
Rodzaje algorytmów uczenia maszynowego z przykładami przypadków użycia
Opublikowany: 2019-07-23Wszystkie innowacyjne korzyści, z których korzystasz dzisiaj — od inteligentnych asystentów AI i silników rekomendacji po zaawansowane urządzenia IoT — są owocem nauki o danych, a dokładniej uczenia maszynowego.
Zastosowania uczenia maszynowego przeniknęły do prawie każdego aspektu naszego codziennego życia, nawet nie zdając sobie z tego sprawy. Dzisiaj algorytmy ML stały się integralną częścią różnych branż, w tym biznesu, finansów i opieki zdrowotnej. Chociaż być może słyszałeś o terminie „algorytmy ML” więcej razy, niż możesz zliczyć, czy wiesz, czym one są?
W istocie algorytmy uczenia maszynowego są zaawansowanymi programami samouczącymi się – mogą nie tylko uczyć się na danych, ale mogą też doskonalić się dzięki doświadczeniu. Tutaj „uczenie się” oznacza, że z czasem algorytmy te zmieniają sposób przetwarzania danych, nie będąc do tego wyraźnie zaprogramowanym.
Nauka może obejmować zrozumienie określonej funkcji, która odwzorowuje dane wejściowe na dane wyjściowe lub odkrywanie i rozumienie ukrytych wzorców surowych danych. Innym sposobem uczenia się algorytmów ML jest „uczenie się oparte na instancjach” lub uczenie oparte na pamięci, ale o tym innym razem.
Dzisiaj skupimy się na zrozumieniu różnych rodzajów algorytmów uczenia maszynowego i ich specyficznego celu.
- Nadzorowana nauka
Jak sama nazwa wskazuje, w podejściu nadzorowanego uczenia się algorytmy są szkolone bezpośrednio przez bezpośredni nadzór człowieka. Deweloper wybiera więc rodzaj informacji, które mają zostać wprowadzone do algorytmu, a także określa rodzaj pożądanych wyników. Proces zaczyna się mniej więcej tak – algorytm otrzymuje zarówno dane wejściowe, jak i wyjściowe. Algorytm następnie zaczyna tworzyć reguły mapujące dane wejściowe do danych wyjściowych. Ten proces treningowy trwa aż do osiągnięcia najwyższego poziomu wydajności. Ostatecznie więc programista może wybrać model, który najlepiej przewiduje pożądany wynik. Celem jest tutaj nauczenie algorytmu przypisywania lub przewidywania obiektów wyjściowych, z którymi nie wchodził w interakcję podczas procesu uczenia.

Głównym celem jest tutaj skalowanie zakresu danych i przewidywanie przyszłych wyników poprzez przetwarzanie i analizowanie oznaczonych danych próbki.
Najczęstsze przypadki użycia nadzorowanego uczenia się to przewidywanie przyszłych trendów cen, sprzedaży i obrotu akcjami. Przykłady nadzorowanych algorytmów obejmują regresję liniową, regresję logistyczną, sieci neuronowe, drzewa decyzyjne, losowy las, maszyny wektorów nośnych (SVM) i naiwne Bayes.
Istnieją dwa rodzaje nadzorowanych technik uczenia się:
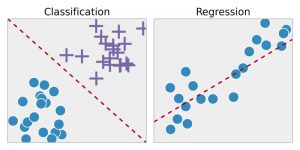
Regresja — ta technika najpierw identyfikuje wzorce w przykładowych danych, a następnie oblicza lub odtwarza przewidywania ciągłych wyników. Aby to zrobić, musi zrozumieć liczby, ich wartości, ich korelacje lub grupowania i tak dalej. Regresji można użyć do przewidywania dumy produktów i zapasów.
Klasyfikacja — w tej technice dane wejściowe są etykietowane zgodnie z próbkami danych historycznych, a następnie są ręcznie szkolone w celu identyfikacji poszczególnych typów obiektów. Kiedy nauczy się rozpoznawać pożądane obiekty, uczy się je odpowiednio kategoryzować. Aby to zrobić, musi wiedzieć, jak rozróżniać pozyskiwane informacje i rozpoznawać znaki optyczne/obrazy/wejścia binarne. Klasyfikacja służy do prognozowania pogody, identyfikowania obiektów na zdjęciu, określania, czy wiadomość jest spamem, czy nie, itp.
