
Jenis-Jenis Algoritma Pembelajaran Mesin dengan Contoh Kasus Penggunaan
Diterbitkan: 2019-07-23Semua keuntungan inovatif yang Anda nikmati hari ini – mulai dari asisten AI yang cerdas dan Mesin Rekomendasi hingga perangkat IoT yang canggih adalah buah dari Ilmu Data, atau lebih spesifiknya, Pembelajaran Mesin.
Aplikasi Machine Learning telah meresap ke hampir setiap aspek kehidupan kita sehari-hari, tanpa kita sadari. Saat ini algoritma ML telah menjadi bagian integral dari berbagai industri, termasuk bisnis, keuangan, dan perawatan kesehatan. Meskipun Anda mungkin pernah mendengar istilah "algoritme ML" lebih dari yang dapat Anda hitung, tahukah Anda apa itu?
Intinya, algoritme Pembelajaran Mesin adalah program belajar mandiri tingkat lanjut – mereka tidak hanya dapat belajar dari data tetapi juga dapat meningkat dari pengalaman. Di sini "belajar" menunjukkan bahwa seiring waktu, algoritme ini terus mengubah cara mereka memproses data, tanpa secara eksplisit diprogram untuk itu.
Pembelajaran dapat mencakup pemahaman fungsi spesifik yang memetakan input ke output, atau mengungkap dan memahami pola tersembunyi dari data mentah. Cara lain belajar algoritma ML adalah melalui 'pembelajaran berbasis instance' atau pembelajaran berbasis memori, tetapi lebih pada itu di lain waktu.
Hari ini, fokus kami adalah memahami berbagai jenis algoritme Pembelajaran Mesin dan tujuan spesifiknya.
- Pembelajaran Terawasi
Seperti namanya, dalam pendekatan pembelajaran terawasi, algoritme dilatih secara eksplisit melalui pengawasan manusia secara langsung. Jadi, pengembang memilih jenis keluaran informasi untuk dimasukkan ke dalam algoritma dan juga menentukan jenis hasil yang diinginkan. Prosesnya dimulai seperti ini – algoritme menerima data input dan output. Algoritme kemudian mulai membuat aturan yang memetakan input ke output. Proses pelatihan ini berlanjut sampai tingkat kinerja tertinggi tercapai. Jadi, pada akhirnya, pengembang dapat memilih dari model yang paling memprediksi keluaran yang diinginkan. Tujuannya di sini adalah untuk melatih suatu algoritma untuk menetapkan atau memprediksi objek keluaran yang tidak berinteraksi selama proses pelatihan.

Tujuan utama di sini adalah untuk menskalakan cakupan data dan membuat prediksi tentang hasil di masa depan dengan memproses dan menganalisis data sampel berlabel.
Kasus penggunaan yang paling umum dari pembelajaran yang diawasi adalah memprediksi tren masa depan dalam harga, penjualan, dan perdagangan saham. Contoh algoritma yang diawasi termasuk Regresi Linier, Regresi Logistik, Jaringan Syaraf Tiruan, Pohon Keputusan, Hutan Acak, Support Vector Machines (SVM), dan Naive Bayes.
Ada dua jenis teknik pembelajaran terawasi:
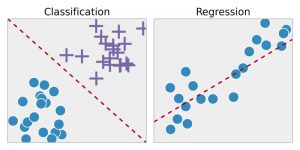
Regresi – Teknik ini pertama-tama mengidentifikasi pola dalam data sampel dan kemudian menghitung atau mereproduksi prediksi hasil yang berkelanjutan. Untuk melakukan itu, ia harus memahami angka, nilainya, korelasi atau pengelompokannya, dan sebagainya. Regresi dapat digunakan untuk prediksi harga produk dan stok.
Klasifikasi – Dalam teknik ini, data input diberi label sesuai dengan sampel data historis dan kemudian dilatih secara manual untuk mengidentifikasi jenis objek tertentu. Begitu ia belajar mengenali objek yang diinginkan, ia kemudian belajar mengkategorikannya dengan tepat. Untuk melakukan ini, ia harus mengetahui bagaimana membedakan antara informasi yang diperoleh dan mengenali karakter optik/gambar/input biner. Klasifikasi digunakan untuk membuat prakiraan cuaca, mengidentifikasi objek dalam sebuah gambar, menentukan apakah sebuah surat adalah spam atau bukan, dll.
