
ユースケースの例を使用した機械学習アルゴリズムの種類
公開: 2019-07-23インテリジェントなAIアシスタントやレコメンデーションエンジンから洗練されたIoTデバイスまで、今日楽しんでいるすべての革新的な特典は、データサイエンス、より具体的には機械学習の成果です。
機械学習のアプリケーションは、私たちがこれに気付くことさえなく、私たちの日常生活のほぼすべての側面に浸透しています。 今日、MLアルゴリズムは、ビジネス、金融、ヘルスケアなど、さまざまな業界の不可欠な部分になっています。 「MLアルゴリズム」という用語については、数え切れないほど何度も聞いたことがあるかもしれませんが、それらが何であるかを知っていますか?
本質的に、機械学習アルゴリズムは高度な自己学習プログラムであり、データから学習できるだけでなく、経験からも向上させることができます。 ここで「学習」とは、これらのアルゴリズムがデータを明示的にプログラムすることなく、データの処理方法を時間とともに変化させ続けることを意味します。
学習には、入力を出力にマッピングする特定の機能を理解することや、生データの隠されたパターンを明らかにして理解することが含まれる場合があります。 MLアルゴリズムが学習する別の方法は、「インスタンスベースの学習」またはメモリベースの学習ですが、それについては別の機会に詳しく説明します。
今日は、さまざまな種類の機械学習アルゴリズムとその特定の目的を理解することに焦点を当てます。
- 教師あり学習
名前が示すように、教師あり学習アプローチでは、アルゴリズムは人間の直接の監督を通じて明示的にトレーニングされます。 したがって、開発者は、アルゴリズムにフィードする情報出力の種類を選択し、必要な結果の種類も決定します。 プロセスはこのように始まります–アルゴリズムは入力データと出力データの両方を受け取ります。 次に、アルゴリズムは入力を出力にマッピングするルールの作成を開始します。 このトレーニングプロセスは、最高レベルのパフォーマンスに到達するまで続きます。 したがって、最終的に、開発者は目的の出力を最もよく予測するモデルから選択できます。 ここでの目的は、トレーニングプロセス中に相互作用しなかった出力オブジェクトを割り当てまたは予測するアルゴリズムをトレーニングすることです。

ここでの主な目標は、データの範囲を拡大し、ラベル付けされたサンプルデータを処理および分析することにより、将来の結果について予測を行うことです。
教師あり学習の最も一般的な使用例は、価格、売上、株取引の将来の傾向を予測することです。 教師ありアルゴリズムの例には、線形回帰、ロジスティック回帰、ニューラルネットワーク、ディシジョンツリー、ランダムフォレスト、サポートベクターマシン(SVM)、ナイーブベイズが含まれます。
教師あり学習手法には次の2種類があります。
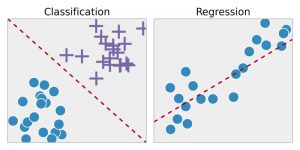
回帰–この手法は、最初にサンプルデータのパターンを識別し、次に連続的な結果の予測を計算または再現します。 そのためには、数値、値、相関関係またはグループ化などを理解する必要があります。 回帰は、製品と在庫のプライド予測に使用できます。
分類–この手法では、入力データは履歴データサンプルに従ってラベル付けされ、特定のタイプのオブジェクトを識別するように手動でトレーニングされます。 目的のオブジェクトを認識することを学習すると、次にそれらを適切に分類することを学習します。 これを行うには、取得した情報を区別し、光学文字/画像/バイナリ入力を認識する方法を知っている必要があります。 分類は、天気予報の作成、画像内のオブジェクトの識別、メールがスパムかどうかの判断などに使用されます。
ソース
- 教師なし学習
ラベル付きデータを使用して出力予測を行う教師あり学習アプローチとは異なり、教師なし学習は、ラベルなしデータのみでアルゴリズムをフィードおよびトレーニングします。 教師なし学習アプローチは、データの内部構造を調査し、そこから貴重な洞察を抽出するために使用されます。 この手法は、ラベルのないデータの隠れたパターンを検出することで、より良い出力につながる可能性のある洞察を明らかにすることを目的としています。 教師あり学習の準備段階として使用できます。
教師なし学習は、生データから意味のある洞察を抽出して運用効率やその他のビジネス指標を改善するために企業によって使用されます。 これは、デジタルマーケティングと広告の分野で一般的に使用されています。 最も一般的な教師なしアルゴリズムには、K-meansクラスタリング、相関ルール、t-SNE(t-Distributed Stochastic Neighbor Embedding)、およびPCA(主成分分析)があります。
教師なし学習手法は2つあります。
クラスタリング–クラスタリングは、クラスターの資格情報に関する事前情報なしで、データを意味のあるグループまたは「クラスター」に分類するために使用される探索手法です(したがって、クラスターの内部パターンのみに基づいています)。 クラスターの資格情報は、個々のデータオブジェクトの類似性と、他のオブジェクトとの違いによって決定されます。 クラスタリングは、類似したコンテンツを特徴とするツイートをグループ化したり、さまざまなタイプのニュースセグメントを分離したりするために使用されます。
