
6 tipi di funzione di attivazione nelle reti neurali che devi conoscere
Pubblicato: 2020-02-13Con il Deep Learning che sta diventando una tecnologia mainstream, ultimamente si è parlato molto di ANN o di reti neurali artificiali. Oggi, ANN è un componente fondamentale in diversi domini emergenti come il riconoscimento della grafia, la compressione delle immagini, la previsione di borsa e molto altro ancora. Ulteriori informazioni sui tipi di reti neurali artificiali nell'apprendimento automatico.
Ma cos'è una rete neurale artificiale?
La rete neurale artificiale è un modello di apprendimento profondo che trae ispirazione dalla struttura neurale del cervello umano. Le RNA sono state progettate per imitare le funzioni del cervello umano che apprendono dalle esperienze e si adattano di conseguenza alla situazione. Come il cervello umano ha una struttura a più livelli contenente miliardi di neuroni disposti in una gerarchia, l'ANN ha anche una rete di neuroni interconnessi tra loro tramite assoni.
Questi neuroni interconnessi trasmettono segnali elettrici (chiamati sinapsi) da uno strato all'altro. Questa imitazione della modellazione cerebrale consente all'ANN di imparare dall'esperienza senza richiedere l'intervento umano.
Leggi: Rete neurale artificiale nel data mining
Pertanto, le ANN sono strutture complesse contenenti elementi adattivi interconnessi noti come neuroni artificiali che possono eseguire calcoli di grandi dimensioni per la rappresentazione della conoscenza. Possiedono tutte le qualità fondamentali del sistema neuronale biologico, tra cui capacità di apprendimento, robustezza, non linearità, elevato parallelismo, tolleranza ai guasti e ai guasti, capacità di gestire informazioni imprecise e sfocate e capacità di generalizzazione.

Partecipa ai corsi di intelligenza artificiale online dalle migliori università del mondo: master, programmi post-laurea esecutivi e programma di certificazione avanzata in ML e AI per accelerare la tua carriera.
Sommario
Caratteristiche principali delle reti neurali artificiali
- La non linearità conferisce un migliore adattamento ai dati.
- L'alto parallelismo promuove un'elaborazione rapida e la tolleranza ai guasti hardware.
- La generalizzazione consente l'applicazione del modello ai dati non appresi.
- Insensibilità al rumore che consente una previsione accurata anche per dati incerti ed errori di misurazione.
- L'apprendimento e l'adattabilità consentono al modello di aggiornare la propria architettura interna in base al cambiamento dell'ambiente.
L'informatica basata su ANN mira principalmente a progettare algoritmi matematici avanzati che consentono alle reti neurali artificiali di apprendere imitando l'elaborazione delle informazioni e le funzioni di acquisizione della conoscenza del cervello umano.
Componenti di reti neurali artificiali
Le ANN sono composte da tre livelli o fasi principali: un livello di input, uno o più livelli nascosti e uno di output.
- Livello di input: il primo livello viene alimentato con l'input, ovvero i dati grezzi. Trasmette le informazioni dal mondo esterno alla rete. In questo livello, non viene eseguito alcun calcolo: i nodi trasmettono semplicemente le informazioni al livello nascosto.
- Livello nascosto: in questo livello, i nodi giacciono nascosti dietro il livello di input: costituiscono la parte di astrazione in ogni rete neurale. Tutti i calcoli sulle caratteristiche immesse tramite il livello di input avvengono nei livelli nascosti, quindi trasferisce il risultato al livello di output.
- Livello di output: questo livello rappresenta i risultati dei calcoli eseguiti dalla rete nel mondo esterno.
