
Kullanım Örnekleri ile Makine Öğrenimi Algoritmaları Türleri
Yayınlanan: 2019-07-23Akıllı AI yardımcılarından ve Öneri Motorlarından gelişmiş IoT cihazlarına kadar bugün keyfini çıkardığınız tüm yenilikçi avantajlar, Veri Biliminin veya daha özel olarak Makine Öğreniminin meyveleridir.
Makine Öğrenimi uygulamaları, biz farkına bile varmadan, günlük hayatımızın neredeyse her alanına nüfuz etmiştir. Günümüzde ML algoritmaları, işletme, finans ve sağlık dahil olmak üzere çeşitli endüstrilerin ayrılmaz bir parçası haline geldi. “ML algoritmaları” terimini sayabileceğinizden daha fazla duymuş olsanız da, bunların ne olduğunu biliyor musunuz?
Özünde, Makine Öğrenimi algoritmaları gelişmiş kendi kendine öğrenme programlarıdır - yalnızca verilerden öğrenemezler, aynı zamanda deneyimlerden de gelişebilirler. Burada “öğrenme”, zamanla, bu algoritmaların, açıkça programlanmadan verileri işleme yöntemlerini değiştirmeye devam ettiğini ifade eder.
Öğrenme, girdiyi çıktıyla eşleştiren belirli bir işlevi anlamayı veya ham verilerin gizli kalıplarını ortaya çıkarmayı ve anlamayı içerebilir. ML algoritmalarının öğrenmesinin başka bir yolu da 'örnek tabanlı öğrenme' veya bellek tabanlı öğrenmedir, ancak daha fazlası başka bir zaman.
Bugün, farklı türde Makine Öğrenimi algoritmalarını ve bunların özel amaçlarını anlamaya odaklanacağız.
- Denetimli Öğrenme
Adından da anlaşılacağı gibi, denetimli öğrenme yaklaşımında, algoritmalar doğrudan insan denetimi yoluyla açık bir şekilde eğitilir. Böylece geliştirici, bir algoritmaya beslenecek bilgi çıktısının türünü seçer ve ayrıca istenen sonuçların türünü de belirler. İşlem biraz böyle başlar – algoritma hem giriş hem de çıkış verilerini alır. Algoritma daha sonra girdiyi çıktıya eşleyen kurallar oluşturmaya başlar. Bu eğitim süreci, en yüksek performans düzeyine ulaşılana kadar devam eder. Sonuç olarak, geliştirici, istenen çıktıyı en iyi tahmin eden modelden seçim yapabilir. Buradaki amaç, eğitim sürecinde etkileşime girmediği çıktı nesnelerini atamak veya tahmin etmek için bir algoritma eğitmektir.

Buradaki birincil amaç, veri kapsamını ölçeklendirmek ve etiketlenmiş örnek verileri işleyip analiz ederek gelecekteki sonuçlar hakkında tahminlerde bulunmaktır.
Denetimli öğrenmenin en yaygın kullanım örnekleri, fiyat, satış ve hisse senedi ticaretinde gelecekteki eğilimleri tahmin etmektir. Denetimli algoritma örnekleri arasında Doğrusal Regresyon, Lojistik Regresyon, Sinir Ağları, Karar Ağaçları, Rastgele Orman, Destek Vektör Makineleri (SVM) ve Naive Bayes bulunur.
İki tür denetimli öğrenme tekniği vardır:
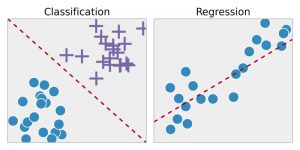
Regresyon – Bu teknik önce örnek verilerdeki kalıpları tanımlar ve ardından sürekli sonuçların tahminlerini hesaplar veya yeniden üretir. Bunu yapmak için sayıları, değerlerini, bağıntılarını veya gruplaşmalarını vb. anlaması gerekir. Ürünlerin ve stokların gurur tahmini için regresyon kullanılabilir.
Sınıflandırma – Bu teknikte, girdi verileri geçmiş veri örneklerine göre etiketlenir ve daha sonra belirli nesne türlerini tanımlamak için manuel olarak eğitilir. İstenen nesneleri tanımayı öğrendiğinde, onları uygun şekilde kategorilere ayırmayı da öğrenir. Bunu yapmak için, elde edilen bilgiler arasında nasıl ayrım yapılacağını ve optik karakterleri/görüntüleri/ikili girişleri nasıl tanıyacağını bilmesi gerekir. Sınıflandırma, hava durumu tahminleri yapmak, bir resimdeki nesneleri tanımlamak, bir postanın spam olup olmadığını belirlemek vb. için kullanılır.
