
Tipi di algoritmi di apprendimento automatico con esempi di casi d'uso
Pubblicato: 2019-07-23Tutti i vantaggi innovativi di cui godi oggi, dagli assistenti AI intelligenti e dai motori di raccomandazione ai sofisticati dispositivi IoT, sono i frutti della scienza dei dati o, più specificamente, del Machine Learning.
Le applicazioni del Machine Learning hanno permeato quasi ogni aspetto della nostra vita quotidiana, senza che ce ne accorgessimo. Oggi gli algoritmi ML sono diventati parte integrante di vari settori, tra cui business, finanza e assistenza sanitaria. Anche se potresti aver sentito parlare del termine "algoritmi ML" più volte di quanto tu possa contare, sai quali sono?
In sostanza, gli algoritmi di Machine Learning sono programmi avanzati di autoapprendimento: non solo possono imparare dai dati, ma possono anche migliorare dall'esperienza. Qui "apprendimento" indica che con il tempo, questi algoritmi continuano a cambiare il modo in cui elaborano i dati, senza essere esplicitamente programmati per questo.
L'apprendimento può includere la comprensione di una funzione specifica che associa l'input all'output o la scoperta e la comprensione dei modelli nascosti dei dati grezzi. Un altro modo in cui gli algoritmi ML apprendono è attraverso l'apprendimento basato sull'istanza o l'apprendimento basato sulla memoria, ma ne parleremo un'altra volta.
Oggi, il nostro obiettivo sarà comprendere i diversi tipi di algoritmi di Machine Learning e il loro scopo specifico.
- Apprendimento supervisionato
Come suggerisce il nome, nell'approccio di apprendimento supervisionato, gli algoritmi vengono addestrati in modo esplicito attraverso la supervisione umana diretta. Quindi, lo sviluppatore seleziona il tipo di output di informazioni da inserire in un algoritmo e determina anche il tipo di risultati desiderati. Il processo inizia in questo modo: l'algoritmo riceve sia i dati di input che quelli di output. L'algoritmo inizia quindi a creare regole che associano l'input all'output. Questo processo di formazione continua fino al raggiungimento del massimo livello di prestazioni. Quindi, alla fine, lo sviluppatore può scegliere dal modello che prevede meglio l'output desiderato. Lo scopo qui è addestrare un algoritmo per assegnare o prevedere oggetti di output con cui non ha interagito durante il processo di addestramento.

L'obiettivo principale in questo caso è scalare l'ambito dei dati e fare previsioni sui risultati futuri elaborando e analizzando i dati del campione etichettati.
I casi d'uso più comuni dell'apprendimento supervisionato sono la previsione delle tendenze future di prezzi, vendite e scambi di azioni. Esempi di algoritmi supervisionati includono regressione lineare, regressione logistica, reti neurali, alberi decisionali, foresta casuale, macchine vettoriali di supporto (SVM) e Naive Bayes.
Esistono due tipi di tecniche di apprendimento supervisionato:
Regressione : questa tecnica identifica prima i modelli nei dati del campione e quindi calcola o riproduce le previsioni di risultati continui. Per farlo, deve comprendere i numeri, i loro valori, le loro correlazioni o raggruppamenti e così via. La regressione può essere utilizzata per la previsione dell'orgoglio di prodotti e scorte.
Classificazione : in questa tecnica, i dati di input vengono etichettati in base ai campioni di dati storici e vengono quindi addestrati manualmente per identificare particolari tipi di oggetti. Una volta che impara a riconoscere gli oggetti desiderati, impara a classificarli in modo appropriato. Per fare ciò, deve saper distinguere tra le informazioni acquisite e riconoscere caratteri ottici/immagini/input binari. La classificazione viene utilizzata per fare previsioni meteorologiche, identificare oggetti in un'immagine, determinare se un'e-mail è spam o meno, ecc.
