
Типы алгоритмов машинного обучения с примерами использования
Опубликовано: 2019-07-23Все инновационные преимущества, которыми вы наслаждаетесь сегодня — от интеллектуальных помощников ИИ и механизмов рекомендаций до сложных устройств IoT — являются плодами науки о данных или, точнее, машинного обучения.
Приложения машинного обучения проникли почти во все аспекты нашей повседневной жизни, а мы даже не осознаем этого. Сегодня алгоритмы машинного обучения стали неотъемлемой частью различных отраслей, включая бизнес, финансы и здравоохранение. Хотя вы, возможно, слышали о термине «алгоритмы машинного обучения» больше раз, чем можете сосчитать, знаете ли вы, что они собой представляют?
По сути, алгоритмы машинного обучения — это продвинутые самообучающиеся программы — они могут не только учиться на данных, но и совершенствоваться на основе опыта. Здесь «обучение» означает, что со временем эти алгоритмы продолжают изменять способы обработки данных, не будучи явно запрограммированы для этого.
Обучение может включать в себя понимание конкретной функции, которая отображает входные данные в выходные данные, или раскрытие и понимание скрытых шаблонов необработанных данных. Другой способ обучения алгоритмов машинного обучения — это «обучение на основе экземпляров» или обучение на основе памяти, но об этом в другой раз.
Сегодня мы сосредоточимся на понимании различных видов алгоритмов машинного обучения и их конкретной цели.
- Контролируемое обучение
Как следует из названия, при обучении с учителем алгоритмы обучаются явно под непосредственным наблюдением человека. Таким образом, разработчик выбирает тип вывода информации для подачи в алгоритм, а также определяет желаемые результаты. Процесс начинается примерно так — алгоритм получает как входные, так и выходные данные. Затем алгоритм начинает создавать правила, сопоставляющие входные данные с выходными. Этот тренировочный процесс продолжается до тех пор, пока не будет достигнут наивысший уровень производительности. Итак, в конце концов, разработчик может выбрать модель, которая лучше всего предсказывает желаемый результат. Целью здесь является обучение алгоритма назначению или прогнозированию выходных объектов, с которыми он не взаимодействовал в процессе обучения.

Основной целью здесь является масштабирование объема данных и прогнозирование будущих результатов путем обработки и анализа помеченных выборочных данных.
Наиболее распространенные варианты использования контролируемого обучения — прогнозирование будущих тенденций цен, продаж и торговли акциями. Примеры контролируемых алгоритмов включают линейную регрессию, логистическую регрессию, нейронные сети, деревья решений, случайный лес, машины опорных векторов (SVM) и наивный байесовский алгоритм.
Существует два вида контролируемых методов обучения:
Регрессия . Этот метод сначала идентифицирует закономерности в выборочных данных, а затем вычисляет или воспроизводит прогнозы непрерывных результатов. Для этого он должен понимать числа, их значения, их корреляции или группировки и так далее. Регрессию можно использовать для прогнозирования гордости продуктов и запасов.
Классификация . В этом методе входные данные маркируются в соответствии с образцами исторических данных, а затем вручную обучаются для определения конкретных типов объектов. Как только он научится распознавать желаемые объекты, он научится соответствующим образом классифицировать их. Для этого он должен знать, как различать полученную информацию и распознавать оптические символы/изображения/двоичные входные данные. Классификация используется для составления прогнозов погоды, идентификации объектов на изображении, определения того, является ли письмо спамом или нет, и т. д.
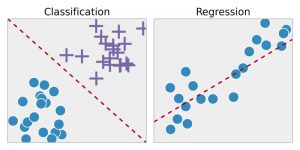
Источник
- Неконтролируемое обучение
В отличие от подхода к обучению с учителем, который использует помеченные данные для прогнозирования выходных данных, обучение без учителя подает и обучает алгоритмы исключительно на неразмеченных данных. Подход к обучению без учителя используется для изучения внутренней структуры данных и извлечения из них ценной информации. Обнаружив скрытые закономерности в немаркированных данных, этот метод направлен на раскрытие таких идей, которые могут привести к лучшим результатам. Его можно использовать в качестве предварительного шага для контролируемого обучения.
Неконтролируемое обучение используется предприятиями для извлечения значимой информации из необработанных данных для повышения операционной эффективности и других бизнес-показателей. Он широко используется в области цифрового маркетинга и рекламы. Некоторые из наиболее популярных неконтролируемых алгоритмов — это кластеризация K-средних, правило ассоциации, t-SNE (t-распределенное стохастическое встраивание соседей) и PCA (анализ основных компонентов).
Существует два метода обучения без учителя:
Кластеризация . Кластеризация — это метод исследования, используемый для классификации данных по значимым группам или «кластерам» без какой-либо предварительной информации об учетных данных кластера (поэтому он основан исключительно на их внутренних шаблонах). Учетные данные кластера определяются сходством отдельных объектов данных и их отличием от остальных объектов. Кластеризация используется для группировки твитов с похожим содержанием, разделения новостных сегментов разных типов и т. д.
