
ประเภทของอัลกอริธึมการเรียนรู้ของเครื่องพร้อมตัวอย่างกรณีการใช้งาน
เผยแพร่แล้ว: 2019-07-23ประโยชน์เชิงนวัตกรรมทั้งหมดที่คุณเพลิดเพลินในวันนี้ ตั้งแต่ผู้ช่วย AI อัจฉริยะและเครื่องมือแนะนำไปจนถึงอุปกรณ์ IoT ที่ซับซ้อนเป็นผลพวงของ Data Science หรือโดยเฉพาะอย่างยิ่ง Machine Learning
การใช้งาน Machine Learning ได้แทรกซึมเข้าสู่ชีวิตประจำวันของเราแทบทุกด้าน โดยที่เราไม่รู้ตัวด้วยซ้ำ ทุกวันนี้ อัลกอริธึม ML ได้กลายเป็นส่วนสำคัญของอุตสาหกรรมต่างๆ รวมถึงธุรกิจ การเงิน และการดูแลสุขภาพ แม้ว่าคุณอาจเคยได้ยินเกี่ยวกับคำว่า “ML Algorithm” มากกว่าที่คุณจะนับได้ แต่คุณรู้หรือไม่ว่ามันคืออะไร?
โดยพื้นฐานแล้ว อัลกอริธึมการเรียนรู้ของเครื่องเป็นโปรแกรมการเรียนรู้ด้วยตนเองขั้นสูง ไม่เพียงแต่สามารถเรียนรู้จากข้อมูลเท่านั้น แต่ยังปรับปรุงจากประสบการณ์ได้อีกด้วย ในที่นี้ “การเรียนรู้” หมายความว่าเมื่อเวลาผ่านไป อัลกอริธึมเหล่านี้จะเปลี่ยนแปลงวิธีการประมวลผลข้อมูลอย่างต่อเนื่อง โดยไม่ต้องตั้งโปรแกรมไว้อย่างชัดเจน
การเรียนรู้อาจรวมถึงการทำความเข้าใจฟังก์ชันเฉพาะที่จับคู่อินพุตกับเอาต์พุต หรือการค้นพบและทำความเข้าใจรูปแบบที่ซ่อนอยู่ของข้อมูลดิบ อีกวิธีหนึ่งที่อัลกอริธึม ML เรียนรู้คือผ่าน 'การเรียนรู้ตามอินสแตนซ์' หรือการเรียนรู้โดยใช้หน่วยความจำ แต่เพิ่มเติมในบางครั้ง
วันนี้ เราจะเน้นที่การทำความเข้าใจอัลกอริธึมการเรียนรู้ของเครื่องประเภทต่างๆ และจุดประสงค์เฉพาะ
- การเรียนรู้ภายใต้การดูแล
ตามชื่อที่แนะนำ ในแนวทางการเรียนรู้ภายใต้การดูแล อัลกอริธึมได้รับการฝึกฝนอย่างชัดเจนผ่านการกำกับดูแลของมนุษย์โดยตรง ดังนั้น ผู้พัฒนาจึงเลือกชนิดของข้อมูลที่ส่งออกเพื่อป้อนเข้าสู่อัลกอริทึมและกำหนดประเภทของผลลัพธ์ที่ต้องการด้วย กระบวนการเริ่มต้นในลักษณะนี้ – อัลกอริธึมรับทั้งข้อมูลอินพุตและเอาต์พุต อัลกอริทึมจะเริ่มสร้างกฎการจับคู่อินพุตกับเอาต์พุต กระบวนการฝึกอบรมนี้จะดำเนินต่อไปจนกว่าจะถึงระดับประสิทธิภาพสูงสุด ดังนั้น ในท้ายที่สุด ผู้พัฒนาสามารถเลือกจากรุ่นที่คาดการณ์ผลลัพธ์ที่ต้องการได้ดีที่สุด จุดมุ่งหมายในที่นี้คือการฝึกอัลกอริทึมเพื่อกำหนดหรือคาดการณ์ออบเจ็กต์เอาต์พุตที่อัลกอริธึมไม่ได้โต้ตอบระหว่างกระบวนการฝึกอบรม