Sumber
- Pembelajaran tanpa pengawasan
Tidak seperti pendekatan pembelajaran terawasi yang menggunakan data berlabel untuk membuat prediksi keluaran, pembelajaran tanpa pengawasan memberi umpan dan melatih algoritme secara eksklusif pada data yang tidak berlabel. Pendekatan pembelajaran tanpa pengawasan digunakan untuk mengeksplorasi struktur internal data dan mengekstrak wawasan berharga darinya. Dengan mendeteksi pola tersembunyi dalam data yang tidak berlabel, teknik ini bertujuan untuk mengungkap wawasan semacam itu yang dapat menghasilkan keluaran yang lebih baik. Ini dapat digunakan sebagai langkah awal untuk pembelajaran yang diawasi.
Pembelajaran tanpa pengawasan digunakan oleh bisnis untuk mengekstrak wawasan yang berarti dari data mentah untuk meningkatkan efisiensi operasional dan metrik bisnis lainnya. Ini biasa digunakan di bidang Pemasaran Digital dan Periklanan. Beberapa algoritma unsupervised yang paling populer adalah K-means Clustering, Association Rule, t-SNE (t-Distributed Stochastic Neighbor Embedding), dan PCA (Principal Component Analysis).
Ada dua teknik pembelajaran tanpa pengawasan:
Clustering – Clustering adalah teknik eksplorasi yang digunakan untuk mengkategorikan data ke dalam kelompok atau “cluster” yang bermakna tanpa informasi sebelumnya tentang kredensial cluster (jadi, ini semata-mata didasarkan pada pola internal mereka). Kredensial cluster ditentukan oleh kesamaan objek data individual dan perbedaannya dari objek lainnya. Clustering digunakan untuk mengelompokkan tweet yang menampilkan konten serupa, memisahkan berbagai jenis segmen berita, dll.
Pengurangan Dimensi – Pengurangan Dimensi digunakan untuk menemukan representasi data input yang lebih baik dan mungkin lebih sederhana. Melalui metode ini, data input dibersihkan dari informasi yang berlebihan (atau setidaknya meminimalkan informasi yang tidak perlu) sambil mempertahankan semua bit penting. Dengan cara ini, memungkinkan untuk kompresi data, sehingga mengurangi kebutuhan ruang penyimpanan data. Salah satu kasus penggunaan paling umum dari Dimensionality Reduction adalah pemisahan dan identifikasi email sebagai spam atau email penting.

- Pembelajaran semi-diawasi
Pembelajaran semi-diawasi membatasi antara pembelajaran terawasi dan tidak terawasi. Ini menyandingkan yang terbaik dari kedua dunia untuk membuat satu set algoritma yang unik. Dalam pembelajaran semi-diawasi, sekumpulan data sampel berlabel terbatas digunakan untuk melatih algoritme agar menghasilkan hasil yang diinginkan. Karena hanya menggunakan kumpulan data berlabel yang terbatas, ini membuat model terlatih sebagian yang memberikan label ke kumpulan data yang tidak berlabel. Jadi, hasil akhirnya adalah algoritme unik – penggabungan kumpulan data berlabel dan kumpulan data berlabel semu. Algoritme adalah perpaduan antara atribut deskriptif dan prediktif dari pembelajaran yang diawasi dan tidak diawasi.
Algoritme pembelajaran semi-diawasi banyak digunakan di industri Hukum dan Kesehatan, analisis gambar dan ucapan, dan klasifikasi konten web, untuk beberapa nama. Pembelajaran semi-diawasi telah menjadi semakin populer dalam beberapa tahun terakhir karena jumlah data yang tidak berlabel dan tidak terstruktur yang berkembang pesat dan berbagai macam masalah khusus industri.
- Pembelajaran Penguatan
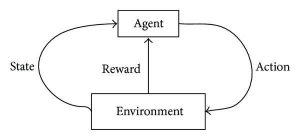
Pembelajaran penguatan berusaha mengembangkan algoritma mandiri dan belajar mandiri yang dapat meningkatkan diri melalui siklus coba-coba yang berkelanjutan berdasarkan kombinasi dan interaksi antara data berlabel dan data yang masuk. Pembelajaran penguatan menggunakan metode eksplorasi dan eksploitasi dimana suatu tindakan terjadi; konsekuensi dari tindakan diamati dan berdasarkan konsekuensi tersebut, tindakan selanjutnya mengikuti – sambil berusaha memperbaiki hasilnya.
