
Tipuri de algoritmi de învățare automată cu exemple de cazuri de utilizare
Publicat: 2019-07-23Toate avantajele inovatoare de care vă bucurați astăzi – de la asistenți inteligenți AI și motoare de recomandare până la dispozitivele IoT sofisticate sunt roadele științei datelor sau, mai precis, învățării automate.
Aplicațiile Machine Learning au pătruns în aproape fiecare aspect al vieții noastre de zi cu zi, fără ca noi să ne dăm seama de acest lucru. Astăzi, algoritmii ML au devenit o parte integrantă a diferitelor industrii, inclusiv afaceri, finanțe și asistență medicală. Deși este posibil să fi auzit despre termenul „algoritmi ML” de mai multe ori decât poți număra, știi care sunt aceștia?
În esență, algoritmii de învățare automată sunt programe avansate de auto-învățare – nu numai că pot învăța din date, ci se pot îmbunătăți și din experiență. Aici „învățarea” denotă că, cu timpul, acești algoritmi continuă să schimbe modul în care procesează datele, fără a fi programați în mod explicit pentru aceasta.
Învățarea poate include înțelegerea unei anumite funcții care mapează intrarea la ieșire sau descoperirea și înțelegerea tiparelor ascunse ale datelor brute. Un alt mod în care algoritmii ML învață este prin „învățare bazată pe instanțe” sau prin învățarea bazată pe memorie, dar mai multe despre asta altădată.
Astăzi, accentul nostru se va concentra pe înțelegerea diferitelor tipuri de algoritmi de învățare automată și a scopului lor specific.
- Învățare supravegheată
După cum sugerează și numele, în abordarea învățării supravegheate, algoritmii sunt antrenați în mod explicit prin supraveghere umană directă. Deci, dezvoltatorul selectează tipul de informații de ieșire pe care să îl introducă într-un algoritm și, de asemenea, determină tipul de rezultate dorite. Procesul începe oarecum așa – algoritmul primește atât datele de intrare, cât și datele de ieșire. Algoritmul începe apoi să creeze reguli care mapează intrarea la ieșire. Acest proces de antrenament continuă până când se atinge cel mai înalt nivel de performanță. Deci, în cele din urmă, dezvoltatorul poate alege din modelul care prezice cel mai bine rezultatul dorit. Scopul aici este de a antrena un algoritm pentru a atribui sau prezice obiecte de ieșire cu care nu a interacționat în timpul procesului de antrenament.

Scopul principal aici este de a scala domeniul de aplicare a datelor și de a face predicții despre rezultatele viitoare prin procesarea și analizarea datelor eșantionului etichetat.
Cele mai frecvente cazuri de utilizare ale învățării supravegheate sunt prezicerea tendințelor viitoare în ceea ce privește prețul, vânzările și tranzacționarea cu acțiuni. Exemple de algoritmi supravegheați includ regresia liniară, regresia logistică, rețelele neuronale, arborii de decizie, pădurea aleatorie, mașinile vectoriale suport (SVM) și naive Bayes.
Există două tipuri de tehnici de învățare supravegheată:
Regresia – Această tehnică identifică mai întâi modelele din datele eșantionului și apoi calculează sau reproduce predicțiile rezultatelor continue. Pentru a face asta, trebuie să înțeleagă numerele, valorile lor, corelațiile sau grupările lor și așa mai departe. Regresia poate fi folosită pentru predicția mândriei produselor și stocurilor.
Clasificare – În această tehnică, datele de intrare sunt etichetate în conformitate cu eșantioanele de date istorice și apoi sunt instruite manual pentru a identifica anumite tipuri de obiecte. Odată ce învață să recunoască obiectele dorite, apoi învață să le clasifice în mod corespunzător. Pentru a face acest lucru, trebuie să știe să facă diferența între informațiile dobândite și să recunoască caractere optice/imagini/intrari binare. Clasificarea este folosită pentru a face prognoze meteo, pentru a identifica obiectele dintr-o imagine, pentru a determina dacă un e-mail este sau nu spam etc.