次元削減–次元削減は、入力データのより適切で、場合によってはより単純な表現を見つけるために使用されます。 この方法により、入力データから冗長な情報が削除され(または少なくとも不要な情報が最小限に抑えられ)、すべての重要なビットが保持されます。 このようにして、データの圧縮が可能になり、データのストレージスペース要件が軽減されます。 次元削減の最も一般的な使用例の1つは、スパムまたは重要なメールとしてのメールの分離と識別です。

- 半教師あり学習
半教師あり学習は、教師あり学習と教師なし学習の境界です。 両方の長所を並べて、独自のアルゴリズムセットを作成します。 半教師あり学習では、ラベル付けされたサンプルデータの限られたセットを使用して、アルゴリズムをトレーニングし、目的の結果を生成します。 ラベル付きデータの限られたセットのみを使用するため、ラベルなしデータセットにラベルを割り当てる部分的にトレーニングされたモデルを作成します。 したがって、最終的な結果は、ラベル付きデータセットと疑似ラベル付きデータセットの融合という独自のアルゴリズムです。 アルゴリズムは、教師あり学習と教師なし学習の記述的属性と予測的属性の両方を組み合わせたものです。
半教師あり学習アルゴリズムは、いくつか例を挙げると、法務およびヘルスケア業界、画像および音声分析、Webコンテンツ分類で広く使用されています。 半教師あり学習は、ラベルなしおよび構造化されていないデータの量が急速に増加し、業界固有の問題が多種多様であるため、近年ますます人気が高まっています。
- 強化学習
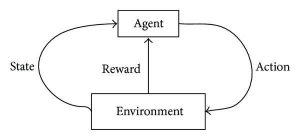
強化学習は、ラベル付けされたデータと受信データの組み合わせと相互作用に基づいて試行錯誤を繰り返すことで自分自身を改善できる、自立した自己学習アルゴリズムの開発を目指しています。 強化学習は、アクションが発生する探索および活用方法を使用します。 アクションの結果が観察され、それらの結果に基づいて、次のアクションが続きます–その間、結果を改善しようとします。
トレーニングプロセス中に、アルゴリズムが特定の/目的のタスクを実行できるようになると、報酬シグナルがトリガーされます。 これらの報酬信号は、強化アルゴリズムのナビゲーションツールのように機能し、特定の結果の達成を示し、次の行動方針を決定します。 当然、2つの報酬シグナルがあります。
ポジティブ–特定の一連のアクションが継続されるときにトリガーされます。
ネガティブ–このシグナルは、特定のアクティビティの実行に対してペナルティを課し、先に進む前にアルゴリズムの修正を要求します。
ソース
強化学習は、限られた情報または一貫性のない情報しか利用できない状況に最適です。 これは、ビデオゲーム、最新のNPC、自動運転車、さらにはAdTechの運用でも最も一般的に使用されています。 強化学習アルゴリズムの例としては、Q学習、深敵対的ネットワーク、モンテカルロ木探索(MCTS)、時間差(TD)、非同期アクタークリティカルエージェント(A3C)があります。
では、これらすべてから何を推測するのでしょうか。
機械学習アルゴリズムは、大量のデータセット内に隠されたパターンを明らかにして識別するために使用されます。 これらの洞察は、ビジネス上の意思決定にプラスの影響を与え、さまざまな現実の問題に対する解決策を見つけるために使用されます。 高度なデータサイエンスと機械学習のおかげで、特定の問題や問題に対処するためにカスタマイズされたMLアルゴリズムが利用できるようになりました。 MLアルゴリズムは、ヘルスケアアプリケーション、プロセス、そして今日のビジネスのやり方を変革しました。
機械学習のさまざまなアルゴリズムは何ですか?
機械学習には多くのアルゴリズムがありますが、特に人気のあるものは次のとおりです。線形回帰:要素間の関係が線形である場合に使用できます。 ロジスティック回帰:要素間の関係が非線形の場合に使用されます。 ニューラルネットワーク:相互接続されたニューロンのセットを実装し、それらのアクティブ化をネットワーク全体に伝播して出力を生成します。 k最近傍法:検討中のオブジェクトに隣接する一連の興味深いオブジェクトを検索して記録します。 サポートベクターマシン:トレーニングデータを最もよく分類する超平面を検索します。 ナイーブベイズ:ベイズの定理を使用して、特定のイベントが発生する確率を計算します。
機械学習の用途は何ですか?
機械学習は、人工知能におけるパターン認識と計算論的学習理論の研究から発展したコンピューターサイエンスのサブフィールドです。 これは計算統計に関連しており、コンピューターを使用した予測作成にも焦点を当てています。 機械学習は、明示的な指示なしにソフトウェアが改善されるように、予測を実行するソフトウェアを変更する自動化された方法に焦点を当てています。
教師あり学習と教師なし学習の違いは何ですか?
教師あり学習:サンプルのセットXと対応するラベルYが与えられます。目標は、XからYにマッピングされる学習モデルを構築することです。そのマッピングは学習アルゴリズムによって表されます。 一般的な学習モデルは線形回帰です。 アルゴリズムは、データに線を当てはめる数学的アルゴリズムです。 教師なし学習:ラベルのないサンプルのセットXのみが与えられます。 あなたの目標は、ガイダンスなしでデータのパターンまたは構造を見つけることです。 これには、クラスタリングアルゴリズムを使用できます。 一般的な学習モデルは、k-meansクラスタリングです。 このアルゴリズムは、クラスターアルゴリズムに組み込まれています。