
R'de Çapraz Doğrulama: Kullanım, Modeller ve Ölçüm
Yayınlanan: 2020-10-19Veri bilimi ve makine öğrenimi dünyasına yolculuğunuza başladığınızda, her zaman model oluşturma ve algoritmalarla başlama eğilimi vardır. Modellerin etkinliğini gerçek dünya verilerinde nasıl test edeceğinizi öğrenmekten veya bilmekten kaçınma eğilimindesiniz.
R'de Çapraz Doğrulama , veri alt kümelerine tercih vererek ve onu eğittiğimiz verilerin ötesinde uygulandığında model performansının iyi bir şekilde anlaşılmasını sağlamak için önyargı veya varyans değişimini anlayarak bekleme doğrulama süreçlerini iyileştiren bir model doğrulama türüdür. üzerinde. Bu makale, veri modeli doğrulaması için baştan sona bir kılavuz olacak ve model doğrulama ihtiyacını açıklayacak.
İçindekiler
Öğrenme Modellerinin Kararsızlığı
Bunu anlamak için, çeşitli modellerin öğrenme eğrisi uyumunu göstermek için bu resimleri kullanacağız:
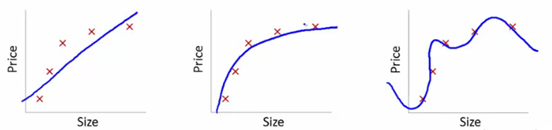
Kaynak
Burada, boyuta göre makale fiyatına öğrenilmiş bağımlılık modelini gösterdik.
Grafikleri göstermek için bunlar arasında doğrusal bir dönüşüm denklemi kurduk.
Eğitim ayar noktalarından ilk arsa hatalı. Dolayısıyla test setinde çok iyi performans göstermiyor. Dolayısıyla bunun “Uygunsuz” olduğunu söyleyebiliriz. Burada model, verilerdeki gerçek kalıbı anlayamamaktadır.
Sonraki grafik, boyuta göre fiyata doğru bağımlılığı gösterir. Minimum eğitim hatasını gösterir. Böylece ilişki genelleştirilir.
Son arsada, neredeyse hiç eğitim hatası olmayan bir ilişki kuruyoruz. Veri noktasındaki her dalgalanmayı ve gürültüyü dikkate alarak ilişkiyi kurarız. Veri modeli çok savunmasız. Uyum, hatayı en aza indirecek şekilde kendini düzenler, bu nedenle verilen veri kümesinde karmaşık modeller oluşturur. Bu, “Fazla Uyum” olarak bilinir. Burada, eğitim ve test setleri arasında daha yüksek bir fark olabilir.
Veri bilimi dünyasında, çeşitli modeller arasından daha iyi performans gösteren bir model aranmaktadır. Ancak bazen, bu iyileştirilmiş puanın, ilişkinin daha iyi yakalanmasından mı yoksa yalnızca verilerin aşırı sığmasından mı kaynaklandığını anlamak zordur. Doğru çözümlere sahip olmak için bu doğrulama tekniklerini kullanıyoruz. Bununla birlikte, bu teknikler aracılığıyla daha iyi genelleştirilmiş bir model elde ediyoruz.
Aşırı Takma ve Yetersiz Takma Nedir?
Makine öğreniminde yetersiz uyum, yetersiz kalıpların yakalanması anlamına gelir. Modeli eğitim ve test setlerinde çalıştırdığımızda çok kötü performans gösteriyor.
Makine öğreniminde fazla uydurma, gürültü ve kalıpları yakalamak anlamına gelir. Bunlar, eğitimden geçmemiş verilere iyi genelleme yapmaz. Modeli eğitim setinde çalıştırdığımızda son derece iyi performans gösteriyor ancak test setinde çalıştırıldığında düşük performans gösteriyor.
Çapraz Doğrulama nedir?
Çapraz Doğrulama , modelin tahminde kullanılmayan yeni veriler hakkında bir tahminde bulunma yeteneğini test etmeyi amaçlar, böylece fazla uyum veya seçim yanlılığı gibi sorunlar işaretlenir. Ayrıca, veritabanının genelleştirilmesi hakkında fikir verilir.
Çapraz Doğrulamayı düzenleme adımları :
- Örnek bir örnek olarak bir veri setini bir kenara bırakıyoruz.
