
Tipos de algoritmos de aprendizado de máquina com exemplos de casos de uso
Publicados: 2019-07-23Todas as vantagens inovadoras que você desfruta hoje – desde assistentes inteligentes de IA e mecanismos de recomendação até os sofisticados dispositivos IoT são frutos da ciência de dados, ou mais especificamente, do aprendizado de máquina.
As aplicações do Machine Learning têm permeado quase todos os aspectos de nossas vidas diárias, sem que percebamos isso. Hoje, os algoritmos de ML se tornaram parte integrante de vários setores, incluindo negócios, finanças e saúde. Embora você possa ter ouvido falar sobre o termo “algoritmos de ML” mais vezes do que pode contar, você sabe o que são?
Em essência, os algoritmos de Machine Learning são programas avançados de autoaprendizagem – eles podem não apenas aprender com os dados, mas também melhorar com a experiência. Aqui, “aprendizagem” denota que, com o tempo, esses algoritmos continuam mudando a maneira como processam os dados, sem serem explicitamente programados para isso.
A aprendizagem pode incluir a compreensão de uma função específica que mapeia a entrada para a saída, ou descobrir e compreender os padrões ocultos de dados brutos. Outra maneira pela qual os algoritmos de ML aprendem é por meio de 'aprendizagem baseada em instância' ou aprendizagem baseada em memória, mas falaremos mais sobre isso em outro momento.
Hoje, nosso foco será entender os diferentes tipos de algoritmos de Machine Learning e sua finalidade específica.
- Aprendizado Supervisionado
Como o nome sugere, na abordagem de aprendizado supervisionado, os algoritmos são treinados explicitamente por meio de supervisão humana direta. Assim, o desenvolvedor seleciona o tipo de saída de informação para alimentar um algoritmo e também determina o tipo de resultado desejado. O processo começa mais ou menos assim – o algoritmo recebe os dados de entrada e saída. O algoritmo então começa a criar regras mapeando a entrada para a saída. Este processo de treinamento continua até que o nível mais alto de desempenho seja alcançado. Assim, no final, o desenvolvedor pode escolher entre o modelo que melhor prevê a saída desejada. O objetivo aqui é treinar um algoritmo para atribuir ou prever objetos de saída com os quais ele não interagiu durante o processo de treinamento.

O objetivo principal aqui é dimensionar o escopo dos dados e fazer previsões sobre resultados futuros processando e analisando os dados de amostra rotulados.
Os casos de uso mais comuns de aprendizado supervisionado estão prevendo tendências futuras de preço, vendas e negociação de ações. Exemplos de algoritmos supervisionados incluem Regressão Linear, Regressão Logística, Redes Neurais, Árvores de Decisão, Floresta Aleatória, Máquinas de Vetores de Suporte (SVM) e Naive Bayes.
Existem dois tipos de técnicas de aprendizado supervisionado:
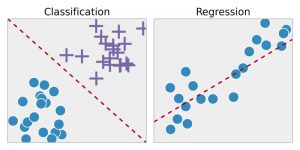
Regressão – Essa técnica primeiro identifica os padrões nos dados da amostra e, em seguida, calcula ou reproduz as previsões de resultados contínuos. Para isso, tem que entender os números, seus valores, suas correlações ou agrupamentos, e assim por diante. A regressão pode ser usada para previsão de orgulho de produtos e estoques.
Classificação – Nesta técnica, os dados de entrada são rotulados de acordo com as amostras de dados históricos e são treinados manualmente para identificar tipos específicos de objetos. Uma vez que aprende a reconhecer os objetos desejados, aprende a categorizá-los adequadamente. Para isso, deve saber diferenciar entre as informações adquiridas e reconhecer caracteres/imagens/entradas binárias ópticas. A classificação é usada para fazer previsões meteorológicas, identificar objetos em uma imagem, determinar se um e-mail é spam ou não, etc.
Fonte
- Aprendizado não supervisionado
Ao contrário da abordagem de aprendizado supervisionado que usa dados rotulados para fazer previsões de saída, o aprendizado não supervisionado alimenta e treina algoritmos exclusivamente em dados não rotulados. A abordagem de aprendizado não supervisionado é usada para explorar a estrutura interna dos dados e extrair insights valiosos deles. Ao detectar os padrões ocultos em dados não rotulados, essa técnica visa descobrir esses insights que podem levar a melhores resultados. Pode ser usado como uma etapa preliminar para o aprendizado supervisionado.
O aprendizado não supervisionado é usado pelas empresas para extrair insights significativos de dados brutos para melhorar a eficiência operacional e outras métricas de negócios. É comumente usado nas áreas de Marketing Digital e Publicidade. Alguns dos algoritmos não supervisionados mais populares são K-means Clustering, Association Rule, t-SNE (t-Distributed Stochastic Neighbor Embedding) e PCA (Principal Component Analysis).
Existem duas técnicas de aprendizado não supervisionado:
Clustering – Clustering é uma técnica de exploração usada para categorizar dados em grupos ou “clusters” significativos sem nenhuma informação prévia sobre as credenciais do cluster (portanto, é baseado apenas em seus padrões internos). As credenciais do cluster são determinadas por semelhanças de objetos de dados individuais e suas diferenças em relação ao restante dos objetos. O clustering é usado para agrupar tweets com conteúdo semelhante, segregar os diferentes tipos de segmentos de notícias, etc.
Redução de Dimensionalidade – A Redução de Dimensionalidade é usada para encontrar uma representação melhor e possivelmente mais simples dos dados de entrada. Através deste método, os dados de entrada são limpos das informações redundantes (ou pelo menos minimizam as informações desnecessárias) enquanto retêm todos os bits essenciais. Dessa forma, permite a compactação de dados, reduzindo assim os requisitos de espaço de armazenamento dos dados. Um caso de uso mais comum de Redução de Dimensionalidade é a segregação e identificação de e-mail como spam ou e-mail importante.