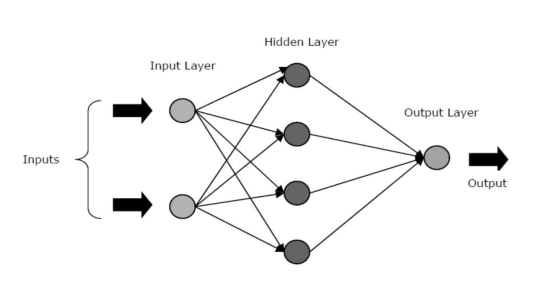
Fonte
Le reti neurali possono essere classificate in diversi tipi in base all'attività degli strati nascosti. Ad esempio, in una semplice rete neurale, le unità nascoste possono costruire la loro rappresentazione univoca dell'input. Qui, i pesi tra le unità nascoste e di input decidono quando ciascuna unità nascosta è attiva.
Pertanto, regolando questi pesi, il livello nascosto può scegliere cosa rappresentare. Altre architetture includono i modelli a strato singolo e multistrato. In un singolo livello, di solito c'è solo un livello di input e output: manca un livello nascosto. Mentre, in un modello multistrato, c'è uno o più di un livello nascosto.
Cosa sono le funzioni di attivazione in una rete neurale?
Come accennato in precedenza, le RNA sono una componente cruciale di molte strutture che stanno contribuendo a rivoluzionare il mondo che ci circonda. Ma ti sei mai chiesto, in che modo le ANN offrono prestazioni all'avanguardia per trovare soluzioni ai problemi del mondo reale?
La risposta è: Funzioni di attivazione.
Le ANN utilizzano le funzioni di attivazione (AF) per eseguire calcoli complessi nei livelli nascosti e quindi trasferire il risultato al livello di output. Lo scopo principale degli AF è quello di introdurre proprietà non lineari nella rete neurale.
Convertono i segnali di ingresso lineari di un nodo in segnali di uscita non lineari per facilitare l'apprendimento di polinomi di ordine elevato che vanno oltre un grado per le reti profonde. Un aspetto unico degli AF è che sono differenziabili: questo li aiuta a funzionare durante la backpropagation delle reti neurali.
Qual è la necessità della non linearità?
Se le funzioni di attivazione non vengono applicate, il segnale di uscita sarebbe una funzione lineare, che è un polinomio di un grado. Sebbene sia facile risolvere le equazioni lineari, hanno un quoziente di complessità limitato e, quindi, hanno meno potenza per apprendere mappature funzionali complesse dai dati. Pertanto, senza AF, una rete neurale sarebbe un modello di regressione lineare con capacità limitate.
Questo non è certamente ciò che vogliamo da una rete neurale. Il compito delle reti neurali è calcolare calcoli molto complicati. Inoltre, senza AF, le reti neurali non possono apprendere e modellare altri dati complicati, inclusi immagini, parlato, video, audio, ecc.
Gli AF aiutano le reti neurali a dare un senso a insiemi di Big Data complicati, ad alta dimensione e non lineari che hanno un'architettura complessa: contengono più livelli nascosti tra il livello di input e quello di output.
Leggi: Deep Learning Vs rete neurale
Ora, senza ulteriori indugi, analizziamo i diversi tipi di funzioni di attivazione utilizzate nelle RNA.
Tipi di funzioni di attivazione
1. Funzione sigmoidea
In una RNA, la funzione sigmoidea è un AF non lineare utilizzato principalmente nelle reti neurali feedforward. È una funzione reale differenziabile, definita per valori di input reali e contenente derivate positive ovunque con uno specifico grado di levigatezza. La funzione sigmoide appare nel livello di output dei modelli di deep learning e viene utilizzata per prevedere gli output basati sulla probabilità. La funzione sigmoidea è rappresentata come:
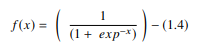
Fonte
Generalmente, le derivate della funzione sigmoidea vengono applicate agli algoritmi di apprendimento. Il grafico della funzione sigmoidea è a forma di "S".
Alcuni dei principali inconvenienti della funzione sigmoidea includono saturazione del gradiente, convergenza lenta, forti gradienti di umidità durante la backpropagation dall'interno di strati nascosti più profondi ai livelli di input e output centrato diverso da zero che fa sì che gli aggiornamenti del gradiente si propaghino in direzioni variabili.

