
Kreuzvalidierung in R: Verwendung, Modelle und Messung
Veröffentlicht: 2020-10-19Wenn Sie Ihre Reise in die Welt der Datenwissenschaft und des maschinellen Lernens beginnen, besteht immer die Tendenz, mit der Modellerstellung und den Algorithmen zu beginnen. Sie neigen dazu, es zu vermeiden, zu lernen oder zu wissen, wie man die Effektivität der Modelle anhand von Daten aus der realen Welt testet.
Die Kreuzvalidierung in R ist eine Art der Modellvalidierung, die Hold-out-Validierungsprozesse verbessert, indem Teilmengen von Daten bevorzugt werden und der Bias- oder Varianz-Trade-off verstanden wird, um ein gutes Verständnis der Modellleistung zu erhalten, wenn sie über die von uns trainierten Daten hinaus angewendet wird an. Dieser Artikel ist ein Leitfaden für die Datenmodellvalidierung von Anfang bis Ende und erläutert die Notwendigkeit der Modellvalidierung.
Inhaltsverzeichnis
Die Instabilität von Lernmodellen
Um dies zu verstehen, werden wir diese Bilder verwenden, um die Lernkurvenanpassung verschiedener Modelle zu veranschaulichen:
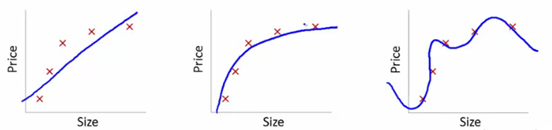
Quelle
Wir haben hier das erlernte Modell der Abhängigkeit des Artikelpreises von der Größe gezeigt.
Wir haben eine lineare Transformationsgleichung erstellt, die zwischen diesen passt, um die Diagramme zu zeigen.
Von den Trainingssollwerten ist der erste Plot fehlerhaft. Auf dem Testgerät schneidet es daher nicht besonders gut ab. Wir können also sagen, dass dies „Underfitting“ ist. Hier ist das Modell nicht in der Lage, das tatsächliche Muster in den Daten zu verstehen.
Das nächste Diagramm zeigt die korrekte Abhängigkeit des Preises von der Größe. Es zeigt minimale Trainingsfehler. Somit wird die Beziehung verallgemeinert.
Im letzten Diagramm stellen wir eine Beziehung her, die fast überhaupt keinen Trainingsfehler aufweist. Wir bauen die Beziehung auf, indem wir jede Schwankung im Datenpunkt und das Rauschen berücksichtigen. Das Datenmodell ist sehr anfällig. Die Anpassung ordnet sich selbst an, um den Fehler zu minimieren, wodurch komplizierte Muster im gegebenen Datensatz erzeugt werden. Dies wird als „Overfitting“ bezeichnet. Hier kann es zu einem größeren Unterschied zwischen Trainings- und Test-Sets kommen.
In der Welt der Datenwissenschaft wird aus verschiedenen Modellen nach einem Modell gesucht, das eine bessere Leistung erbringt. Aber manchmal ist es schwer zu verstehen, ob diese verbesserte Punktzahl darauf zurückzuführen ist, dass die Beziehung besser erfasst wird, oder ob die Daten einfach zu stark angepasst sind. Wir verwenden diese Validierungstechniken, um die richtigen Lösungen zu erhalten. Hiermit erhalten wir über diese Techniken auch ein besser verallgemeinertes Muster.
Was ist Overfitting und Underfitting?
Underfitting beim maschinellen Lernen bezieht sich auf das Erfassen unzureichender Muster. Wenn wir das Modell auf Trainings- und Testsätzen ausführen, schneidet es sehr schlecht ab.
Überanpassung beim maschinellen Lernen bedeutet, Rauschen und Muster zu erfassen. Diese lassen sich nicht gut auf die Daten verallgemeinern, die nicht trainiert wurden. Wenn wir das Modell auf dem Trainingsset ausführen, funktioniert es sehr gut, aber es schneidet schlecht ab, wenn es auf dem Testset ausgeführt wird.
Was ist Kreuzvalidierung?
Die Kreuzvalidierung zielt darauf ab, die Fähigkeit des Modells zu testen, eine Vorhersage neuer Daten zu treffen, die nicht in der Schätzung verwendet werden, sodass Probleme wie Überanpassung oder Auswahlverzerrung gekennzeichnet werden. Außerdem wird ein Einblick in die Verallgemeinerung der Datenbank gegeben.
Schritte zur Organisation der Kreuzvalidierung :
- Wir halten einen Datensatz als Musterexemplar bereit.
