
帶有用例示例的機器學習算法類型
已發表: 2019-07-23您今天享受的所有創新優勢——從智能 AI 助手和推薦引擎到復雜的物聯網設備,都是數據科學的成果,或者更具體地說,是機器學習的成果。
機器學習的應用幾乎滲透到我們日常生活的方方面面,而我們甚至沒有意識到這一點。 如今,ML 算法已成為各個行業不可或缺的一部分,包括商業、金融和醫療保健。 雖然您可能多次聽說過“機器學習算法”這個術語,但您知道它們是什麼嗎?
本質上,機器學習算法是先進的自學習程序——它們不僅可以從數據中學習,還可以從經驗中改進。 這裡的“學習”表示隨著時間的推移,這些算法會不斷改變它們處理數據的方式,而無需對其進行明確編程。
學習可能包括理解將輸入映射到輸出的特定函數,或者發現和理解原始數據的隱藏模式。 ML 算法學習的另一種方式是通過“基於實例的學習”或基於記憶的學習,但其他時候更多。
今天,我們的重點將是了解不同類型的機器學習算法及其特定目的。
- 監督學習
顧名思義,在監督學習方法中,算法是通過直接的人工監督來明確訓練的。 因此,開發人員選擇輸入算法的信息輸出類型,並確定所需的結果類型。 這個過程有點像這樣開始——算法接收輸入和輸出數據。 然後算法開始創建將輸入映射到輸出的規則。 這個訓練過程一直持續到達到最高水平。 因此,最終,開發人員可以從最能預測所需輸出的模型中進行選擇。 這裡的目的是訓練一種算法來分配或預測在訓練過程中沒有與之交互的輸出對象。

這裡的主要目標是通過處理和分析標記的樣本數據來擴展數據范圍並預測未來的結果。
監督學習最常見的用例是預測價格、銷售和股票交易的未來趨勢。 監督算法的示例包括線性回歸、邏輯回歸、神經網絡、決策樹、隨機森林、支持向量機 (SVM) 和朴素貝葉斯。
有兩種監督學習技術:
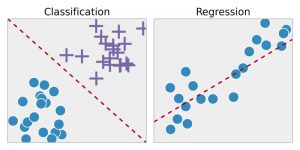
回歸——該技術首先識別樣本數據中的模式,然後計算或再現對連續結果的預測。 為此,它必須了解數字、它們的值、它們的相關性或分組等。 回歸可用於產品和股票的自豪度預測。
分類——在這種技術中,輸入數據根據歷史數據樣本進行標記,然後手動訓練以識別特定類型的對象。 一旦它學會識別所需的對象,它就會學會對它們進行適當的分類。 為此,它必須知道如何區分獲取的信息並識別光學字符/圖像/二進制輸入。 分類用於進行天氣預報、識別圖片中的對象、確定郵件是否為垃圾郵件等。
資源
- 無監督學習
與使用標記數據進行輸出預測的監督學習方法不同,無監督學習僅在未標記數據上提供和訓練算法。 無監督學習方法用於探索數據的內部結構並從中提取有價值的見解。 通過檢測未標記數據中的隱藏模式,該技術旨在發現可以帶來更好輸出的此類見解。 它可以用作監督學習的初步步驟。
企業使用無監督學習從原始數據中提取有意義的見解,以提高運營效率和其他業務指標。 它通常用於數字營銷和廣告領域。 一些最流行的無監督算法是 K 均值聚類、關聯規則、t-SNE(t 分佈隨機鄰域嵌入)和 PCA(主成分分析)。
有兩種無監督學習技術:
聚類——聚類是一種探索技術,用於將數據分類為有意義的組或“集群”,而無需任何關於集群憑據的先驗信息(因此,它僅基於它們的內部模式)。 集群憑證由單個數據對象的相似性及其與其餘對象的差異確定。 聚類用於對具有相似內容的推文進行分組,分離不同類型的新聞片段等。
降維- 降維用於找到輸入數據的更好且可能更簡單的表示。 通過這種方法,在保留所有必要位的同時,清除了輸入數據中的冗餘信息(或至少最小化了不必要的信息)。 這樣,它允許數據壓縮,從而減少數據的存儲空間需求。 一種最常見的降維用例是將郵件隔離和識別為垃圾郵件或重要郵件。