- Aprendizagem semi-supervisionada
A aprendizagem semi-supervisionada faz fronteira entre a aprendizagem supervisionada e não supervisionada. Ele justapõe o melhor dos dois mundos para criar um conjunto único de algoritmos. No aprendizado semi-supervisionado, um conjunto limitado de dados de amostra rotulados é usado para treinar os algoritmos para produzir os resultados desejados. Como ele usa apenas um conjunto limitado de dados rotulados, ele cria um modelo parcialmente treinado que atribui rótulos ao conjunto de dados não rotulado. Assim, o resultado final é um algoritmo único – uma amálgama de conjuntos de dados rotulados e conjuntos de dados pseudo-rotulados. O algoritmo é uma mistura dos atributos descritivos e preditivos do aprendizado supervisionado e não supervisionado.
Os algoritmos de aprendizado semissupervisionado são amplamente utilizados nos setores Jurídico e de Saúde, análise de imagem e fala e classificação de conteúdo da Web, para citar alguns. O aprendizado semi-supervisionado tornou-se cada vez mais popular nos últimos anos devido ao rápido crescimento da quantidade de dados não rotulados e não estruturados e à grande variedade de problemas específicos do setor.
- Aprendizado por Reforço
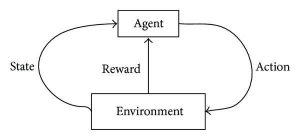
O aprendizado por reforço busca desenvolver algoritmos autossustentáveis e de autoaprendizagem que podem se aprimorar por meio de um ciclo contínuo de tentativas e erros com base na combinação e interações entre os dados rotulados e os dados recebidos. A aprendizagem por reforço usa o método de exploração e explotação em que uma ação ocorre; as consequências da ação são observadas e, com base nessas consequências, a próxima ação segue – o tempo todo tentando melhorar o resultado.
Durante o processo de treinamento, uma vez que o algoritmo pode realizar uma tarefa específica/desejada, os sinais de recompensa são acionados. Esses sinais de recompensa atuam como ferramentas de navegação para os algoritmos de reforço, denotando a realização de determinados resultados e determinando o próximo curso de ação. Naturalmente, existem dois sinais de recompensa:
Positivo – É acionado quando uma sequência específica de ação deve ser continuada.
Negativo – Este sinal penaliza a realização de determinadas atividades e exige a correção do algoritmo antes de avançar.
Fonte
O aprendizado por reforço é mais adequado para situações em que apenas informações limitadas ou inconsistentes estão disponíveis. É mais comumente usado em videogames, NPCs modernos, carros autônomos e até mesmo em operações de Ad Tech. Exemplos de algoritmos de aprendizado por reforço são Q-Learning, Deep Adversarial Networks, Monte-Carlo Tree Search (MCTS), Diferença Temporal (TD) e Agentes Atores Críticos Assíncronos (A3C).
Então, o que podemos inferir de tudo isso?
Os algoritmos de aprendizado de máquina são usados para revelar e identificar os padrões ocultos em grandes conjuntos de dados. Esses insights são usados para influenciar positivamente as decisões de negócios e encontrar soluções para uma ampla gama de problemas do mundo real. Graças ao avanço em Ciência de Dados e Aprendizado de Máquina, agora temos algoritmos de ML feitos sob medida para resolver questões e problemas específicos. Os algoritmos de ML transformaram os aplicativos e processos de saúde e também a maneira como os negócios são conduzidos hoje.
Quais são os diferentes algoritmos no aprendizado de máquina?
Existem muitos algoritmos em aprendizado de máquina, mas especialmente populares são os seguintes: Regressão Linear: Pode ser usado quando a relação entre os elementos é linear. Regressão Logística: Utilizada quando a relação entre os elementos não é linear. Rede Neural: Implementa um conjunto de neurônios interconectados e propaga sua ativação por toda a rede para gerar uma saída. k-Nearest Neighbors: Localiza e registra um conjunto de objetos interessantes que são vizinhos ao que está sendo considerado. Support Vector Machines: Procura um hiperplano que melhor classifica os dados de treinamento. Naive Bayes: Usa o teorema de Bayes para calcular a probabilidade de um determinado evento ocorrer.
Quais são as aplicações do aprendizado de máquina?
Machine Learning é um subcampo da ciência da computação que evoluiu a partir do estudo do reconhecimento de padrões e da teoria do aprendizado computacional em inteligência artificial. Está relacionado à estatística computacional, que também se concentra na realização de previsões através do uso de computadores. O aprendizado de máquina se concentra em métodos automatizados que modificam o software que realiza a previsão para que o software melhore sem instruções explícitas.
Quais são as diferenças entre aprendizado supervisionado e não supervisionado?
Aprendizado Supervisionado: Você recebe um conjunto X de amostras e os rótulos correspondentes Y. Seu objetivo é construir um modelo de aprendizado que mapeie de X para Y. Esse mapeamento é representado por um algoritmo de aprendizado. Um modelo de aprendizagem comum é a regressão linear. O algoritmo é o algoritmo matemático de ajustar uma linha aos dados. Aprendizado não supervisionado: você recebe apenas um conjunto X de amostras não rotuladas. Seu objetivo é encontrar padrões ou estrutura nos dados sem qualquer orientação. Você pode usar algoritmos de cluster para isso. Um modelo de aprendizado comum é o agrupamento k-means. O algoritmo é embutido no algoritmo de cluster.