piega n: gruppo di allenamento da 1 a n-1, gruppo di prova n
Un nuovo treno e un set di prova vengono progressivamente selezionati. Inizialmente, iniziamo con un convoglio con un numero minimo di osservazioni necessarie per l'adattamento del modello. A poco a poco, ad ogni piega, cambiamo treno e set di prova.
Frammento di codice R:

h = 1 significa che prendiamo in considerazione l'errore per le previsioni di 1 passo avanti.
Impara i corsi di scienza dei dati dalle migliori università del mondo. Guadagna programmi Executive PG, programmi di certificazione avanzati o programmi di master per accelerare la tua carriera.
Come misurare la variazione di polarizzazione del modello?
Con k-fold Cross-Validation , otteniamo vari k errori di stima del modello. Per un modello ideale, gli errori si sommano a zero. Affinché il modello restituisca la sua distorsione, viene presa e ridimensionata la media di tutti gli errori. La media inferiore è considerata apprezzabile per il modello.
Per il calcolo della varianza del modello, prendiamo la deviazione standard di tutti gli errori. Il nostro modello non è variabile con diversi sottoinsiemi di dati di addestramento se la deviazione standard è minore.
L'obiettivo dovrebbe essere quello di avere un equilibrio tra bias e varianza. Se riduciamo la varianza e la distorsione del modello di controllo, possiamo essere in grado di raggiungere l'equilibrio in una certa misura. Alla fine creerà un modello per una migliore previsione.
Leggi anche: Convalida incrociata in Python: tutto ciò che devi sapere
Avvolgendo
In questo articolo, abbiamo discusso della convalida incrociata e della sua applicazione in R. Abbiamo anche appreso metodi per evitare l'overfitting. Abbiamo anche discusso diverse procedure come l'approccio del set di convalida, LOOCV, k-fold Cross-Validation e k-fold stratificato, seguiti dall'implementazione di ciascun approccio in R eseguita sul set di dati Iris.
Che cos'è la programmazione R?
La programmazione R è un linguaggio informatico e un'impostazione software che può essere utilizzata per l'analisi matematica, la rappresentazione grafica e il reporting. È stato inventato all'Università di Auckland in Nuova Zelanda da Ross Ihaka e Robert Gentleman, e il R Development Core Team lo sta attualmente sviluppando. La programmazione R è un software apertamente disponibile sotto la licenza GNU e sono disponibili versioni binarie precompilate per diversi sistemi operativi.
Dove è richiesta la convalida incrociata?
Quando non siamo in grado di adattare il modello ai dati di addestramento nell'apprendimento automatico, non possiamo garantire che il modello funzioni in modo efficace su dati reali. Per fare ciò, dobbiamo garantire che il nostro modello abbia estratto i modelli corretti dai dati e non abbia generato rumore eccessivo. Per questo motivo utilizziamo il metodo della convalida incrociata. Possiamo garantire che i nostri modelli abbiano lo schema di dati corretto e non generino rumore eccessivo con la convalida incrociata.
Quali sono le applicazioni di R?
La programmazione R è utilizzata in un'ampia gamma di settori. I calcoli e le analisi statistiche vengono eseguiti da statistici e studenti che utilizzano R. Diversi settori come quello bancario, sanitario, manifatturiero, settore IT, finanza, e-commerce e social media utilizzano il linguaggio di programmazione R. R viene anche utilizzato per scopi governativi come la conservazione dei registri e l'elaborazione del censimento.