2. Funzione iperbolica tangente (Tanh)
La funzione iperbolica tangente, alias la funzione tanh, è un altro tipo di AF. È una funzione più fluida e centrata sullo zero con un intervallo compreso tra -1 e 1. Di conseguenza, l'output della funzione tanh è rappresentato da:
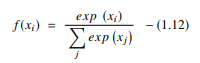
Fonte
La funzione tanh è molto più utilizzata rispetto alla funzione sigmoide poiché offre migliori prestazioni di allenamento per reti neurali multistrato. Il più grande vantaggio della funzione tanh è che produce un output centrato sullo zero, supportando così il processo di backpropagation. La funzione tanh è stata utilizzata principalmente nelle reti neurali ricorrenti per l'elaborazione del linguaggio naturale e le attività di riconoscimento vocale.
Tuttavia, anche la funzione tanh ha una limitazione: proprio come la funzione sigmoide, non può risolvere il problema del gradiente di fuga. Inoltre, la funzione tanh può raggiungere un gradiente di 1 solo quando il valore di input è 0 (x è zero). Di conseguenza, la funzione può produrre alcuni neuroni morti durante il processo di calcolo.
3. Funzione Softmax
La funzione softmax è un altro tipo di AF utilizzato nelle reti neurali per calcolare la distribuzione di probabilità da un vettore di numeri reali. Questa funzione genera un output che varia tra i valori 0 e 1 e con la somma delle probabilità uguale a 1. La funzione softmax è rappresentata come segue:
Fonte
Questa funzione viene utilizzata principalmente nei modelli multiclasse in cui restituisce le probabilità di ciascuna classe, con la classe target che ha la probabilità più alta. Appare in quasi tutti i livelli di output dell'architettura DL in cui vengono utilizzati. La differenza principale tra sigmoide e softmax AF è che mentre il primo viene utilizzato nella classificazione binaria, il secondo viene utilizzato per la classificazione multivariata.
4. Funzione softsign
La funzione softsign è un'altra AF utilizzata nell'elaborazione di reti neurali. Sebbene sia principalmente nei problemi di calcolo della regressione, al giorno d'oggi viene utilizzato anche nelle applicazioni di sintesi vocale basate su DL. È un polinomio quadratico, rappresentato da:
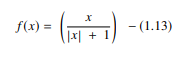
Fonte
Qui “x” è uguale al valore assoluto dell'input.
La principale differenza tra la funzione softsign e la funzione tanh è che, a differenza della funzione tanh che converge in modo esponenziale, la funzione softsign converge in una forma polinomiale.
5. Funzione unità lineare rettificata (ReLU).
Uno degli AF più popolari nei modelli DL, la funzione dell'unità lineare rettificata (ReLU), è un AF ad apprendimento rapido che promette di fornire prestazioni all'avanguardia con risultati stellari. Rispetto ad altri AF come le funzioni sigmoid e tanh, la funzione ReLU offre prestazioni e generalizzazione molto migliori nell'apprendimento profondo. La funzione è una funzione quasi lineare che mantiene le proprietà dei modelli lineari, il che li rende facili da ottimizzare con i metodi di discesa del gradiente.
La funzione ReLU esegue un'operazione di soglia su ciascun elemento di input in cui tutti i valori inferiori a zero sono impostati su zero. Pertanto, la ReLU è rappresentata come:
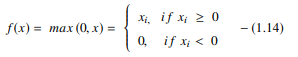
Fonte
Rettificando i valori degli ingressi inferiori a zero e portandoli a zero, questa funzione elimina il problema del gradiente di fuga osservato nei primi tipi di funzioni di attivazione (sigmoide e tanh).
Il vantaggio più significativo dell'utilizzo della funzione ReLU nel calcolo è che garantisce un calcolo più veloce: non calcola esponenziali e divisioni, aumentando così la velocità di calcolo complessiva. Un altro aspetto critico della funzione ReLU è che introduce scarsità nelle unità nascoste schiacciando i valori tra zero e massimo.