Selama proses pelatihan, setelah algoritme dapat melakukan tugas tertentu/yang diinginkan, sinyal hadiah dipicu. Sinyal penghargaan ini bertindak seperti alat navigasi untuk algoritme penguatan, yang menunjukkan pencapaian hasil tertentu dan menentukan tindakan selanjutnya. Secara alami, ada dua sinyal penghargaan:
Positif – Ini memicu ketika urutan tindakan tertentu akan dilanjutkan.
Negatif – Sinyal ini menghukum untuk melakukan aktivitas tertentu dan menuntut koreksi algoritma sebelum bergerak maju.
Sumber
Pembelajaran penguatan paling cocok untuk situasi di mana hanya tersedia informasi yang terbatas atau tidak konsisten. Hal ini paling sering digunakan dalam video game, NPC modern, mobil self-driving, dan bahkan dalam operasi Ad Tech. Contoh algoritma pembelajaran penguatan adalah Q-Learning, Deep Adversarial Networks, Monte-Carlo Tree Search (MCTS), Temporal Difference (TD), dan Asynchronous Actor-Critic Agents (A3C).
Jadi, apa yang kemudian kita simpulkan dari semua ini?
Algoritma Machine Learning digunakan untuk mengungkapkan dan mengidentifikasi pola yang tersembunyi di dalam kumpulan data yang sangat besar. Wawasan ini kemudian digunakan untuk memengaruhi keputusan bisnis secara positif dan menemukan solusi untuk berbagai masalah dunia nyata. Berkat kemajuan dalam Ilmu Data dan Pembelajaran Mesin, kami sekarang memiliki algoritme ML yang dibuat khusus untuk mengatasi masalah dan masalah tertentu. Algoritme ML telah mengubah aplikasi perawatan kesehatan, dan proses, serta cara bisnis dijalankan saat ini.
Apa saja algoritma yang berbeda dalam pembelajaran mesin?
Ada banyak algoritma dalam pembelajaran mesin, tetapi yang paling populer adalah yang berikut ini: Regresi Linier: Dapat digunakan ketika hubungan antar elemen linier. Regresi Logistik: Digunakan ketika hubungan antar elemen tidak linier. Neural Network: Menerapkan satu set neuron yang saling berhubungan dan menyebarkan aktivasinya ke seluruh jaringan untuk menghasilkan output. k-Nearest Neighbors: Menemukan dan mencatat sekumpulan objek menarik yang bertetangga dengan objek yang sedang dipertimbangkan. Support Vector Machines: Mencari hyperplane yang paling baik mengklasifikasikan data pelatihan. Naive Bayes: Menggunakan teorema Bayes untuk menghitung probabilitas bahwa suatu peristiwa tertentu akan terjadi.
Apa saja aplikasi pembelajaran mesin?
Machine Learning adalah subbidang ilmu komputer yang berkembang dari studi pengenalan pola dan teori pembelajaran komputasi dalam kecerdasan buatan. Ini terkait dengan statistik komputasi, yang juga berfokus pada pembuatan prediksi melalui penggunaan komputer. Pembelajaran mesin berfokus pada metode otomatis yang memodifikasi perangkat lunak yang menyelesaikan prediksi sehingga perangkat lunak meningkat tanpa instruksi eksplisit.
Apa perbedaan antara pembelajaran yang diawasi dan tidak diawasi?
Pembelajaran dengan Pengawasan: Anda diberi satu set sampel X dan label Y yang sesuai. Tujuan Anda adalah membangun model pembelajaran yang memetakan dari X ke Y. Pemetaan tersebut diwakili oleh algoritme pembelajaran. Model pembelajaran yang umum digunakan adalah regresi linier. Algoritme adalah algoritme matematis untuk memasang garis ke data. Pembelajaran Tanpa Pengawasan: Anda hanya diberi satu set X sampel yang tidak berlabel. Tujuan Anda adalah menemukan pola atau struktur dalam data tanpa panduan apa pun. Anda dapat menggunakan algoritma pengelompokan untuk ini. Model pembelajaran yang umum digunakan adalah k-means clustering. Algoritma ini dibangun ke dalam algoritma cluster.