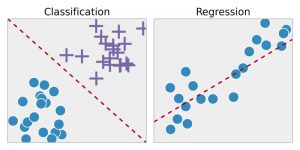
Sursă
- Învățare nesupravegheată
Spre deosebire de abordarea învățării supravegheate care utilizează date etichetate pentru a face predicții de ieșire, învățarea nesupravegheată alimentează și antrenează algoritmi exclusiv pe date neetichetate. Abordarea de învățare nesupravegheată este utilizată pentru a explora structura internă a datelor și pentru a extrage informații valoroase din aceasta. Prin detectarea tiparelor ascunse în datele neetichetate, această tehnică își propune să descopere astfel de perspective care pot duce la rezultate mai bune. Poate fi folosit ca pas preliminar pentru învățarea supravegheată.
Învățarea nesupravegheată este folosită de companii pentru a extrage informații semnificative din datele brute pentru a îmbunătăți eficiența operațională și alte valori de afaceri. Este folosit în mod obișnuit în domeniile marketingului digital și publicității. Unii dintre cei mai populari algoritmi nesupravegheați sunt K-means Clustering, Association Rule, t-SNE (t-Distributed Stochastic Neighbor Embedding) și PCA (Principal Component Analysis).
Există două tehnici de învățare nesupravegheată:
Clustering – Clustering este o tehnică de explorare folosită pentru a clasifica datele în grupuri semnificative sau „clustere” fără nicio informație prealabilă despre acreditările clusterului (deci, se bazează exclusiv pe modelele lor interne). Acreditările clusterului sunt determinate de asemănările obiectelor de date individuale și de diferențele lor față de restul obiectelor. Clusteringul este folosit pentru a grupa tweet-uri cu conținut similar, pentru a separa diferitele tipuri de segmente de știri etc.
Reducerea dimensionalității – Reducerea dimensionalității este utilizată pentru a găsi o reprezentare mai bună și posibil mai simplă a datelor de intrare. Prin această metodă, datele de intrare sunt curățate de informațiile redundante (sau cel puțin minimizează informațiile inutile) păstrând în același timp toți biții esențiali. În acest fel, permite comprimarea datelor, reducând astfel cerințele de spațiu de stocare ale datelor. Unul dintre cele mai frecvente cazuri de utilizare a reducerii dimensionalității este segregarea și identificarea e-mailurilor ca spam sau e-mail important.

- Învățare semi-supravegheată
Învățarea semi-supravegheată este la granița dintre învățarea supravegheată și cea nesupravegheată. Juxtapune tot ce este mai bun din ambele lumi pentru a crea un set unic de algoritmi. În învățarea semi-supravegheată, un set limitat de date eșantion etichetate este utilizat pentru a antrena algoritmii pentru a produce rezultatele dorite. Deoarece folosește doar un set limitat de date etichetate, creează un model parțial antrenat care atribuie etichete setului de date neetichetat. Deci, rezultatul final este un algoritm unic – o amalgamare de seturi de date etichetate și seturi de date pseudoetichetate. Algoritmul este un amestec de atribute descriptive și predictive ale învățării supravegheate și nesupravegheate.
Algoritmii de învățare semi-supravegheați sunt utilizați pe scară largă în industriile juridice și medicale, în analiza imaginilor și a vorbirii și în clasificarea conținutului web, pentru a numi câteva. Învățarea semi-supravegheată a devenit din ce în ce mai populară în ultimii ani, datorită cantității în creștere rapidă de date neetichetate și nestructurate și a varietății mari de probleme specifice industriei.
- Consolidarea învățării
Învățarea prin consolidare urmărește să dezvolte algoritmi autosusținut și de auto-învățare care se pot îmbunătăți printr-un ciclu continuu de încercări și erori bazate pe combinația și interacțiunile dintre datele etichetate și datele primite. Învățarea prin întărire folosește metoda de explorare și exploatare în care are loc o acțiune; se observă consecințele acțiunii și, pe baza acelor consecințe, urmează următoarea acțiune – încercând totodată să îmbunătățească rezultatul.