Źródło
- Nauka nienadzorowana
W przeciwieństwie do nadzorowanego podejścia do uczenia, które wykorzystuje dane oznaczone etykietami do przewidywania wyników, nienadzorowane kanały uczenia i trenowanie algorytmów wyłącznie na danych nieoznaczonych. Nienadzorowane podejście do uczenia się służy do badania wewnętrznej struktury danych i wydobywania z niej cennych informacji. Dzięki wykrywaniu ukrytych wzorców w nieoznakowanych danych technika ta ma na celu odkrycie takich spostrzeżeń, które mogą prowadzić do lepszych wyników. Może być stosowany jako wstępny krok do nadzorowanego uczenia się.
Nienadzorowane uczenie się jest wykorzystywane przez firmy do wydobywania znaczących spostrzeżeń z nieprzetworzonych danych w celu poprawy wydajności operacyjnej i innych wskaźników biznesowych. Jest powszechnie stosowany w dziedzinie marketingu cyfrowego i reklamy. Niektóre z najpopularniejszych nienadzorowanych algorytmów to klastrowanie K-średnich, reguła asocjacji, t-SNE (t-Distributed Stochastic Neighbor Embedding) i PCA (Principal Component Analysis).
Istnieją dwie techniki uczenia się bez nadzoru:
Klastrowanie — klastrowanie to technika eksploracji używana do kategoryzacji danych w znaczące grupy lub „klastry” bez żadnych wcześniejszych informacji o poświadczeniach klastra (więc opiera się wyłącznie na ich wewnętrznych wzorcach). Poświadczenia klastra są określane przez podobieństwa poszczególnych obiektów danych i ich różnice w stosunku do pozostałych obiektów. Grupowanie służy do grupowania tweetów o podobnej treści, segregowania różnych rodzajów segmentów wiadomości itp.
Redukcja wymiarowości – Redukcja wymiarowości służy do znalezienia lepszej i możliwie prostszej reprezentacji danych wejściowych. Dzięki tej metodzie dane wejściowe są oczyszczane z nadmiarowych informacji (lub przynajmniej minimalizują niepotrzebne informacje), zachowując wszystkie niezbędne bity. W ten sposób umożliwia kompresję danych, zmniejszając w ten sposób wymagania dotyczące miejsca na dane. Jednym z najczęstszych przypadków użycia redukcji wymiarów jest segregacja i identyfikacja poczty jako spamu lub ważnej poczty.

- Nauka częściowo nadzorowana
Uczenie się częściowo nadzorowane graniczy między uczeniem się nadzorowanym i nienadzorowanym. Zestawia to, co najlepsze z obu światów, aby stworzyć unikalny zestaw algorytmów. W uczeniu częściowo nadzorowanym do uczenia algorytmów w celu uzyskania pożądanych wyników wykorzystywany jest ograniczony zestaw oznaczonych danych próbki. Ponieważ używa tylko ograniczonego zestawu danych oznaczonych etykietą, tworzy częściowo przeszkolony model, który przypisuje etykiety do zestawu danych bez etykiet. Tak więc ostatecznym rezultatem jest unikalny algorytm – połączenie zestawów danych oznaczonych i zestawów danych pseudooznaczonych. Algorytm jest połączeniem zarówno opisowych, jak i predykcyjnych atrybutów uczenia nadzorowanego i nienadzorowanego.
Częściowo nadzorowane algorytmy uczenia się są szeroko stosowane w branży prawniczej i opieki zdrowotnej, analizie obrazu i mowy oraz klasyfikacji treści internetowych, żeby wymienić tylko kilka. Uczenie się częściowo nadzorowane stało się w ostatnich latach coraz bardziej popularne ze względu na szybko rosnącą ilość nieoznakowanych i nieustrukturyzowanych danych oraz szeroką gamę problemów branżowych.
- Nauka wzmacniania
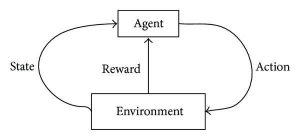
Uczenie ze wzmacnianiem ma na celu opracowanie samopodtrzymujących się i samouczących się algorytmów, które mogą się doskonalić poprzez ciągły cykl prób i błędów w oparciu o kombinację i interakcje między oznaczonymi danymi a danymi przychodzącymi. Uczenie się przez wzmacnianie wykorzystuje metodę eksploracji i eksploatacji, w której zachodzi działanie; obserwuje się konsekwencje działania i na podstawie tych konsekwencji następuje następne działanie – cały czas starając się poprawić wynik.