6. Funzione di unità lineari esponenziali (ELU).
La funzione di unità lineari esponenziali (ELU) è un AF che viene utilizzato anche per accelerare l'addestramento delle reti neurali (proprio come la funzione ReLU). Il più grande vantaggio della funzione ELU è che può eliminare il problema del gradiente di fuga utilizzando l'identità per valori positivi e migliorando le caratteristiche di apprendimento del modello.
Le ELU hanno valori negativi che spingono l'attivazione dell'unità media più vicino a zero, riducendo così la complessità computazionale e migliorando la velocità di apprendimento. L'ELU è un'ottima alternativa al ReLU: riduce gli spostamenti di polarizzazione spingendo l'attivazione media verso lo zero durante il processo di addestramento.
La funzione dell'unità lineare esponenziale è rappresentata come:
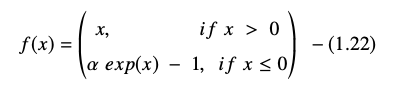
La derivata o il gradiente dell'equazione ELU è presentato come:
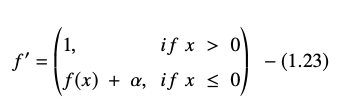
Fonte
Qui "α" è uguale all'iperparametro ELU che controlla il punto di saturazione per input netti negativi, che di solito è impostato su 1.0. Tuttavia, la funzione ELU ha una limitazione: non è centrata sullo zero.
Conclusione
Oggi, AF come ReLU ed ELU hanno guadagnato la massima attenzione poiché aiutano a eliminare il problema del gradiente di fuga che causa gravi problemi nel treno del processo di addestramento e degrada l'accuratezza e le prestazioni dei modelli di rete neurale.
Dai un'occhiata al programma di certificazione avanzato in Machine Learning e cloud con IIT Madras, la migliore scuola di ingegneria del paese per creare un programma che ti insegni non solo l'apprendimento automatico ma anche l'efficace implementazione di esso utilizzando l'infrastruttura cloud. Il nostro obiettivo con questo programma è quello di aprire le porte dell'istituto più selettivo del paese e dare agli studenti l'accesso a facoltà e risorse straordinarie per padroneggiare un'abilità che è in alto e in crescita
Che cos'è una rete neurale artificiale?
L'ANN è un modello di Deep Learning ispirato alla struttura neurale del cervello umano. Le RNA sono state create per replicare le attività del cervello umano, che impara dalle proprie esperienze e si adatta all'ambiente circostante. L'ANN contiene una rete di neuroni collegati tra loro da assoni, in modo simile a come la mente umana ha una struttura a più livelli con miliardi di neuroni disposti in una gerarchia. I segnali elettrici (chiamati sinapsi) vengono inviati da uno strato all'altro da questi neuroni collegati. L'ANN può imparare dall'esperienza senza la necessità del coinvolgimento umano grazie a questa approssimazione della modellazione cerebrale.
Quali sono le funzioni di attivazione nelle reti neurali?
Le RNA utilizzano funzioni di attivazione (AF) nei livelli nascosti per condurre calcoli complessi e quindi trasferire i risultati al livello di output. L'obiettivo fondamentale degli AF è quello di conferire alla rete neurale qualità non lineari. Trasformano i segnali di ingresso lineari di un nodo in segnali di uscita non lineari per aiutare le reti profonde ad apprendere polinomi di ordine elevato con più di un grado. Gli AF sono distinti in quanto sono differenziabili, il che aiuta il loro ruolo durante la backpropagation della rete neurale.
Qual è la necessità della non linearità?
Se non vengono utilizzate funzioni di attivazione, il segnale di uscita è una trasformazione lineare, che è un polinomio di un grado. Sebbene le equazioni lineari siano semplici da risolvere, hanno un basso quoziente di complessità, che limita la loro capacità di apprendere mappature complicate dai dati. Una rete neurale senza AF sarà un modello lineare generalizzato con capacità limitate. Questo non è il tipo di prestazioni che desideriamo da una rete neurale. Le reti neurali vengono utilizzate per eseguire calcoli estremamente complessi. Inoltre, le reti neurali non possono apprendere e rappresentare altri dati complessi senza AF, come foto, voce, filmati, audio e così via.