Kaynak
- Denetimsiz Öğrenme
Çıktı tahminleri yapmak için etiketli verileri kullanan denetimli öğrenme yaklaşımının aksine, denetimsiz öğrenme algoritmaları yalnızca etiketlenmemiş veriler üzerinde besler ve eğitir. Denetimsiz öğrenme yaklaşımı, verilerin iç yapısını keşfetmek ve ondan değerli içgörüler çıkarmak için kullanılır. Bu teknik, etiketlenmemiş verilerdeki gizli kalıpları tespit ederek, daha iyi çıktılara yol açabilecek bu tür içgörüleri ortaya çıkarmayı amaçlar. Denetimli öğrenme için bir ön adım olarak kullanılabilir.
Denetimsiz öğrenme, işletmeler tarafından operasyonel verimliliği ve diğer iş ölçütlerini iyileştirmek için ham verilerden anlamlı içgörüler çıkarmak için kullanılır. Dijital Pazarlama ve Reklamcılık alanlarında yaygın olarak kullanılmaktadır. En popüler denetimsiz algoritmalardan bazıları K-ortalama Kümeleme, Birliktelik Kuralı, t-SNE (t-Dağıtılmış Stokastik Komşu Gömme) ve PCA'dır (Temel Bileşen Analizi).
İki denetimsiz öğrenme tekniği vardır:
Kümeleme – Kümeleme, küme kimlik bilgileri hakkında önceden herhangi bir bilgi olmaksızın verileri anlamlı gruplara veya "kümelere" kategorize etmek için kullanılan bir araştırma tekniğidir (bu nedenle, yalnızca iç kalıplarına dayanır). Küme kimlik bilgileri, tek tek veri nesnelerinin benzerlikleri ve bunların geri kalan nesnelerden farklılıkları tarafından belirlenir. Kümeleme, benzer içeriğe sahip tweet'leri gruplamak, farklı türdeki haber bölümlerini ayırmak vb. için kullanılır.
Boyutsallık Azaltma – Boyutsallık Azaltma, girdi verilerinin daha iyi ve muhtemelen daha basit bir temsilini bulmak için kullanılır. Bu yöntem aracılığıyla, giriş verileri, tüm gerekli bitleri korurken, gereksiz bilgilerden temizlenir (veya en azından gereksiz bilgileri en aza indirir). Bu şekilde veri sıkıştırmaya izin verir, böylece verilerin depolama alanı gereksinimlerini azaltır. Boyut Azaltma'nın en yaygın kullanım durumlarından biri, postaların spam veya önemli posta olarak ayrılması ve tanımlanmasıdır.

- Yarı denetimli Öğrenme
Yarı denetimli öğrenme, denetimli ve denetimsiz öğrenme arasında sınırlar. Eşsiz bir algoritma seti oluşturmak için her iki dünyanın en iyilerini yan yana getirir. Yarı denetimli öğrenmede, istenen sonuçları üretmek için algoritmaları eğitmek için sınırlı bir etiketli örnek veri seti kullanılır. Yalnızca sınırlı sayıda etiketlenmiş veri kullandığından, etiketlenmemiş veri kümesine etiketler atayan kısmen eğitilmiş bir model oluşturur. Bu nedenle, nihai sonuç benzersiz bir algoritmadır - etiketli veri kümelerinin ve sözde etiketli veri kümelerinin bir birleşimi. Algoritma, denetimli ve denetimsiz öğrenmenin hem tanımlayıcı hem de öngörücü özelliklerinin bir karışımıdır.
Yarı denetimli öğrenme algoritmaları, Hukuk ve Sağlık sektörlerinde, görüntü ve konuşma analizinde ve web içeriği sınıflandırmasında yaygın olarak kullanılmaktadır. Hızla artan etiketlenmemiş ve yapılandırılmamış veri miktarı ve sektöre özgü çok çeşitli problemler nedeniyle yarı denetimli öğrenme son yıllarda giderek daha popüler hale geldi.
- Pekiştirmeli Öğrenme
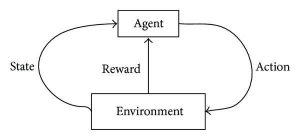
Takviyeli öğrenme, etiketli veriler ile gelen veriler arasındaki kombinasyon ve etkileşimlere dayalı olarak sürekli bir deneme ve hata döngüsü yoluyla kendilerini geliştirebilen kendi kendine devam eden ve kendi kendine öğrenen algoritmalar geliştirmeyi amaçlar. Takviyeli öğrenme, bir eylemin gerçekleştiği keşif ve yararlanma yöntemini kullanır; eylemin sonuçları gözlemlenir ve bu sonuçlara dayalı olarak, bir sonraki eylem takip eder - tüm bu süre boyunca sonucu daha iyi hale getirmeye çalışır.
