
Un'intuizione dietro l'analisi del sentimento: come eseguire l'analisi del sentimento da zero?
Pubblicato: 2020-12-07Sommario
introduzione
Il testo è il mezzo più importante per percepire le informazioni per gli esseri umani. La maggior parte dell'intelligenza acquisita dagli esseri umani avviene attraverso l'apprendimento e la comprensione del significato dei testi e delle frasi che li circondano.
Dopo una certa età, gli esseri umani sviluppano un riflesso intrinseco per comprendere l'inferenza di qualsiasi parola/testo senza nemmeno saperlo. Per le macchine, questo compito è completamente diverso. Per assimilare i significati di testi e frasi, le macchine si basano sui fondamenti del Natural Language Processing (NLP).
Il deep learning per l'elaborazione del linguaggio naturale è il riconoscimento di schemi applicato a parole, frasi e paragrafi, più o meno allo stesso modo in cui la visione artificiale è il riconoscimento di schemi applicato ai pixel dell'immagine.
Nessuno di questi modelli di deep learning comprende veramente il testo in senso umano; piuttosto, questi modelli possono mappare la struttura statistica della lingua scritta, che è sufficiente per risolvere molti semplici compiti testuali. L'analisi del sentimento è uno di questi compiti, ad esempio: classificare il sentimento di stringhe o recensioni di film come positivo o negativo.
Questi hanno applicazioni su larga scala anche nel settore. Ad esempio: un'azienda di beni e servizi vorrebbe raccogliere i dati del numero di recensioni positive e negative che ha ricevuto per un particolare prodotto per lavorare sul ciclo di vita del prodotto e migliorare i suoi dati di vendita e raccogliere feedback dai clienti.
Preelaborazione
Il compito dell'analisi del sentimento può essere suddiviso in un semplice algoritmo di apprendimento automatico supervisionato, in cui di solito abbiamo un input X , che entra in una funzione predittiva per ottenere Quindi confrontiamo la nostra previsione con il valore reale Y , Questo ci dà il costo che utilizziamo quindi per aggiornare i parametri Per affrontare il compito di estrarre i sentimenti da un flusso di testi mai visto in precedenza, il passaggio primitivo consiste nel raccogliere un set di dati etichettato con sentimenti positivi e negativi separati. Questi sentimenti possono essere: recensione positiva o negativa, commento sarcastico o commento non sarcastico, ecc.
Il passaggio successivo consiste nel creare un vettore di dimensione V , dove Questo vettore di vocabolario conterrà ogni parola (nessuna parola viene ripetuta) che è presente nel nostro set di dati e fungerà da lessico per la nostra macchina a cui può fare riferimento. Ora pre-processiamo il vettore del vocabolario per rimuovere le ridondanze. Vengono eseguiti i seguenti passaggi:
- Eliminazione di URL e altre informazioni non banali (che non aiutano a determinare il significato di una frase)
- Tokenizzare la stringa in parole: supponiamo di avere la stringa "I love machine learning", ora tokenizzando semplicemente spezziamo la frase in singole parole e la memorizziamo in un elenco come [I, love, machine, learning]
- Rimozione di parole chiave come "e", "sono", "o", "io", ecc.
- Stemming: trasformiamo ogni parola nella sua forma radice. Parole come "tune", "tuning" e "tuned" hanno semanticamente lo stesso significato, quindi riducendole alla sua forma radice che è "tun" si ridurrà la dimensione del vocabolario
- Conversione di tutte le parole in minuscolo
Per riassumere la fase di preelaborazione, diamo un'occhiata a un esempio: supponiamo di avere una stringa positiva "Amo il nuovo prodotto su upGrad.com" . La stringa finale preelaborata si ottiene rimuovendo l'URL, tokenizzando la frase in un unico elenco di parole, rimuovendo le parole di stop come "I, am, the, at", quindi derivando le parole "loving" in "lov" e "product" in "produ" e infine convertendo tutto in minuscolo che risulta nell'elenco [lov, new, produ] .
Estrazione di funzionalità
Dopo che il corpus è stato preelaborato, il passo successivo sarebbe quello di estrarre le caratteristiche dall'elenco delle frasi. Come tutte le altre reti neurali, i modelli di deep learning non accettano come input il testo grezzo: funzionano solo con tensori numerici. L'elenco di parole preelaborato deve quindi essere convertito in valori numerici. Questo può essere fatto nel modo seguente. Supponiamo che data una compilazione di stringhe con stringhe positive e negative come (supponiamo che questo sia il set di dati) :
| Stringhe positive | Stringhe negative |
|
|
Ora, per convertire ciascuna di queste stringhe in un vettore numerico di dimensione 3, creiamo un dizionario per mappare la parola e la classe in cui è apparsa (positiva o negativa) al numero di volte in cui quella parola è apparsa nella classe corrispondente.
| Vocabolario | Frequenza positiva | Frequenza negativa |
| io | 3 | 3 |
| sono | 3 | 3 |
| felice | 2 | 0 |
| perché | 1 | 0 |
| apprendimento | 1 | 1 |
| PNL | 1 | 1 |
| triste | 0 | 2 |
| non | 0 | 1 |
Dopo aver generato il suddetto dizionario, esaminiamo ciascuna delle stringhe individualmente, quindi sommiamo il numero positivo e il numero di frequenza negativo delle parole che compaiono nella stringa lasciando le parole che non compaiono nella stringa. Prendiamo la stringa '"Sono triste, non sto imparando la PNL" e generiamo il vettore della dimensione 3.