- Veri setinin diğer kısmı ile model eğitiminden geçiyoruz.
- Test için ayrılmış örnek setini kullanıyoruz. Bu set, modelin zorlayıcı performansını ölçmeye yardımcı olur.
İstatistiksel model doğrulama
İstatistikte, model doğrulama, istatistiksel bir modelin kabul edilebilir çıktılarının gerçek verilerden üretildiğini doğrular. Programın ana amaçlarının eksiksiz bir şekilde işlenmesi için istatistiksel model çıktılarının veri üreten süreç çıktılarından türetilmesini sağlar.
Doğrulama genellikle yalnızca model yapımında kullanılan veriler üzerinde değerlendirilmez, aynı zamanda yapımda kullanılmayan verileri de kullanır. Bu nedenle, doğrulama genellikle modelin bazı tahminlerini test eder.
Çapraz doğrulama ne işe yarar?
Çapraz Doğrulama , modelin gelecekteki veriler üzerindeki becerisini tahmin etmek için öncelikle uygulamalı makine öğreniminde kullanılır. Yani, model eğitimi sırasında kullanılmayan veriler üzerinde tahminler yaparken modelin genel olarak nasıl performans göstermesinin beklendiğini tahmin etmek için belirli bir örneği kullanırız.
Çapraz Doğrulama Fazla Takmayı Azaltır mı?
Çapraz Doğrulama , aşırı takmaya karşı güçlü bir koruyucu eylemdir. Buradaki fikir, birçok daha küçük tren-test bölünmeleri elde etmek için eğitim setlerinde kullanılan ilk verilerimizi kullanmamızdır. Sonra bu bölmeleri modelimizi ayarlamak için kullanırız. Normal k-kat Çapraz Doğrulamada , verileri daha sonra kıvrımlar olarak adlandırılan k alt kümeye böleriz.
Okuyun: Hindistan'da R Geliştirici Maaşı
R'de Çapraz Doğrulama için Kullanılan Yöntemler
Veri bilimcilerinin Çapraz Doğrulama performansı için kullandığı birçok yöntem vardır . Bazılarını burada tartışıyoruz.
1. Doğrulama Kümesi Yaklaşımı
Doğrulama Kümesi Yaklaşımı, bir test veri kümesi oluşturarak bir modeldeki hata oranını tahmin etmek için kullanılan bir yöntemdir. Modeli, eğitim veri seti olarak da bilinen diğer gözlem setini kullanarak oluşturuyoruz. Model sonucu daha sonra test veri kümesine uygulanır. Daha sonra test veri seti hatasını hesaplayabiliriz. Böylece modellerin fazla takılmamasını sağlar.
R kodu:
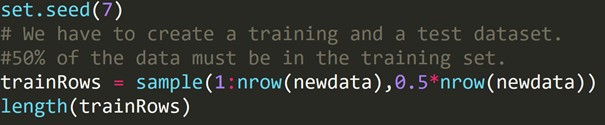
Yukarıdaki kodu bir eğitim veri seti ve farklı bir test veri seti oluşturmak için yazdık. Bu nedenle, tahmine dayalı bir model oluşturmak için eğitim veri setini kullanıyoruz. Daha sonra hata oranlarını kontrol etmek için test veri setine uygulanacaktır.
2. Birini dışarıda bırakma çapraz doğrulaması (LOOCV)
Birini dışarıda bırakma Çapraz Doğrulama (LOOCV), k katın belirli bir çok boyutlu Çapraz Doğrulama türüdür . Burada veri setindeki kat sayısı ve örnek numarası aynıdır. Her örnek için, öğrenme algoritması yalnızca bir kez çalışır. İstatistikte, jack-knife tahmini adı verilen benzer bir süreç vardır.
R Kodu Snippet'i:
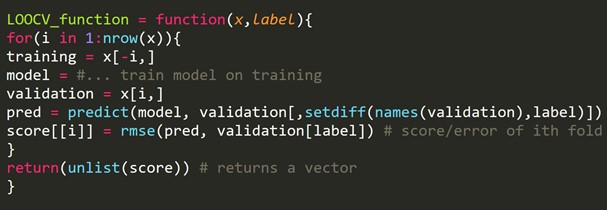

Her yineleme için aynı boyutta bir doğrulama seti oluşturacak bazı eğitim örneklerini dışarıda bırakabiliriz. Bu işlem LPOCV (Çıkış P Çıkışı Çapraz Doğrulama) olarak bilinir.