- Mit dem anderen Teil des Datensatzes durchlaufen wir das Modelltraining.
- Wir verwenden den reservierten Mustersatz zum Testen. Dieses Set hilft bei der Quantifizierung der überzeugenden Leistung des Modells.
Statistische Modellvalidierung
In der Statistik bestätigt die Modellvalidierung, dass die akzeptablen Ergebnisse eines statistischen Modells aus den realen Daten generiert werden. Es stellt sicher, dass die Ergebnisse des statistischen Modells von den Ergebnissen des datenerzeugenden Prozesses abgeleitet werden, so dass die Hauptziele des Programms gründlich verarbeitet werden.
Die Validierung wird im Allgemeinen nicht nur auf Daten ausgewertet, die in der Modellkonstruktion verwendet wurden, sondern es werden auch Daten verwendet, die nicht in der Konstruktion verwendet wurden. Daher testet die Validierung normalerweise einige der Vorhersagen des Modells.
Wozu dient die Kreuzvalidierung?
Kreuzvalidierung wird hauptsächlich im angewandten maschinellen Lernen zur Schätzung der Fähigkeit des Modells für zukünftige Daten verwendet. Das heißt, wir verwenden eine bestimmte Stichprobe, um abzuschätzen, wie das Modell im Allgemeinen voraussichtlich funktionieren wird, während wir während des Modelltrainings Vorhersagen zu ungenutzten Daten treffen.
Reduziert Cross-Validation Overfitting?
Cross-Validation ist eine starke Schutzmaßnahme gegen Overfitting. Die Idee ist, dass wir unsere Anfangsdaten verwenden, die in Trainingssätzen verwendet werden, um viele kleinere Trainings-Test-Splits zu erhalten. Dann verwenden wir diese Splits zum Tunen unseres Modells. Bei der normalen k-fachen Kreuzvalidierung teilen wir die Daten in k Teilmengen auf, die dann Falten genannt werden.
Lesen Sie: R-Entwicklergehalt in Indien
Für die Kreuzvalidierung in R verwendete Methoden
Es gibt viele Methoden, die Data Scientists für die Cross-Validation- Leistung verwenden. Wir diskutieren einige davon hier.
1. Validierungsset-Ansatz
Der Validation Set Approach ist eine Methode zur Schätzung der Fehlerrate in einem Modell durch die Erstellung eines Testdatensatzes. Wir erstellen das Modell unter Verwendung des anderen Beobachtungssatzes, der auch als Trainingsdatensatz bekannt ist. Das Modellergebnis wird dann auf den Testdatensatz angewendet. Wir können dann den Testdatensatzfehler berechnen. Somit können Modelle nicht überangepasst werden.
R-Code:
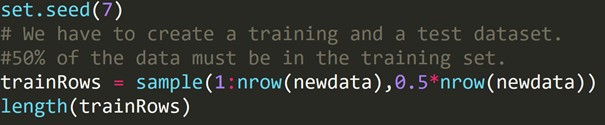
Wir haben den obigen Code geschrieben, um einen Trainingsdatensatz und einen anderen Testdatensatz zu erstellen. Daher verwenden wir den Trainingsdatensatz, um ein Vorhersagemodell zu erstellen. Dann wird es auf den Testdatensatz angewendet, um die Fehlerraten zu überprüfen.
2. Leave-One-Out-Kreuzvalidierung (LOOCV)
Leave-one-out Cross-Validation ( LOOCV) ist eine bestimmte mehrdimensionale Art der Kreuzvalidierung von k-Falten. Hier sind die Anzahl der Faltungen und die Instanznummer im Datensatz gleich. Für jede Instanz wird der Lernalgorithmus nur einmal ausgeführt. In der Statistik gibt es einen ähnlichen Prozess, der als Jack-Knife-Schätzung bezeichnet wird.
R-Code-Snippet:
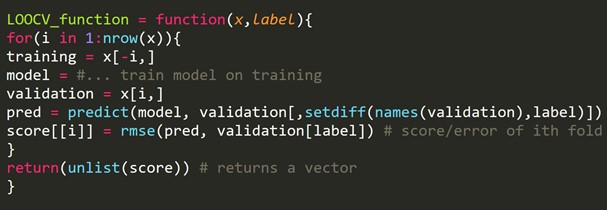

Wir können einige Trainingsbeispiele weglassen, wodurch für jede Iteration ein Validierungssatz derselben Größe erstellt wird. Dieser Prozess ist als LPOCV (Leave P Out Cross Validation) bekannt.