În timpul procesului de antrenament, odată ce algoritmul poate îndeplini o sarcină specifică/dorită, sunt declanșate semnale de recompensă. Aceste semnale de recompensă acționează ca instrumente de navigare pentru algoritmii de întărire, indicând realizarea anumitor rezultate și determinând următorul curs de acțiune. Desigur, există două semnale de recompensă:
Pozitiv – Se declanșează atunci când o anumită secvență de acțiune urmează să fie continuată.
Negativ – Acest semnal penalizează pentru efectuarea anumitor activități și solicită corectarea algoritmului înainte de a merge mai departe.
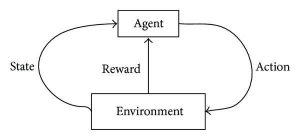
Sursă
Învățarea prin întărire este cea mai potrivită pentru situațiile în care sunt disponibile doar informații limitate sau inconsistente. Este cel mai frecvent utilizat în jocuri video, NPC-uri moderne, mașini cu conducere autonomă și chiar în operațiunile Ad Tech. Exemple de algoritmi de învățare prin întărire sunt Q-Learning, Deep Adversarial Networks, Monte-Carlo Tree Search (MCTS), Temporal Difference (TD) și Asynchronous Actor-Critic Agents (A3C).
Deci, ce deducem atunci din toate acestea?
Algoritmii de învățare automată sunt utilizați pentru a dezvălui și identifica tiparele ascunse în seturi masive de date. Aceste informații sunt apoi folosite pentru a influența pozitiv deciziile de afaceri și pentru a găsi soluții la o gamă largă de probleme din lumea reală. Datorită tehnologiei avansate în știința datelor și învățarea automată, acum avem algoritmi ML adaptați pentru a aborda probleme și probleme specifice. Algoritmii ML au transformat aplicațiile și procesele de asistență medicală, precum și modul în care se desfășoară afacerile în prezent.
Care sunt diferiții algoritmi în învățarea automată?
Există mulți algoritmi în învățarea automată, dar mai ales populari sunt următorii: Regresia liniară: Poate fi utilizat atunci când relația dintre elemente este liniară. Regresia logistică: Se utilizează atunci când relația dintre elemente este neliniară. Rețea neuronală: implementează un set de neuroni interconectați și propagă activarea acestora în întreaga rețea pentru a genera o ieșire. k-Nearest Neighbours: Găsește și înregistrează un set de obiecte interesante care se învecinează cu cel luat în considerare. Suport Vector Machines: caută un hiperplan care clasifică cel mai bine datele de antrenament. Bayes naiv: Folosește teorema lui Bayes pentru a calcula probabilitatea ca un anumit eveniment să se producă.
Care sunt aplicațiile învățării automate?
Învățarea automată este un subdomeniu al informaticii care a evoluat din studiul recunoașterii modelelor și al teoriei învățării computaționale în inteligența artificială. Este legat de statistica computațională, care se concentrează și pe realizarea de predicții prin utilizarea computerelor. Învățarea automată se concentrează pe metode automate care modifică software-ul care realizează predicția, astfel încât software-ul să se îmbunătățească fără instrucțiuni explicite.
Care sunt diferențele dintre învățarea supravegheată și nesupravegheată?
Învățare supravegheată: vi se oferă un set X de eșantioane și etichetele corespunzătoare Y. Scopul dvs. este să construiți un model de învățare care se mapează de la X la Y. Acea mapare este reprezentată de un algoritm de învățare. Un model comun de învățare este regresia liniară. Algoritmul este algoritmul matematic de potrivire a unei linii la date. Învățare nesupravegheată: vi se oferă doar un set X de mostre neetichetate. Scopul tău este să găsești modele sau structuri în date fără nicio îndrumare. Puteți utiliza algoritmi de grupare pentru aceasta. Un model comun de învățare este gruparea k-means. Algoritmul este integrat în algoritmul cluster.