3. k-Katlama Çapraz Doğrulama
Makine öğrenimi modellerinin değerlendirilmesi için sınırlı bir veri örneğinde yeniden örnekleme prosedürü kullanıldı.
Prosedür, belirli bir veri örneğinin bölüneceği grup sayısını ifade eden tek bir parametrenin tanımlanmasıyla başlar. Bu nedenle, bu prosedür k-katlı Çapraz Doğrulama olarak adlandırılır .
Veri bilimcileri , kullanılmayan veriler üzerinde bir makine öğrenimi modelinin özelliklerini tahmin etmek için uygulamalı makine öğreniminde genellikle Çapraz Doğrulamayı kullanır.
Bunu anlamak nispeten basittir. Genellikle basit bir tren seti veya test seti gibi model becerisinin daha az önyargılı veya fazla uydurulmuş bir tahminiyle sonuçlanır.
Genel prosedür birkaç basit adımla oluşturulmuştur:
- Rastgele hale getirmek için veri setini karıştırmalıyız.
- Daha sonra veri setini benzer büyüklükteki k gruba böldük.
- Her benzersiz grup için:
Belirli bir test veri seti olarak bir grup almalıyız. Ardından kalan tüm grupları bir bütün eğitim veri seti olarak ele alıyoruz. Daha sonra eğitim setine bir model yerleştirip sonucu teyit ediyoruz. Test setinde çalıştırıyoruz. Değerlendirme puanını not ediyoruz.
R kodu Snippet'i:

4. Tabakalı k-kat Çapraz Doğrulama
Tabakalandırma, her katın sağlıklı bir temsilci olmasını sağlamak için verilerin yeniden düzenlenmesidir. Her bir sınıfın %50 veriye sahip olduğu bir ikili sınıflandırma problemi düşünün.
Hem sapma hem de varyansla uğraşırken, tabakalı k-kat Çapraz Doğrulama en iyi yöntemdir.
R Kodu Snippet'i:

5. Düşmanca Doğrulama
Temel fikir, özelliklerdeki benzerlik yüzdesini ve bunların eğitim ile testler arasındaki dağılımını kontrol etmektir. Ayırt edilmeleri kolay değilse, dağıtım elbette benzerdir ve genel doğrulama yöntemleri işe yaramalıdır.
Gerçek veri kümeleriyle uğraşırken, bazen test kümelerinin ve tren kümelerinin çok farklı olduğu durumlar vardır. Dahili Çapraz Doğrulama teknikleri, test puanı alanında değil, puanlar üretir. Burada, karşıt doğrulama devreye giriyor.
Özellik dağılımı ile ilgili eğitim ve testler içindeki benzerlik derecesini kontrol eder. Bu doğrulama, dizi ve test setlerini birleştirerek, sıfır veya bir (sıfır – dizi, bir test) olarak etiketleyerek ve ikili puanların bir sınıflandırma görevini analiz ederek öne çıkar.
Tren setindeki her satır için 1 ve test setindeki her satır için 0 olan yeni bir hedef değişken oluşturmalıyız.
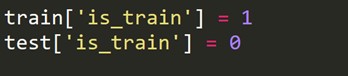
Şimdi tren ve test veri kümelerini birleştiriyoruz.
![]()
Yukarıda yeni oluşturulan hedef değişkeni kullanarak, bir sınıflandırma modeline uyuyoruz ve her satırın test setinde olma olasılıklarını tahmin ediyoruz.
6. Zaman serileri için Çapraz Doğrulama
Bir zaman serisi veri kümesi, zaman bölümü verileri karıştırdığı için rastgele bölünemez. Bir zaman serisi probleminde, aşağıda gösterildiği gibi Çapraz Doğrulama gerçekleştiririz.
Zaman serisi Çapraz Doğrulama için, yönlendirme zincirleri tarzında kıvrımlar yaratırız.