เป้าหมายหลักที่นี่คือการปรับขนาดขอบเขตของข้อมูลและเพื่อคาดการณ์เกี่ยวกับผลลัพธ์ในอนาคตโดยการประมวลผลและวิเคราะห์ข้อมูลตัวอย่างที่ติดฉลาก
กรณีการใช้งานทั่วไปของการเรียนรู้ภายใต้การดูแลคือการคาดการณ์แนวโน้มในอนาคตในด้านราคา การขาย และการซื้อขายหุ้น ตัวอย่างของอัลกอริธึมภายใต้การดูแล ได้แก่ การถดถอยเชิงเส้น การถดถอยลอจิสติกส์ โครงข่ายประสาทเทียม ต้นไม้การตัดสินใจ ฟอเรสต์สุ่ม Support Vector Machines (SVM) และอ่าวไร้เดียงสา
เทคนิคการเรียนรู้ภายใต้การดูแลมีสองประเภท:
การถดถอย – เทคนิคนี้จะระบุรูปแบบในข้อมูลตัวอย่างก่อน จากนั้นจึงคำนวณหรือทำซ้ำการคาดการณ์ของผลลัพธ์ที่ต่อเนื่องกัน การจะทำเช่นนั้นได้ ต้องเข้าใจตัวเลข ค่านิยม ความสัมพันธ์หรือการจัดกลุ่ม และอื่นๆ การถดถอยสามารถใช้สำหรับการทำนายความภาคภูมิใจของผลิตภัณฑ์และหุ้น
การจัดประเภท – ในเทคนิคนี้ ข้อมูลที่ป้อนเข้าจะถูกติดป้ายตามตัวอย่างข้อมูลในอดีต และจากนั้นจะฝึกด้วยตนเองเพื่อระบุประเภทของวัตถุเฉพาะ เมื่อเรียนรู้ที่จะรู้จักวัตถุที่ต้องการแล้ว ก็จะเรียนรู้ที่จะจัดหมวดหมู่ให้เหมาะสม ในการทำเช่นนี้ จะต้องรู้วิธีแยกความแตกต่างระหว่างข้อมูลที่ได้รับและจดจำอักขระออปติคัล/รูปภาพ/อินพุตไบนารี การจัดประเภทใช้เพื่อพยากรณ์อากาศ ระบุวัตถุในรูปภาพ ตรวจสอบว่าอีเมลเป็นสแปมหรือไม่ ฯลฯ
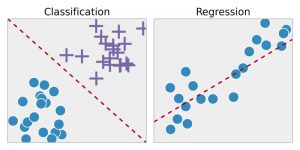
แหล่งที่มา
- การเรียนรู้แบบไม่มีผู้ดูแล
ต่างจากแนวทางการเรียนรู้ภายใต้การดูแลที่ใช้ข้อมูลที่ติดป้ายกำกับเพื่อคาดการณ์ผลลัพธ์ ฟีดการเรียนรู้ที่ไม่มีผู้ดูแลและฝึกอัลกอริทึมเฉพาะกับข้อมูลที่ไม่มีป้ายกำกับ วิธีการเรียนรู้แบบไม่มีผู้ดูแลถูกใช้เพื่อสำรวจโครงสร้างภายในของข้อมูลและดึงข้อมูลเชิงลึกอันมีค่าจากมัน โดยการตรวจจับรูปแบบที่ซ่อนอยู่ในข้อมูลที่ไม่มีป้ายกำกับ เทคนิคนี้มีจุดมุ่งหมายเพื่อค้นหาข้อมูลเชิงลึกที่สามารถนำไปสู่ผลลัพธ์ที่ดีขึ้น อาจใช้เป็นขั้นตอนเบื้องต้นสำหรับการเรียนรู้ภายใต้การดูแล