"Sono triste, non sto imparando la PNL"
| Vocabolario | Frequenza positiva | Frequenza negativa |
| io | 3 | 3 |
| sono | 3 | 3 |
| felice | 2 | 0 |
| perché | 1 | 0 |
| apprendimento | 1 | 1 |
| PNL | 1 | 1 |
| triste | 0 | 2 |
| non | 0 | 1 |
| Somma = 8 | Somma = 11 |
Vediamo che per la stringa “Sono triste, non sto imparando la PNL”, solo due parole “felice, perché” non sono contenute nel vocabolario, ora per estrarre le caratteristiche e creare il detto vettore, sommiamo la frequenza positiva e negativa colonne separatamente tralasciando il numero di frequenza delle parole che non sono presenti nella stringa, in questo caso lasciamo “felice, perché”. Otteniamo la somma come 8 per la frequenza positiva e 9 per la frequenza negativa.
Quindi, la stringa "Sono triste, non sto imparando la PNL" può essere rappresentata come un vettore Il numero “1” presente nell'indice 0 è l'unità di polarizzazione che rimarrà “1” per tutte le stringhe successive ei numeri “8”, “11” rappresentano rispettivamente la somma delle frequenze positive e negative.
In modo simile, tutte le stringhe nel set di dati possono essere comodamente convertite in un vettore di dimensione 3.
Per saperne di più: Analisi del sentimento utilizzando Python: una guida pratica
Applicazione della regressione logistica
L'estrazione delle caratteristiche semplifica la comprensione dell'essenza della frase, ma le macchine hanno ancora bisogno di un modo più nitido per contrassegnare una stringa invisibile in positiva o negativa. Qui entra in gioco la regressione logistica che utilizza la funzione sigmoide che restituisce una probabilità compresa tra 0 e 1 per ogni stringa vettorizzata.

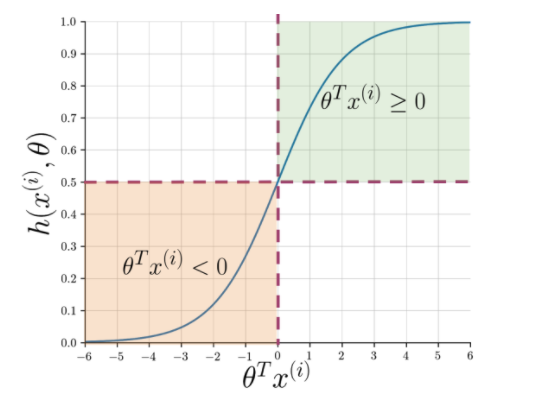
Figura 1: notazione grafica della funzione sigmoidea
La Figura 1 mostra che ogni volta che il prodotto scalare di theta e Leggi anche: Le 4 migliori idee per progetti di analisi dei dati: da principiante a esperto
Cosa succede dopo?
L'analisi del sentimento è un argomento essenziale nell'apprendimento automatico. Ha numerose applicazioni in più campi. Se vuoi saperne di più su questo argomento, puoi visitare il nostro blog e trovare molte nuove risorse.
D'altra parte, se vuoi ottenere un'esperienza di apprendimento completa e strutturata, anche se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al Diploma PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, stato di Alumni IIIT-B, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
Q1. Perché l'algoritmo Random Forest è il migliore per l'apprendimento automatico?
L'algoritmo Random Forest appartiene alla categoria degli algoritmi di apprendimento supervisionato, ampiamente utilizzati nello sviluppo di diversi modelli di apprendimento automatico. L'algoritmo della foresta casuale può essere applicato sia per i modelli di classificazione che per i modelli di regressione. Ciò che rende questo algoritmo il più adatto per l'apprendimento automatico è il fatto che funziona brillantemente con informazioni ad alta dimensione poiché l'apprendimento automatico si occupa principalmente di sottoinsiemi di dati. È interessante notare che l'algoritmo della foresta casuale è derivato dall'algoritmo degli alberi decisionali. Tuttavia, puoi allenarti utilizzando questo algoritmo in un arco di tempo molto più breve rispetto all'utilizzo di alberi decisionali poiché utilizza solo funzionalità specifiche. Offre una maggiore efficienza nei modelli di apprendimento automatico e quindi è preferito di più.
Q2. In che modo il machine learning è diverso dal deep learning?
Sia il deep learning che il machine learning sono sottocampi dell'intero ombrello che chiamiamo intelligenza artificiale. Tuttavia, questi due sottocampi hanno le loro differenze. Il deep learning è essenzialmente un sottoinsieme del machine learning. Tuttavia, utilizzando il deep learning, le macchine possono analizzare video, immagini e altre forme di dati non strutturati, che possono essere difficili da ottenere utilizzando solo il machine learning. L'apprendimento automatico consiste nel consentire ai computer di pensare e agire da soli, con il minimo intervento umano. Al contrario, il deep learning viene utilizzato per aiutare le macchine a pensare in base a strutture simili al cervello umano.
Q3. Perché i data scientist preferiscono l'algoritmo della foresta casuale?
Ci sono molti vantaggi nell'utilizzo dell'algoritmo della foresta casuale, che lo rendono la scelta preferita dai data scientist. In primo luogo, fornisce risultati estremamente accurati rispetto ad altri algoritmi lineari come la regressione logistica e lineare. Anche se questo algoritmo può essere difficile da spiegare, è più facile ispezionare e interpretare i risultati in base ai suoi alberi decisionali sottostanti. È possibile utilizzare questo algoritmo con la stessa facilità anche quando vengono aggiunti nuovi campioni e funzionalità. È facile da usare anche quando mancano alcuni dati.