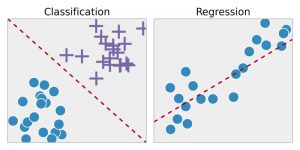
Fonte
- Apprendimento senza supervisione
A differenza dell'approccio di apprendimento supervisionato che utilizza dati etichettati per fare previsioni di output, feed di apprendimento non supervisionato e addestra algoritmi esclusivamente su dati non etichettati. L'approccio dell'apprendimento non supervisionato viene utilizzato per esplorare la struttura interna dei dati ed estrarne preziose informazioni. Rilevando i modelli nascosti nei dati senza etichetta, questa tecnica mira a scoprire tali intuizioni che possono portare a risultati migliori. Può essere utilizzato come fase preliminare per l'apprendimento supervisionato.
L'apprendimento non supervisionato viene utilizzato dalle aziende per estrarre informazioni significative dai dati grezzi per migliorare l'efficienza operativa e altre metriche aziendali. È comunemente usato nei campi del marketing digitale e della pubblicità. Alcuni degli algoritmi non supervisionati più popolari sono K-means Clustering, Association Rule, t-SNE (t-Distributed Stochastic Neighbor Embedding) e PCA (Principal Component Analysis).
Esistono due tecniche di apprendimento senza supervisione:
Clustering : il clustering è una tecnica di esplorazione utilizzata per classificare i dati in gruppi o "cluster" significativi senza alcuna informazione preliminare sulle credenziali del cluster (quindi, si basa esclusivamente sui loro modelli interni). Le credenziali del cluster sono determinate dalle somiglianze dei singoli oggetti dati e dalle loro differenze rispetto al resto degli oggetti. Il clustering viene utilizzato per raggruppare tweet con contenuti simili, separare i diversi tipi di segmenti di notizie, ecc.
Riduzione dimensionale – La riduzione dimensionale viene utilizzata per trovare una rappresentazione migliore e possibilmente più semplice dei dati di input. Attraverso questo metodo, i dati di input vengono ripuliti dalle informazioni ridondanti (o almeno minimizzano le informazioni non necessarie) pur conservando tutti i bit essenziali. In questo modo, consente la compressione dei dati, riducendo così i requisiti di spazio di archiviazione dei dati. Uno dei casi d'uso più comuni di Riduzione dimensionale è la segregazione e l'identificazione della posta come spam o posta importante.

- Apprendimento semi-supervisionato
L'apprendimento semi-supervisionato confina tra l'apprendimento supervisionato e non supervisionato. Contrappone il meglio di entrambi i mondi per creare un insieme unico di algoritmi. Nell'apprendimento semi-supervisionato, un insieme limitato di dati campione etichettati viene utilizzato per addestrare gli algoritmi a produrre i risultati desiderati. Poiché utilizza solo un set limitato di dati etichettati, crea un modello parzialmente addestrato che assegna etichette al set di dati senza etichetta. Quindi, il risultato finale è un algoritmo unico: una fusione di set di dati etichettati e set di dati pseudo-etichettati. L'algoritmo è una miscela di attributi descrittivi e predittivi dell'apprendimento supervisionato e non supervisionato.
Gli algoritmi di apprendimento semi-supervisionato sono ampiamente utilizzati nei settori legale e sanitario, nell'analisi delle immagini e del parlato e nella classificazione dei contenuti Web, solo per citarne alcuni. L'apprendimento semi-supervisionato è diventato sempre più popolare negli ultimi anni a causa della quantità in rapida crescita di dati non etichettati e non strutturati e dell'ampia varietà di problemi specifici del settore.
- Insegnamento rafforzativo
L'apprendimento per rinforzo cerca di sviluppare algoritmi autosufficienti e di autoapprendimento che possono migliorarsi attraverso un ciclo continuo di prove ed errori basato sulla combinazione e sulle interazioni tra i dati etichettati e i dati in entrata. L'apprendimento per rinforzo utilizza il metodo di esplorazione e sfruttamento in cui si verifica un'azione; le conseguenze dell'azione vengono osservate e sulla base di tali conseguenze, segue l'azione successiva, cercando nel contempo di migliorare il risultato.