ธุรกิจใช้การเรียนรู้แบบไม่มีผู้ดูแลเพื่อดึงข้อมูลเชิงลึกที่มีความหมายจากข้อมูลดิบ เพื่อปรับปรุงประสิทธิภาพการดำเนินงานและตัวชี้วัดทางธุรกิจอื่นๆ มักใช้ในด้านการตลาดดิจิทัลและการโฆษณา อัลกอริธึมที่ไม่ได้รับการดูแลที่ได้รับความนิยมมากที่สุด ได้แก่ K-means Clustering, Association Rule, t-SNE (t-Distributed Stochastic Neighbor Embedding) และ PCA (Principal Component Analysis)
มีสองเทคนิคการเรียนรู้ที่ไม่มีผู้ดูแล:
การทำ คลัสเตอร์ – การทำคลัสเตอร์เป็นเทคนิคการสำรวจที่ใช้ในการจัดหมวดหมู่ข้อมูลเป็นกลุ่มที่มีความหมายหรือ "คลัสเตอร์" โดยไม่มีข้อมูลก่อนหน้าเกี่ยวกับข้อมูลรับรองคลัสเตอร์ (ดังนั้นจึงขึ้นอยู่กับรูปแบบภายในเท่านั้น) ข้อมูลประจำตัวของคลัสเตอร์ถูกกำหนดโดยความคล้ายคลึงกันของออบเจ็กต์ข้อมูลแต่ละรายการและความแตกต่างจากออบเจ็กต์ที่เหลือ การจัดกลุ่มใช้เพื่อจัดกลุ่มทวีตที่มีเนื้อหาคล้ายกัน แยกประเภทข่าวประเภทต่างๆ ฯลฯ
การลดมิติข้อมูล – การลดมิติข้อมูลจะใช้เพื่อค้นหาการแสดงข้อมูลที่ป้อนเข้าที่ดีขึ้นและง่ายขึ้น ด้วยวิธีนี้ ข้อมูลที่ป้อนเข้าจะถูกล้างข้อมูลซ้ำซ้อน (หรืออย่างน้อยก็ลดข้อมูลที่ไม่จำเป็นให้น้อยที่สุด) ในขณะที่ยังคงรักษาบิตที่จำเป็นทั้งหมดไว้ วิธีนี้ช่วยให้สามารถบีบอัดข้อมูลได้ ซึ่งจะช่วยลดความต้องการพื้นที่จัดเก็บข้อมูลของข้อมูล กรณีการใช้งานทั่วไปของการลดมิติข้อมูลคือการแยกและระบุอีเมลว่าเป็นสแปมหรืออีเมลที่สำคัญ

- การเรียนรู้กึ่งควบคุม
เส้นแบ่งเขตการเรียนรู้กึ่งควบคุมดูแลระหว่างการเรียนรู้ภายใต้การดูแลและไม่ได้รับการดูแล มันผสมผสานสิ่งที่ดีที่สุดของทั้งสองโลกเพื่อสร้างชุดอัลกอริธึมที่ไม่เหมือนใคร ในการเรียนรู้กึ่งควบคุม จะมีการใช้ข้อมูลตัวอย่างที่มีป้ายกำกับจำนวนจำกัดเพื่อฝึกอัลกอริทึมเพื่อให้ได้ผลลัพธ์ที่ต้องการ เนื่องจากใช้เฉพาะชุดข้อมูลที่มีป้ายกำกับอย่างจำกัด จึงสร้างแบบจำลองที่ได้รับการฝึกอบรมบางส่วนซึ่งกำหนดป้ายกำกับให้กับชุดข้อมูลที่ไม่มีป้ายกำกับ ดังนั้น ผลลัพธ์สุดท้ายคืออัลกอริธึมที่ไม่ซ้ำใคร – การผสมผสานระหว่างชุดข้อมูลที่มีป้ายกำกับและชุดข้อมูลที่ติดฉลากหลอก อัลกอริธึมนี้เป็นการผสมผสานระหว่างคุณลักษณะเชิงพรรณนาและการคาดการณ์ของการเรียนรู้ภายใต้การดูแลและไม่ได้รับการดูแล