3. k-fache Kreuzvalidierung
Ein Resampling-Verfahren wurde in einer begrenzten Datenstichprobe für die Bewertung von Machine-Learning-Modellen verwendet.
Das Verfahren beginnt mit der Definition eines einzelnen Parameters, der sich auf die Anzahl der Gruppen bezieht, die eine gegebene Datenprobe aufzuteilen ist. Daher wird dieses Verfahren als k-fache Kreuzvalidierung bezeichnet .
Datenwissenschaftler verwenden beim angewandten maschinellen Lernen häufig die Kreuzvalidierung , um Merkmale eines maschinellen Lernmodells für ungenutzte Daten zu schätzen.
Es ist vergleichsweise einfach zu verstehen. Dies führt häufig zu einer weniger verzerrten oder überangepassten Schätzung der Modellfertigkeit wie bei einem einfachen Zug- oder Testsatz.
Das allgemeine Verfahren besteht aus wenigen einfachen Schritten:
- Wir müssen den Datensatz mischen, um ihn zu randomisieren.
- Dann teilen wir den Datensatz in k Gruppen ähnlicher Größe auf.
- Für jede einzigartige Gruppe:
Wir müssen eine Gruppe als einen bestimmten Testdatensatz nehmen. Dann betrachten wir alle verbleibenden Gruppen als einen ganzen Trainingsdatensatz. Dann passen wir ein Modell an das Trainingsset an und bestätigen das Ergebnis. Wir führen es auf dem Testset aus. Wir notieren die Bewertungsnote.
R-Code-Snippet:

4. Geschichtete k-fache Kreuzvalidierung
Schichtung ist eine Neuanordnung von Daten, um sicherzustellen, dass jede Faltung ein gesunder Repräsentant ist. Stellen Sie sich ein binäres Klassifizierungsproblem vor, bei dem jede Klasse zu 50 % aus Daten besteht.
Beim Umgang mit Bias und Varianz ist die stratifizierte k-fache Kreuzvalidierung die beste Methode.
R-Code-Snippet:

5. Kontradiktorische Validierung
Die Grundidee besteht darin, den Prozentsatz der Ähnlichkeit von Merkmalen und ihre Verteilung zwischen Training und Tests zu überprüfen. Wenn sie nicht leicht zu unterscheiden sind, ist die Verteilung durchaus ähnlich, und die allgemeinen Validierungsmethoden sollten funktionieren.
Beim Umgang mit tatsächlichen Datensätzen gibt es manchmal Fälle, in denen die Testsätze und Zugsätze sehr unterschiedlich sind. Die internen Cross-Validation- Techniken generieren Ergebnisse, die nicht im Bereich der Testergebnisse liegen. Hier kommt die kontradiktorische Validierung ins Spiel.
Es prüft den Grad der Ähnlichkeit innerhalb von Training und Tests zur Merkmalsverteilung. Diese Validierung wird durch das Zusammenführen von Trainings- und Testsets, das Kennzeichnen von Null oder Eins (Null – Trainieren, Eins-Test) und das Analysieren einer Klassifizierungsaufgabe von binären Bewertungen gekennzeichnet.
Wir müssen eine neue Zielvariable erstellen, die für jede Zeile im Zugsatz 1 und für jede Zeile im Testsatz 0 ist.
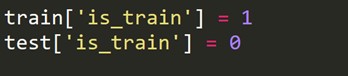
Jetzt kombinieren wir die Zug- und Testdatensätze.
![]()
Unter Verwendung der oben neu erstellten Zielvariablen passen wir ein Klassifizierungsmodell an und sagen die Wahrscheinlichkeiten jeder Zeile voraus, in der Testmenge zu sein.
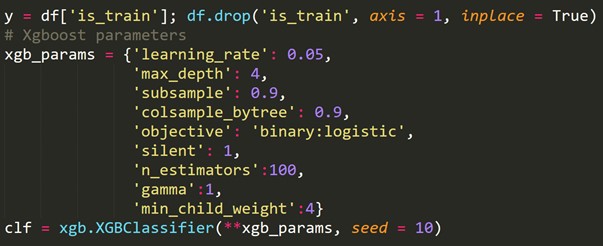
6. Kreuzvalidierung für Zeitreihen
Ein Zeitreihendatensatz kann nicht zufällig aufgeteilt werden, da der Zeitabschnitt die Daten durcheinander bringt. Bei einem Zeitreihenproblem führen wir eine Kreuzvalidierung wie unten gezeigt durch.
Für die Cross-Validation von Zeitreihen erstellen wir Faltungen in Form von Weiterleitungsketten.
