
Validare încrucișată în R: utilizare, modele și măsurare
Publicat: 2020-10-19Când porniți în călătoria dvs. în lumea științei datelor și a învățării automate, există întotdeauna tendința de a începe cu crearea de modele și algoritmi. Ai tendința de a evita să înveți sau să știi cum să testezi eficiența modelelor în datele din lumea reală.
Validarea încrucișată în R este un tip de validare a modelului care îmbunătățește procesele de validare prin acordarea de preferință subseturi de date și înțelegerea distorsiunii sau a compromisului de varianță pentru a obține o bună înțelegere a performanței modelului atunci când este aplicat dincolo de datele pe care le-am antrenat. pe. Acest articol va fi un ghid de la început până la sfârșit pentru validarea modelului de date și va elucida necesitatea validării modelului.
Cuprins
Instabilitatea modelelor de învățare
Pentru a înțelege acest lucru, vom folosi aceste imagini pentru a ilustra potrivirea curbei de învățare a diferitelor modele:
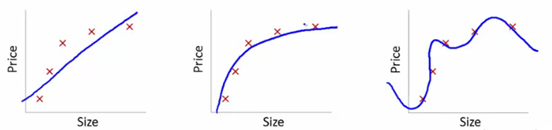
Sursă
Am arătat aici modelul învățat al dependenței de prețul articolului pe dimensiune.
Am făcut o ecuație de transformare liniară care se potrivește între acestea pentru a arăta diagramele.
Din punctele de referință de antrenament, primul complot este eronat. Astfel, pe setul de testare, nu funcționează grozav. Deci, putem spune că acesta este „Subfitting”. Aici, modelul nu este capabil să înțeleagă modelul real în date.
Următorul diagramă arată dependența corectă de preț față de dimensiune. Prezintă o eroare minimă de antrenament. Astfel, relația este generalizată.
În ultimul complot, stabilim o relație care nu are aproape deloc eroare de antrenament. Construim relația luând în considerare fiecare fluctuație a punctului de date și a zgomotului. Modelul de date este foarte vulnerabil. Potrivirea se aranjează pentru a minimiza eroarea, generând astfel modele complicate în setul de date dat. Acest lucru este cunoscut sub denumirea de „suprafitting”. Aici, ar putea exista o diferență mai mare între seturile de antrenament și de testare.
În lumea științei datelor, dintre diverse modele, există o căutare pentru un model care are performanțe mai bune. Dar, uneori, este greu de înțeles dacă acest scor îmbunătățit se datorează faptului că relația este capturată mai bine sau doar pentru că datele sunt prea mari. Folosim aceste tehnici de validare pentru a avea soluțiile corecte. Prin intermediul acestor tehnici, obținem și un model mai bine generalizat.
Ce este Suprafitting & Underfitting?
Subadaptarea în învățarea automată se referă la capturarea modelelor insuficiente. Când rulăm modelul pe seturi de antrenament și de testare, acesta funcționează foarte slab.
Supraadaptarea în învățarea automată înseamnă capturarea zgomotului și a modelelor. Acestea nu se generalizează bine la datele care nu au fost instruite. Când rulăm modelul pe setul de antrenament, acesta funcționează extrem de bine, dar funcționează prost atunci când rulează pe setul de testare.
Ce este validarea încrucișată?
Validarea încrucișată își propune să testeze capacitatea modelului de a face o predicție a datelor noi care nu sunt utilizate în estimare, astfel încât să fie semnalate probleme precum supraajustarea sau părtinirea selecției. De asemenea, se oferă o perspectivă asupra generalizării bazei de date.
Pași pentru organizarea validării încrucișate :
- Păstrăm deoparte un set de date ca specimen de probă.
- Facem antrenamentul modelului cu cealaltă parte a setului de date.
- Folosim setul de mostre rezervat pentru testare. Acest set ajută la cuantificarea performanței convingătoare a modelului.
Validarea modelului statistic
În statistică, validarea modelului confirmă că rezultatele acceptabile ale unui model statistic sunt generate din datele reale. Se asigură că rezultatele modelului statistic sunt derivate din ieșirile procesului de generare a datelor, astfel încât obiectivele principale ale programului să fie procesate în detaliu.
Validarea este, în general, evaluată nu numai pe baza datelor care au fost utilizate în construcția modelului, dar utilizează și date care nu au fost utilizate în construcție. Deci, validarea testează de obicei unele dintre predicțiile modelului.
La ce folosește validarea încrucișată?
Validarea încrucișată este utilizată în principal în învățarea automată aplicată pentru estimarea abilităților modelului asupra datelor viitoare. Adică, folosim un eșantion dat pentru a estima modul în care modelul este de așteptat să performeze în timp ce facem predicții asupra datelor neutilizate în timpul antrenamentului modelului.
Validarea încrucișată reduce supraadaptarea?
Validarea încrucișată este o acțiune puternică de protecție împotriva supraajustării. Ideea este că folosim datele noastre inițiale utilizate în seturile de antrenament pentru a obține multe diviziuni mai mici de tren-test. Apoi folosim aceste diviziuni pentru reglarea modelului nostru. În validarea încrucișată normală cu k-fold , împărțim datele în k subseturi care sunt apoi numite pliuri.