อัลกอริธึมการเรียนรู้กึ่งควบคุมนั้นใช้กันอย่างแพร่หลายในอุตสาหกรรมกฎหมายและการดูแลสุขภาพ การวิเคราะห์ภาพและคำพูด และการจัดประเภทเนื้อหาเว็บ เป็นต้น การเรียนรู้แบบกึ่งควบคุมดูแลได้รับความนิยมมากขึ้นเรื่อยๆ ในช่วงไม่กี่ปีที่ผ่านมา อันเนื่องมาจากปริมาณข้อมูลที่ไม่มีป้ายกำกับและไม่มีโครงสร้างเพิ่มขึ้นอย่างรวดเร็ว และปัญหาเฉพาะด้านอุตสาหกรรมที่หลากหลาย
- การเรียนรู้การเสริมแรง
การเรียนรู้แบบเสริมกำลังพยายามพัฒนาอัลกอริธึมแบบยั่งยืนและเรียนรู้ด้วยตนเอง ซึ่งสามารถปรับปรุงตนเองผ่านวงจรการทดลองและข้อผิดพลาดที่ต่อเนื่องกันโดยพิจารณาจากการผสมผสานและการโต้ตอบระหว่างข้อมูลที่ติดป้ายกำกับและข้อมูลที่เข้ามา การเรียนรู้การเสริมกำลังใช้วิธีการสำรวจและแสวงหาประโยชน์จากการกระทำที่เกิดขึ้น ผลที่ตามมาของการกระทำจะถูกสังเกตและตามผลที่ตามมา การกระทำต่อไปจะตามมา – ทั้งหมดในขณะที่พยายามทำให้ผลลัพธ์ดีขึ้น
ในระหว่างกระบวนการฝึกอบรม เมื่ออัลกอริทึมสามารถทำงานเฉพาะ/ที่ต้องการได้ สัญญาณรางวัลจะถูกกระตุ้น สัญญาณรางวัลเหล่านี้ทำหน้าที่เหมือนเครื่องมือนำทางสำหรับอัลกอริธึมการเสริมแรง ซึ่งแสดงถึงความสำเร็จของผลลัพธ์เฉพาะและกำหนดแนวทางการดำเนินการต่อไป โดยธรรมชาติแล้ว มีสองสัญญาณรางวัล:
แง่บวก – ทริกเกอร์เมื่อลำดับของการกระทำเฉพาะจะดำเนินต่อไป
เชิงลบ – สัญญาณนี้จะลงโทษสำหรับการทำกิจกรรมบางอย่างและต้องการการแก้ไขอัลกอริทึมก่อนที่จะดำเนินการต่อไป
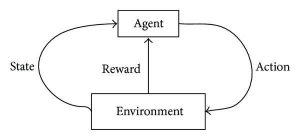
แหล่งที่มา
การเรียนรู้การเสริมกำลังเหมาะที่สุดสำหรับสถานการณ์ที่มีข้อมูลจำกัดหรือไม่สอดคล้องกันเท่านั้น มักใช้ในวิดีโอเกม, NPC สมัยใหม่, รถยนต์ไร้คนขับ และแม้แต่ในปฏิบัติการ Ad Tech ตัวอย่างของอัลกอริทึมการเรียนรู้แบบเสริมกำลัง ได้แก่ Q-Learning, Deep Adversarial Networks, Monte-Carlo Tree Search (MCTS), Temporal Difference (TD) และ Asynchronous Actor-Critic Agents (A3C)
แล้วเราจะสรุปอะไรจากทั้งหมดนี้?