Podczas procesu uczenia, gdy algorytm może wykonać określone/pożądane zadanie, wyzwalane są sygnały nagrody. Te sygnały nagrody działają jak narzędzia nawigacyjne dla algorytmów wzmacniających, oznaczające osiągnięcie określonych wyników i określające następny kierunek działania. Oczywiście istnieją dwa sygnały nagrody:
Pozytywny – wyzwala się, gdy kontynuacja określonej sekwencji działań ma być kontynuowana.
Negatywny — ten sygnał jest karany za wykonanie pewnych czynności i wymaga korekty algorytmu przed przejściem do przodu.
Źródło
Uczenie się ze wzmocnieniem najlepiej nadaje się do sytuacji, w których dostępne są tylko ograniczone lub niespójne informacje. Jest najczęściej używany w grach wideo, nowoczesnych NPC, autonomicznych samochodach, a nawet w operacjach Ad Tech. Przykładami algorytmów uczenia się przez wzmacnianie są Q-Learning, Deep Adversarial Networks, Monte-Carlo Tree Search (MCTS), Temporal Difference (TD) i Asynchronous Actor-Critic Agent (A3C).
Co zatem wnioskujemy z tego wszystkiego?
Algorytmy uczenia maszynowego służą do ujawniania i identyfikowania wzorców ukrytych w ogromnych zestawach danych. Te spostrzeżenia są następnie wykorzystywane do pozytywnego wpływania na decyzje biznesowe i znajdowania rozwiązań szerokiego zakresu rzeczywistych problemów. Dzięki zaawansowanej analizie danych i uczeniu maszynowemu mamy teraz algorytmy ML dostosowane do rozwiązywania konkretnych problemów i problemów. Algorytmy ML zmieniły aplikacje i procesy opieki zdrowotnej, a także sposób, w jaki prowadzi się dziś biznes.
Jakie są różne algorytmy w uczeniu maszynowym?
Istnieje wiele algorytmów w uczeniu maszynowym, ale szczególnie popularne są następujące: Regresja liniowa: Może być używana, gdy związek między elementami jest liniowy. Regresja logistyczna: Używana, gdy relacja między elementami jest nieliniowa. Sieć neuronowa: implementuje zestaw połączonych ze sobą neuronów i propaguje ich aktywację w całej sieci, aby wygenerować dane wyjściowe. k-Nearest Neighbors: Znajduje i zapisuje zestaw interesujących obiektów sąsiadujących z rozważanym. Support Vector Machines: Wyszukuje hiperpłaszczyznę, która najlepiej klasyfikuje dane treningowe. Naive Bayes: Wykorzystuje twierdzenie Bayesa do obliczenia prawdopodobieństwa wystąpienia danego zdarzenia.
Jakie są zastosowania uczenia maszynowego?
Uczenie maszynowe to poddziedzina informatyki, która wyewoluowała z badania rozpoznawania wzorców i teorii uczenia się obliczeniowego w sztucznej inteligencji. Jest to związane ze statystyką obliczeniową, która również skupia się na przewidywaniu przy użyciu komputerów. Uczenie maszynowe koncentruje się na zautomatyzowanych metodach, które modyfikują oprogramowanie, które realizuje przewidywanie, tak aby oprogramowanie ulepszało się bez wyraźnych instrukcji.
Jakie są różnice między uczeniem się nadzorowanym i nienadzorowanym?
Uczenie nadzorowane: Dostajesz zestaw X próbek i odpowiadające im etykiety Y. Twoim celem jest zbudowanie modelu uczenia, który mapuje od X do Y. To mapowanie jest reprezentowane przez algorytm uczenia się. Powszechnym modelem uczenia się jest regresja liniowa. Algorytm to matematyczny algorytm dopasowywania linii do danych. Nauka nienadzorowana: Dostajesz zestaw X tylko nieoznakowanych próbek. Twoim celem jest znalezienie wzorców lub struktury danych bez żadnych wskazówek. Możesz do tego użyć algorytmów klastrowania. Typowym modelem uczenia się jest grupowanie k-średnich. Algorytm jest wbudowany w algorytm klastrowy.