Citiți: Salariu pentru dezvoltatori R în India
Metode utilizate pentru validarea încrucișată în R
Există multe metode pe care oamenii de știință le folosesc pentru performanța de validare încrucișată . Pe unele dintre ele le discutăm aici.
1. Abordarea setului de validare
Abordarea setului de validare este o metodă utilizată pentru a estima rata de eroare într-un model prin crearea unui set de date de testare. Construim modelul folosind celălalt set de observații, cunoscut și sub numele de setul de date de antrenament. Rezultatul modelului este apoi aplicat setului de date de testare. Apoi putem calcula eroarea setului de date de testare. Astfel, permite modelelor să nu se supraîntâlnească.
cod R:
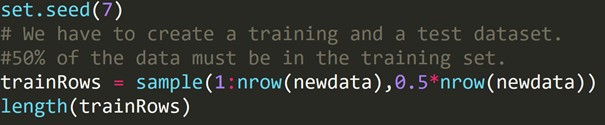
Am scris codul de mai sus pentru a crea un set de date de antrenament și un set de date de testare diferit. Prin urmare, folosim setul de date de antrenament pentru a construi un model predictiv. Apoi va fi aplicat setului de date de testare pentru a verifica ratele de eroare.
2. Validare încrucișată cu excepție (LOOCV)
Leave-one-out Cross-Validation (LOOCV) este un anumit tip multidimensional de Cross-Validation a k pliuri. Aici numărul de pliuri și numărul instanței din setul de date sunt aceleași. Pentru fiecare caz, algoritmul de învățare rulează o singură dată. În statistică, există un proces similar numit estimare jack-knife.
Fragment de cod R:
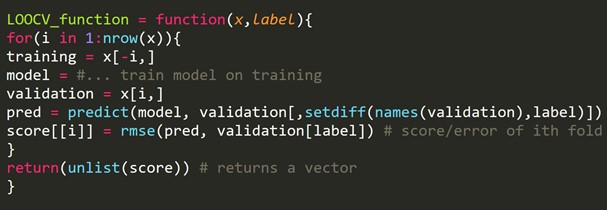
Putem lăsa afară câteva exemple de antrenament, care vor crea un set de validare de aceeași dimensiune pentru fiecare iterație. Acest proces este cunoscut sub numele de LPOCV (Leave P Out Cross Validation)

3. Validare încrucișată k-Fold
O procedură de reeșantionare a fost utilizată într-un eșantion limitat de date pentru evaluarea modelelor de învățare automată.
Procedura începe cu definirea unui singur parametru, care se referă la numărul de grupuri pe care urmează să fie împărțit un anumit eșantion de date. Astfel, această procedură este denumită validare încrucișată în k-fold .
Oamenii de știință de date folosesc adesea validarea încrucișată în învățarea automată aplicată pentru a estima caracteristicile unui model de învățare automată pe date neutilizate.
Este relativ simplu de înțeles. Adesea, rezultă o estimare mai puțin părtinitoare sau supraadaptată a abilității modelului, cum ar fi un set de tren simplu sau un set de testare.
Procedura generală este construită cu câțiva pași simpli:
- Trebuie să amestecăm setul de date pentru al randomiza.
- Apoi împărțim setul de date în k grupuri de dimensiuni similare.
- Pentru fiecare grup unic:
Trebuie să luăm un grup ca un anumit set de date de testare. Apoi considerăm toate grupurile rămase ca un întreg set de date de antrenament. Apoi punem un model pe setul de antrenament și pentru a confirma rezultatul. Îl rulăm pe setul de testare. Notăm scorul de evaluare.
Fragment de cod R:

4. Validare încrucișată stratificată în k-fold
Stratificarea este o rearanjare a datelor pentru a vă asigura că fiecare pliu este un reprezentant sănătos. Luați în considerare o problemă de clasificare binară, având fiecare clasă de date de 50%.
Când se ocupă atât de părtinire, cât și de varianță, validarea încrucișată stratificată în k-fold este cea mai bună metodă.
Fragment de cod R:

5. Validarea adversară
Ideea de bază este verificarea procentului de similaritate în caracteristici și distribuția acestora între antrenament și teste. Dacă nu sunt ușor de diferențiat, distribuția este, fără îndoială, similară, iar metodele generale de validare ar trebui să funcționeze.
În timp ce se ocupă cu seturi de date reale, există cazuri uneori în care seturile de testare și seturile de trenuri sunt foarte diferite. Tehnicile interne de validare încrucișată generează scoruri, nu în arena scorului testului. Aici intră în joc validarea contradictorie.
Acesta verifică gradul de similitudine în cadrul instruirii și testelor privind distribuția caracteristicilor. Această validare este prezentată prin îmbinarea trenului și seturilor de teste, etichetând zero sau unu (zero – tren, un test) și analizând o sarcină de clasificare a scorurilor binare.
Trebuie să creăm o nouă variabilă țintă care este 1 pentru fiecare rând din setul de tren și 0 pentru fiecare rând din setul de testare.