อัลกอริทึมการเรียนรู้ของเครื่องใช้เพื่อเปิดเผยและระบุรูปแบบที่ซ่อนอยู่ภายในชุดข้อมูลขนาดใหญ่ จากนั้น ข้อมูลเชิงลึกเหล่านี้จะนำไปใช้เพื่อสร้างอิทธิพลเชิงบวกต่อการตัดสินใจทางธุรกิจและค้นหาวิธีแก้ไขปัญหาในโลกแห่งความเป็นจริงที่หลากหลาย ด้วยความก้าวหน้าใน Data Science และ Machine Learning ตอนนี้เรามีอัลกอริธึม ML ที่ปรับแต่งมาเพื่อแก้ไขปัญหาและปัญหาเฉพาะ อัลกอริธึม ML ได้เปลี่ยนแปลงแอปพลิเคชันด้านการดูแลสุขภาพ กระบวนการ และแนวทางการดำเนินธุรกิจในปัจจุบัน
อัลกอริทึมต่างๆ ในการเรียนรู้ของเครื่องมีอะไรบ้าง
มีอัลกอริธึมมากมายในการเรียนรู้ของเครื่อง แต่ที่นิยมเป็นพิเศษมีดังต่อไปนี้: การถดถอยเชิงเส้น: สามารถใช้เมื่อความสัมพันธ์ระหว่างองค์ประกอบเป็นแบบเชิงเส้น Logistic Regression: ใช้เมื่อความสัมพันธ์ระหว่างองค์ประกอบไม่เป็นเชิงเส้น โครงข่ายประสาทเทียม: ใช้ชุดของเซลล์ประสาทที่เชื่อมต่อถึงกัน และเผยแพร่การเปิดใช้งานไปทั่วทั้งเครือข่ายเพื่อสร้างเอาต์พุต k-Nearest Neighbors: ค้นหาและบันทึกชุดของวัตถุที่น่าสนใจซึ่งอยู่ติดกับสิ่งที่อยู่ในการพิจารณา รองรับ Vector Machines: ค้นหาไฮเปอร์เพลนที่จำแนกข้อมูลการฝึกได้ดีที่สุด Naive Bayes: ใช้ทฤษฎีบทของ Bayes เพื่อคำนวณความน่าจะเป็นที่เหตุการณ์หนึ่งๆ จะเกิดขึ้น
แอพพลิเคชั่นของการเรียนรู้ของเครื่องคืออะไร?
การเรียนรู้ของเครื่องเป็นสาขาย่อยของวิทยาการคอมพิวเตอร์ที่วิวัฒนาการมาจากการศึกษาการรู้จำรูปแบบและทฤษฎีการเรียนรู้ด้วยคอมพิวเตอร์ในปัญญาประดิษฐ์ มันเกี่ยวข้องกับสถิติการคำนวณซึ่งเน้นการทำนายผ่านการใช้คอมพิวเตอร์ด้วย การเรียนรู้ของเครื่องมุ่งเน้นไปที่วิธีการอัตโนมัติที่ปรับเปลี่ยนซอฟต์แวร์ที่ทำการคาดการณ์ได้สำเร็จ เพื่อให้ซอฟต์แวร์ปรับปรุงโดยไม่มีคำแนะนำที่ชัดเจน
อะไรคือความแตกต่างระหว่างการเรียนรู้แบบมีผู้สอนและแบบไม่มีผู้ดูแล?
การเรียนรู้ภายใต้การดูแล: คุณจะได้รับชุดตัวอย่าง X และป้ายกำกับที่เกี่ยวข้อง Y เป้าหมายของคุณคือการสร้างแบบจำลองการเรียนรู้ที่จับคู่จาก X ถึง Y การทำแผนที่นั้นแสดงโดยอัลกอริทึมการเรียนรู้ โมเดลการเรียนรู้ทั่วไปคือการถดถอยเชิงเส้น อัลกอริทึมคืออัลกอริธึมทางคณิตศาสตร์ของการปรับเส้นให้เข้ากับข้อมูล การเรียนรู้แบบไม่มีผู้ดูแล: คุณจะได้รับชุดตัวอย่าง X ที่ไม่มีป้ายกำกับเท่านั้น เป้าหมายของคุณคือการหารูปแบบหรือโครงสร้างในข้อมูลโดยไม่มีคำแนะนำใดๆ คุณสามารถใช้อัลกอริธึมการจัดกลุ่มสำหรับสิ่งนี้ โมเดลการเรียนรู้ทั่วไปคือการจัดกลุ่ม k-mean อัลกอริทึมถูกสร้างขึ้นในอัลกอริทึมของคลัสเตอร์