Eğitim sürecinde, algoritma belirli/istenen bir görevi gerçekleştirebildiğinde ödül sinyalleri tetiklenir. Bu ödül sinyalleri, belirli sonuçların gerçekleştirildiğini ve bir sonraki eylem planını belirleyen, pekiştirme algoritmaları için navigasyon araçları gibi davranır. Doğal olarak, iki ödül sinyali vardır:
Olumlu – Belirli bir eylem dizisine devam edilmesi gerektiğinde tetiklenir.
Negatif – Bu sinyal, belirli aktiviteleri gerçekleştirmeyi cezalandırır ve ilerlemeden önce algoritmanın düzeltilmesini talep eder.
Kaynak
Takviyeli öğrenme, yalnızca sınırlı veya tutarsız bilgilerin mevcut olduğu durumlar için en uygunudur. En yaygın olarak video oyunlarında, modern NPC'lerde, kendi kendini süren arabalarda ve hatta Ad Tech operasyonlarında kullanılır. Takviyeli öğrenme algoritmalarına örnek olarak Q-Learning, Deep Adversarial Networks, Monte-Carlo Tree Search (MCTS), Temporal Difference (TD) ve Asenkron Aktör-Kritik Ajanlar (A3C) verilebilir.
Peki, tüm bunlardan ne sonuç çıkarıyoruz?
Makine Öğrenimi algoritmaları, büyük veri kümeleri içinde saklı kalıpları ortaya çıkarmak ve tanımlamak için kullanılır. Bu bilgiler daha sonra iş kararlarını olumlu yönde etkilemek ve çok çeşitli gerçek dünya sorunlarına çözümler bulmak için kullanılır. Gelişmiş Veri Bilimi ve Makine Öğrenimi sayesinde, artık belirli sorunları ve sorunları ele almak için özel olarak hazırlanmış ML algoritmalarına sahibiz. Makine öğrenimi algoritmaları, sağlık hizmetleri uygulamalarını ve süreçlerini ve ayrıca günümüzde işlerin yürütülme şeklini değiştirmiştir.
Makine öğrenimindeki farklı algoritmalar nelerdir?
Makine öğreniminde birçok algoritma vardır, ancak özellikle aşağıdakiler popülerdir: Doğrusal Regresyon: Öğeler arasındaki ilişki doğrusal olduğunda kullanılabilir. Lojistik Regresyon: Öğeler arasındaki ilişki doğrusal olmadığında kullanılır. Sinir Ağı: Birbiriyle bağlantılı bir dizi nöron uygular ve bir çıktı üretmek için aktivasyonlarını ağ boyunca yayar. k-En Yakın Komşular: Söz konusu nesneye komşu olan bir dizi ilginç nesneyi bulur ve kaydeder. Destek Vektör Makineleri: Eğitim verilerini en iyi sınıflandıran bir hiper düzlem arar. Naive Bayes: Belirli bir olayın meydana gelme olasılığını hesaplamak için Bayes teoremini kullanır.
Makine öğrenimi uygulamaları nelerdir?
Makine Öğrenimi, yapay zekada örüntü tanıma ve hesaplamalı öğrenme teorisi çalışmasından gelişen bilgisayar biliminin bir alt alanıdır. Bilgisayarların kullanımı yoluyla tahminde bulunmaya da odaklanan hesaplamalı istatistiklerle ilgilidir. Makine öğrenimi, yazılımın açık talimatlar olmadan iyileşmesi için tahmini gerçekleştiren yazılımı değiştiren otomatik yöntemlere odaklanır.
Denetimli ve denetimsiz öğrenme arasındaki farklar nelerdir?
Denetimli Öğrenme: Size bir dizi X örnek ve buna karşılık gelen Y etiketleri verilir. Amacınız X'ten Y'ye eşlenen bir öğrenme modeli oluşturmaktır. Bu eşleme bir öğrenme algoritması ile temsil edilir. Yaygın bir öğrenme modeli doğrusal regresyondur. Algoritma, verilere bir çizgi uydurmanın matematiksel algoritmasıdır. Denetimsiz Öğrenme: Size yalnızca etiketlenmemiş örneklerden oluşan bir X kümesi verilir. Amacınız, herhangi bir rehberlik olmadan verilerdeki kalıpları veya yapıyı bulmaktır. Bunun için kümeleme algoritmalarını kullanabilirsiniz. Ortak bir öğrenme modeli, k-araç kümelemedir. Algoritma, küme algoritmasının içine yerleştirilmiştir.