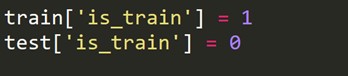
Acum combinăm seturile de date tren și test.
![]()
Folosind variabila țintă nou creată de mai sus, adaptăm un model de clasificare și anticipăm probabilitățile fiecărui rând să fie în setul de testare.
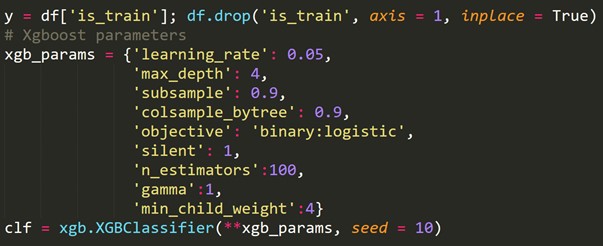
6. Validare încrucișată pentru serii de timp
Un set de date în serie de timp nu poate fi împărțit aleatoriu, deoarece secțiunea de timp încurcă datele. Într-o problemă de serie temporală, efectuăm validarea încrucișată, așa cum se arată mai jos.
Pentru validarea încrucișată a seriilor de timp , creăm pliuri într-un mod de lanțuri de expediere.
Dacă, de exemplu, pentru n ani, avem o serie de timp pentru cererea anuală a consumatorilor pentru un anumit produs. Facem pliurile astfel:
fold 1: grupa de antrenament 1, grupa de testare 2
pliul 2: grupa de antrenament 1, 2, grupa de testare 3
fold 3: antrenament grup 1,2,3, test grup 4
fold 4: grupa de antrenament 1,2,3,4, grupa de testare 5
fold 5: antrenament grup 1,2,3,4,5, test grup 6
.
.
.
fold n: grupa de antrenament 1 la n-1, grupa de testare n
Un nou tren și un set de testare sunt selectate progresiv. Inițial, începem cu o garnitură de tren cu un număr minim de observații necesare pentru montarea modelului. Treptat, cu fiecare îndoire, ne schimbăm trenul și seturile de testare.
Fragment de cod R:

h = 1 înseamnă că luăm în considerare eroarea pentru prognozele cu 1 pas înainte.
Învață cursuri de știință a datelor de la cele mai bune universități din lume. Câștigă programe Executive PG, programe avansate de certificat sau programe de master pentru a-ți accelera cariera.
Cum se măsoară varianța de părtinire a modelului?
Cu k-fold Cross-Validation , obținem diverse erori de estimare a modelului k. Pentru un model ideal, erorile se însumează la zero. Pentru ca modelul să-și returneze părtinirea, media tuturor erorilor este luată și scalată. Media mai mică este considerată apreciabilă pentru model.
Pentru calcularea varianței modelului, luăm abaterea standard a tuturor erorilor. Modelul nostru nu este variabil cu diferite subseturi de date de antrenament dacă abaterea standard este minoră.
Accentul ar trebui să fie pe a avea un echilibru între părtinire și variație. Dacă reducem varianța și părtinirea modelului de control, putem fi capabili să ajungem la echilibru într-o oarecare măsură. În cele din urmă, va face un model pentru o predicție mai bună.
Citiți și: Validarea încrucișată în Python: tot ce trebuie să știți
Încheierea
În acest articol, am discutat despre validarea încrucișată și aplicarea acesteia în R. Am învățat și metode pentru a evita supraadaptarea. Am discutat, de asemenea, diferite proceduri precum abordarea setului de validare, LOOCV, validarea încrucișată cu k-fold și k-fold stratificat, urmate de implementarea fiecărei abordări în R efectuată pe setul de date Iris.
Ce este programarea R?
Programarea R este un limbaj de calcul și o setare software care poate fi utilizată pentru analiză matematică, reprezentare grafică și raportare. A fost inventat la Universitatea Auckland din Noua Zeelandă de către Ross Ihaka și Robert Gentleman, iar R Development Core Team îl dezvoltă în prezent. Programarea R este un software disponibil în mod deschis sub Licența GNU și sunt disponibile versiuni binare pre-compilate pentru mai multe sisteme de operare.
Unde este necesară validarea încrucișată?
Atunci când nu putem încadra modelul pe datele de antrenament în învățarea automată, nu putem garanta că modelul va funcționa eficient pe date reale. Pentru a face acest lucru, trebuie să garantăm că modelul nostru a extras modelele corecte din date și nu a generat zgomot excesiv. Din acest motiv, folosim metoda de validare încrucișată. Putem garanta că modelele noastre au modelul de date corect și că nu generează zgomot excesiv cu validarea încrucișată.
Care sunt aplicațiile lui R?
Programarea R este utilizată într-o gamă largă de industrii. Calculele și analizele statistice sunt efectuate de statisticieni și studenți care folosesc R. Diferite sectoare precum bancar, sănătate, producție, sector IT, finanțe, comerț electronic și social media folosesc limbajul de programare R. R este folosit chiar și în scopuri guvernamentale, cum ar fi păstrarea înregistrărilor și procesarea recensământului.