- 半監督學習
半監督學習介於監督學習和無監督學習之間。 它結合了兩全其美的優勢,創造了一套獨特的算法。 在半監督學習中,使用一組有限的標記樣本數據來訓練算法以產生所需的結果。 由於它只使用一組有限的標記數據,它創建了一個部分訓練的模型,將標籤分配給未標記的數據集。 因此,最終結果是一種獨特的算法——標記數據集和偽標記數據集的融合。 該算法融合了監督學習和無監督學習的描述性和預測性屬性。

半監督學習算法廣泛用於法律和醫療保健行業、圖像和語音分析以及網絡內容分類等。 近年來,由於未標記和非結構化數據的數量快速增長以及行業特定問題的種類繁多,半監督學習變得越來越流行。
- 強化學習
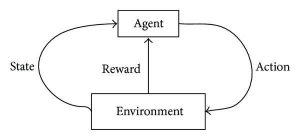
強化學習旨在開發自我維持和自我學習的算法,這些算法可以通過基於標記數據和傳入數據之間的組合和交互的連續試驗和錯誤循環來改進自己。 強化學習使用發生動作的探索和利用方法; 觀察行動的後果,並基於這些後果,下一個行動隨之而來——一直在努力改善結果。
在訓練過程中,一旦算法可以執行特定/期望的任務,就會觸發獎勵信號。 這些獎勵信號就像強化算法的導航工具,表示特定結果的完成並確定下一步行動。 自然地,有兩個獎勵信號:
肯定- 當要繼續執行特定的操作序列時觸發。
Negative – 該信號會懲罰執行某些活動,並要求在繼續之前更正算法。
資源
強化學習最適合只有有限或不一致信息可用的情況。 它最常用於視頻遊戲、現代 NPC、自動駕駛汽車,甚至廣告技術運營中。 強化學習算法的示例包括 Q-Learning、深度對抗網絡、蒙特卡洛樹搜索 (MCTS)、時間差異 (TD) 和異步 Actor-Critic 代理 (A3C)。
那麼,我們從這一切中推斷出什麼?
機器學習算法用於揭示和識別隱藏在海量數據集中的模式。 然後,這些見解將用於積極影響業務決策並為廣泛的現實世界問題找到解決方案。 由於數據科學和機器學習的先進性,我們現在擁有針對特定問題和問題量身定制的 ML 算法。 ML 算法已經改變了醫療保健應用程序、流程以及當今的業務運營方式。
機器學習中有哪些不同的算法?
機器學習中有很多算法,但特別流行的是以下幾種: 線性回歸:可以在元素之間的關係是線性的情況下使用。 邏輯回歸:當元素之間的關係是非線性時使用。 神經網絡:實現一組相互連接的神經元,並在整個網絡中傳播它們的激活以生成輸出。 k-Nearest Neighbors:查找並記錄一組與正在考慮的對象相鄰的有趣對象。 支持向量機:搜索對訓練數據進行最佳分類的超平面。 樸素貝葉斯:使用貝葉斯定理計算給定事件發生的概率。
機器學習有哪些應用?
機器學習是計算機科學的一個子領域,它是從人工智能中的模式識別和計算學習理論的研究發展而來的。 它與計算統計有關,計算統計也側重於通過使用計算機進行預測。 機器學習側重於修改完成預測的軟件的自動化方法,以便在沒有明確指令的情況下改進軟件。
有監督學習和無監督學習有什麼區別?
監督學習:給你一組樣本 X 和相應的標籤 Y。你的目標是建立一個從 X 映射到 Y 的學習模型。該映射由學習算法表示。 一個常見的學習模型是線性回歸。 該算法是將線擬合到數據的數學算法。 無監督學習:只給你一組 X 未標記的樣本。 您的目標是在沒有任何指導的情況下找到數據中的模式或結構。 您可以為此使用聚類算法。 一種常見的學習模型是 k-means 聚類。 該算法內置於集群算法中。