Уменьшение размерности. Уменьшение размерности используется для поиска лучшего и, возможно, более простого представления входных данных. С помощью этого метода входные данные очищаются от избыточной информации (или, по крайней мере, минимизируются ненужные данные), сохраняя при этом все важные биты. Таким образом, он позволяет сжимать данные, тем самым уменьшая требования к пространству для хранения данных. Одним из наиболее распространенных случаев использования уменьшения размерности является разделение и идентификация почты как спама или важной почты.

- Полуконтролируемое обучение
Полууправляемое обучение граничит между контролируемым и неконтролируемым обучением. Он сочетает в себе лучшее из обоих миров для создания уникального набора алгоритмов. При обучении с полуучителем ограниченный набор помеченных выборочных данных используется для обучения алгоритмов получению желаемых результатов. Поскольку он использует только ограниченный набор помеченных данных, он создает частично обученную модель, которая присваивает метки неразмеченным наборам данных. Таким образом, конечным результатом является уникальный алгоритм — объединение помеченных наборов данных и наборов псевдопомеченных данных. Алгоритм представляет собой смесь как описательных, так и прогностических атрибутов контролируемого и неконтролируемого обучения.
Алгоритмы обучения с полуучителем широко используются в юриспруденции и здравоохранении, анализе изображений и речи, классификации веб-контента и многих других. Обучение с полуучителем становится все более популярным в последние годы из-за быстро растущего количества неразмеченных и неструктурированных данных и широкого спектра отраслевых проблем.
- Обучение с подкреплением
Обучение с подкреплением направлено на разработку самоподдерживающихся и самообучающихся алгоритмов, которые могут совершенствовать себя посредством непрерывного цикла проб и ошибок на основе комбинации и взаимодействия между помеченными данными и поступающими данными. Обучение с подкреплением использует метод исследования и эксплуатации, в котором происходит действие; последствия действия наблюдаются, и на основе этих последствий следует следующее действие — все время пытаясь улучшить результат.
В процессе обучения, как только алгоритм может выполнить конкретную/желаемую задачу, срабатывают сигналы вознаграждения. Эти сигналы вознаграждения действуют как инструменты навигации для алгоритмов подкрепления, обозначая достижение определенных результатов и определяя следующий курс действий. Естественно, есть два сигнала вознаграждения:
Положительный — срабатывает, когда необходимо продолжить определенную последовательность действий.
Отрицательный — этот сигнал наказывает за выполнение определенных действий и требует исправления алгоритма, прежде чем двигаться дальше.
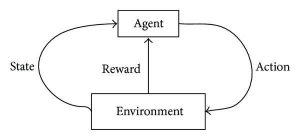
Источник
Обучение с подкреплением лучше всего подходит для ситуаций, когда доступна только ограниченная или противоречивая информация. Чаще всего он используется в видеоиграх, современных NPC, беспилотных автомобилях и даже в рекламных технологиях. Примерами алгоритмов обучения с подкреплением являются Q-Learning, Deep Adversarial Networks, поиск по дереву Монте-Карло (MCTS), временная разница (TD) и асинхронные агенты-критики (A3C).
Итак, что же мы делаем из всего этого?
Алгоритмы машинного обучения используются для выявления и идентификации шаблонов, скрытых в массивных наборах данных. Эти идеи затем используются для положительного влияния на бизнес-решения и поиска решений широкого круга реальных проблем. Благодаря передовым технологиям в области науки о данных и машинного обучения у нас теперь есть алгоритмы машинного обучения, адаптированные для решения конкретных задач и проблем. Алгоритмы машинного обучения изменили приложения и процессы в сфере здравоохранения, а также способ ведения бизнеса сегодня.
Какие существуют алгоритмы машинного обучения?
В машинном обучении существует множество алгоритмов, но особенно популярны следующие: Линейная регрессия: может использоваться, когда отношения между элементами являются линейными. Логистическая регрессия: используется, когда отношения между элементами нелинейны. Нейронная сеть: реализует набор взаимосвязанных нейронов и распространяет их активацию по всей сети для создания выходных данных. k-Ближайшие соседи: находит и записывает набор интересных объектов, которые соседствуют с рассматриваемым объектом. Машины опорных векторов: поиск гиперплоскости, которая лучше всего классифицирует обучающие данные. Наивный Байес: использует теорему Байеса для расчета вероятности того, что данное событие произойдет.
Каковы приложения машинного обучения?
Машинное обучение — это раздел компьютерных наук, возникший на основе изучения теории распознавания образов и вычислительного обучения в области искусственного интеллекта. Это связано с вычислительной статистикой, которая также фокусируется на прогнозировании с помощью компьютеров. Машинное обучение фокусируется на автоматизированных методах, которые модифицируют программное обеспечение, выполняющее прогноз, так что программное обеспечение улучшается без явных инструкций.
В чем разница между контролируемым и неконтролируемым обучением?
Обучение с учителем: вам дан набор X образцов и соответствующие метки Y. Ваша цель — построить модель обучения, которая отображает X в Y. Это отображение представлено алгоритмом обучения. Распространенной моделью обучения является линейная регрессия. Алгоритм представляет собой математический алгоритм подгонки линии к данным. Неконтролируемое обучение: вам предоставляется набор X только немаркированных образцов. Ваша цель — найти закономерности или структуру данных без каких-либо указаний. Для этого можно использовать алгоритмы кластеризации. Распространенной моделью обучения является кластеризация методом k-средних. Алгоритм встроен в кластерный алгоритм.