Wenn wir zum Beispiel für n Jahre eine Zeitreihe für die jährliche Verbrauchernachfrage nach einem bestimmten Produkt haben. Wir machen die Falten so:
Falte 1: Trainingsgruppe 1, Testgruppe 2
Falte 2: Trainingsgruppe 1,2, Testgruppe 3
Falte 3: Trainingsgruppe 1,2,3, Testgruppe 4
Falte 4: Trainingsgruppe 1,2,3,4, Testgruppe 5
Falte 5: Trainingsgruppe 1,2,3,4,5, Testgruppe 6
.
.
.
fold n: Trainingsgruppe 1 bis n-1, Testgruppe n
Ein neuer Zug und ein neuer Testsatz werden nach und nach ausgewählt. Zunächst beginnen wir mit einem Zugset mit einer minimalen Anzahl von Beobachtungen, die zum Anpassen des Modells erforderlich sind. Nach und nach ändern wir mit jeder Faltung unsere Zug- und Testsets.
R-Code-Snippet:

h = 1 bedeutet, dass wir den Fehler für 1-Schritt-Voraus-Prognosen berücksichtigen.
Lernen Sie Datenwissenschaftskurse von den besten Universitäten der Welt. Verdienen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.
Wie misst man die Bias-Varianz des Modells?
Mit k-facher Kreuzvalidierung erhalten wir verschiedene k Modellschätzungsfehler. Bei einem idealen Modell summieren sich die Fehler zu Null. Damit das Modell seine Verzerrung zurückgibt, wird der Durchschnitt aller Fehler genommen und skaliert. Der untere Durchschnitt wird für das Modell als spürbar angesehen.
Für die Modellvarianzberechnung nehmen wir die Standardabweichung aller Fehler. Unser Modell ist nicht variabel mit unterschiedlichen Teilmengen von Trainingsdaten, wenn die Standardabweichung gering ist.
Der Fokus sollte auf einem Gleichgewicht zwischen Bias und Varianz liegen. Wenn wir die Varianz reduzieren und die Modellverzerrung kontrollieren, können wir bis zu einem gewissen Grad ein Gleichgewicht erreichen. Es wird schließlich ein Modell für eine bessere Vorhersage erstellen.
Lesen Sie auch: Kreuzvalidierung in Python: Alles, was Sie wissen müssen
Einpacken
In diesem Artikel haben wir die Kreuzvalidierung und ihre Anwendung in R besprochen. Wir haben auch Methoden zur Vermeidung von Überanpassung kennengelernt. Wir haben auch verschiedene Verfahren wie den Validierungssatzansatz , LOOCV, k-fache Kreuzvalidierung und stratifiziertes k-fach besprochen, gefolgt von der Implementierung jedes Ansatzes in R, die am Iris-Datensatz durchgeführt wurde.
Was ist R-Programmierung?
Die R-Programmierung ist eine Computersprache und eine Softwareeinstellung, die für mathematische Analysen, grafische Darstellungen und Berichte verwendet werden kann. Es wurde an der University of Auckland in Neuseeland von Ross Ihaka und Robert Gentleman erfunden und das R Development Core Team entwickelt es derzeit. Die R-Programmierung ist eine frei verfügbare Software unter der GNU-Lizenz, und vorkompilierte Binärversionen für mehrere Betriebssysteme sind verfügbar.
Wo ist eine Kreuzvalidierung erforderlich?
Wenn wir das Modell nicht an die Trainingsdaten beim maschinellen Lernen anpassen können, können wir nicht garantieren, dass das Modell effektiv mit echten Daten funktioniert. Dazu müssen wir garantieren, dass unser Modell die richtigen Muster aus den Daten extrahiert und kein übermäßiges Rauschen erzeugt. Aus diesem Grund verwenden wir die Cross-Validation-Methode. Durch Kreuzvalidierung können wir garantieren, dass unsere Modelle das richtige Datenmuster aufweisen und kein übermäßiges Rauschen erzeugen.
Was sind die Anwendungen von R?
Die R-Programmierung wird in den unterschiedlichsten Branchen eingesetzt. Statistische Berechnungen und Analysen werden von Statistikern und Studenten mit R durchgeführt. Verschiedene Branchen wie Banken, Gesundheitswesen, Fertigung, IT-Sektor, Finanzen, E-Commerce und soziale Medien nutzen die Programmiersprache R. R wird sogar für Regierungszwecke wie Aufzeichnungen und die Verarbeitung von Volkszählungen verwendet.