Durante il processo di addestramento, una volta che l'algoritmo può eseguire un'attività specifica/desiderata, vengono attivati i segnali di ricompensa. Questi segnali di ricompensa agiscono come strumenti di navigazione per gli algoritmi di rinforzo, denotando il raggiungimento di risultati particolari e determinando la prossima linea d'azione. Naturalmente, ci sono due segnali di ricompensa:
Positivo – Si attiva quando una specifica sequenza di azioni deve essere continuata.
Negativo – Questo segnale penalizza l'esecuzione di determinate attività e richiede la correzione dell'algoritmo prima di andare avanti.
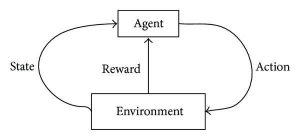
Fonte
L'apprendimento per rinforzo è più adatto per le situazioni in cui sono disponibili solo informazioni limitate o incoerenti. È più comunemente usato nei videogiochi, negli NPC moderni, nelle auto a guida autonoma e persino nelle operazioni di Ad Tech. Esempi di algoritmi di apprendimento per rinforzo sono Q-Learning, Deep Adversarial Networks, Monte-Carlo Tree Search (MCTS), Temporal Difference (TD) e Asynchronous Actor-Critic Agents (A3C).
Allora, cosa deduciamo da tutto questo?
Gli algoritmi di Machine Learning vengono utilizzati per rivelare e identificare i modelli nascosti all'interno di enormi set di dati. Queste informazioni vengono quindi utilizzate per influenzare positivamente le decisioni aziendali e trovare soluzioni a un'ampia gamma di problemi del mondo reale. Grazie all'avanzato in Data Science e Machine Learning, ora abbiamo algoritmi ML fatti su misura per affrontare problemi e problemi specifici. Gli algoritmi ML hanno trasformato le applicazioni e i processi sanitari e anche il modo in cui le aziende vengono condotte oggi.
Quali sono i diversi algoritmi nell'apprendimento automatico?
Esistono molti algoritmi nell'apprendimento automatico, ma particolarmente popolari sono i seguenti: Regressione lineare: può essere utilizzata quando la relazione tra gli elementi è lineare. Regressione logistica: utilizzata quando la relazione tra gli elementi non è lineare. Rete neurale: implementa un insieme di neuroni interconnessi e propaga la loro attivazione in tutta la rete per generare un output. k-Vicini più vicini: trova e registra un insieme di oggetti interessanti vicini a quello in esame. Supporta macchine vettoriali: ricerca un iperpiano che classifichi al meglio i dati di addestramento. Naive Bayes: utilizza il teorema di Bayes per calcolare la probabilità che si verifichi un determinato evento.
Quali sono le applicazioni dell'apprendimento automatico?
L'apprendimento automatico è un sottocampo dell'informatica che si è evoluto dallo studio del riconoscimento dei modelli e della teoria dell'apprendimento computazionale nell'intelligenza artificiale. È correlato alla statistica computazionale, che si concentra anche sulla creazione di previsioni attraverso l'uso dei computer. L'apprendimento automatico si concentra su metodi automatizzati che modificano il software che esegue la previsione in modo che il software migliori senza istruzioni esplicite.
Quali sono le differenze tra apprendimento supervisionato e non supervisionato?
Apprendimento supervisionato: ti viene data una serie X di campioni e le corrispondenti etichette Y. Il tuo obiettivo è costruire un modello di apprendimento che mappa da X a Y. Tale mappatura è rappresentata da un algoritmo di apprendimento. Un modello di apprendimento comune è la regressione lineare. L'algoritmo è l'algoritmo matematico per adattare una linea ai dati. Apprendimento non supervisionato: ti viene data solo una serie X di campioni senza etichetta. Il tuo obiettivo è trovare modelli o strutture nei dati senza alcuna guida. È possibile utilizzare algoritmi di clustering per questo. Un modello di apprendimento comune è il clustering di k-medie. L'algoritmo è integrato nell'algoritmo del cluster.