Örneğin, n yıl için, belirli bir ürün için yıllık tüketici talebi için bir zaman serimiz varsa. Kıvrımları şu şekilde yapıyoruz:
kat 1: eğitim grubu 1, test grubu 2
kat 2: eğitim grubu 1,2, test grubu 3
kat 3: eğitim grubu 1,2,3, test grubu 4
kat 4: eğitim grubu 1,2,3,4, test grubu 5
kat 5: eğitim grubu 1,2,3,4,5, test grubu 6
.
.
.
kat n: eğitim grubu 1 ila n-1, test grubu n
Yeni bir tren ve test seti aşamalı olarak seçilir. İlk olarak, modele uydurmak için gereken minimum gözlem sayısı olan bir tren seti ile başlıyoruz. Yavaş yavaş, her katlamada tren ve test setlerimizi değiştiriyoruz.
R Kodu Snippet'i:

h = 1, 1 adım ilerisi tahminleri için hatayı dikkate aldığımız anlamına gelir.
Dünyanın en iyi Üniversitelerinden veri bilimi derslerini öğrenin . Kariyerinizi hızlandırmak için Yönetici PG Programları, Gelişmiş Sertifika Programları veya Yüksek Lisans Programları kazanın.
Modelin önyargı varyansı nasıl ölçülür?
k-kat Çapraz Doğrulama ile çeşitli k model tahmin hataları elde ederiz. İdeal bir model için hataların toplamı sıfırdır. Modelin yanlılığını döndürmesi için tüm hataların ortalaması alınır ve ölçeklenir. Düşük ortalama, model için kayda değer kabul edilir.
Model varyansı hesaplaması için tüm hataların standart sapmasını alıyoruz. Standart sapma küçükse, modelimiz farklı eğitim verisi alt kümeleriyle değişken değildir.
Odak, önyargı ve varyans arasında bir dengeye sahip olmak olmalıdır. Varyansı azaltır ve model yanlılığını kontrol edersek, bir dereceye kadar dengeye ulaşabiliriz. Sonunda daha iyi tahmin için bir model oluşturacaktır.
Ayrıca Okuyun: Python'da Çapraz Doğrulama: Bilmeniz Gereken Her Şey
toparlamak
Bu makalede, Çapraz Doğrulamayı ve R'deki uygulamasını tartıştık. Ayrıca fazla uydurmayı önleme yöntemlerini de öğrendik. Ayrıca doğrulama seti yaklaşımı, LOOCV, k-kat Çapraz Doğrulama ve tabakalı k-kat gibi farklı prosedürleri ve ardından her bir yaklaşımın Iris veri setinde gerçekleştirilen R'deki uygulamasını tartıştık.
R programlama nedir?
R programlama, matematiksel analiz, grafik gösterim ve raporlama için kullanılabilen bir bilgisayar dili ve yazılım ayarıdır. Yeni Zelanda'daki Auckland Üniversitesi'nde Ross Ihaka ve Robert Gentleman tarafından icat edildi ve R Geliştirme Çekirdek Ekibi şu anda onu geliştiriyor. R programlama, GNU Lisansı kapsamında herkese açık bir yazılımdır ve çeşitli işletim sistemleri için önceden derlenmiş ikili sürümler mevcuttur.
Çapraz doğrulama nerede gereklidir?
Makine öğreniminde modeli eğitim verilerine sığdıramadığımızda modelin gerçek veriler üzerinde etkin bir şekilde çalışacağını garanti edemeyiz. Bunu yapmak için, modelimizin verilerden doğru kalıpları çıkardığını ve aşırı gürültü oluşturmadığını garanti etmeliyiz. Bu nedenle çapraz doğrulama yöntemini kullanıyoruz. Modellerimizin doğru veri modeline sahip olduğunu ve çapraz doğrulama ile aşırı gürültü oluşturmadığını garanti edebiliriz.
R'nin uygulamaları nelerdir?
R programlama çok çeşitli endüstrilerde kullanılmaktadır. İstatistiksel hesaplamalar ve analizler istatistikçiler ve öğrenciler tarafından R kullanılarak yapılmaktadır. Bankacılık, Sağlık, İmalat, Bilişim Sektörü, Finans, E-ticaret, Sosyal Medya gibi farklı sektörlerde R programlama dili kullanılmaktadır. R, kayıt tutma ve nüfus sayımı işleme gibi devlet amaçları için bile kullanılır.