
Types d'algorithmes d'apprentissage automatique avec exemples de cas d'utilisation
Publié: 2019-07-23Tous les avantages innovants dont vous profitez aujourd'hui - des assistants IA intelligents et des moteurs de recommandation aux appareils IoT sophistiqués sont les fruits de la science des données, ou plus précisément de l'apprentissage automatique.
Les applications du Machine Learning se sont infiltrées dans presque tous les aspects de notre vie quotidienne, sans même que nous nous en rendions compte. Aujourd'hui, les algorithmes de ML font désormais partie intégrante de divers secteurs, notamment les affaires, la finance et la santé. Bien que vous ayez peut-être entendu parler du terme "algorithmes ML" plus de fois que vous ne pouvez le compter, savez-vous ce qu'ils sont ?
Essentiellement, les algorithmes d'apprentissage automatique sont des programmes d'auto-apprentissage avancés - ils peuvent non seulement apprendre des données, mais peuvent également s'améliorer grâce à l'expérience. Ici, "l'apprentissage" signifie qu'avec le temps, ces algorithmes ne cessent de changer la façon dont ils traitent les données, sans être explicitement programmés pour cela.
L'apprentissage peut inclure la compréhension d'une fonction spécifique qui mappe l'entrée à la sortie, ou la découverte et la compréhension des modèles cachés des données brutes. Une autre façon dont les algorithmes ML apprennent consiste à utiliser «l'apprentissage basé sur les instances» ou l'apprentissage basé sur la mémoire, mais plus à ce sujet une autre fois.
Aujourd'hui, nous nous concentrerons sur la compréhension des différents types d'algorithmes d'apprentissage automatique et de leur objectif spécifique.
- Enseignement supervisé
Comme son nom l'indique, dans l'approche d'apprentissage supervisé, les algorithmes sont formés explicitement par une supervision humaine directe. Ainsi, le développeur sélectionne le type de sortie d'informations à alimenter dans un algorithme et détermine également le type de résultats souhaités. Le processus commence un peu comme ceci - l'algorithme reçoit à la fois les données d'entrée et de sortie. L'algorithme commence alors à créer des règles mappant l'entrée à la sortie. Ce processus d'entraînement se poursuit jusqu'à ce que le plus haut niveau de performance soit atteint. Ainsi, au final, le développeur peut choisir parmi le modèle qui prédit le mieux la sortie souhaitée. L'objectif ici est de former un algorithme pour affecter ou prédire des objets de sortie avec lesquels il n'a pas interagi pendant le processus de formation.

L'objectif principal ici est de mettre à l'échelle la portée des données et de faire des prédictions sur les résultats futurs en traitant et en analysant les données d'échantillon étiquetées.
Les cas d'utilisation les plus courants de l'apprentissage supervisé consistent à prédire les tendances futures des prix, des ventes et des transactions boursières. Des exemples d'algorithmes supervisés incluent la régression linéaire, la régression logistique, les réseaux de neurones, les arbres de décision, la forêt aléatoire, les machines à vecteurs de support (SVM) et Naive Bayes.
Il existe deux types de techniques d'apprentissage supervisé :
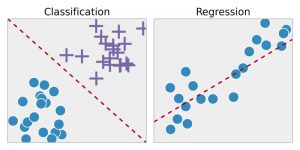
Régression - Cette technique identifie d'abord les modèles dans les données de l'échantillon, puis calcule ou reproduit les prédictions des résultats continus. Pour ce faire, il doit comprendre les nombres, leurs valeurs, leurs corrélations ou regroupements, etc. La régression peut être utilisée pour la prédiction de la fierté des produits et des stocks.
Classification - Dans cette technique, les données d'entrée sont étiquetées conformément aux échantillons de données historiques et sont ensuite formées manuellement pour identifier des types particuliers d'objets. Une fois qu'il apprend à reconnaître les objets désirés, il apprend ensuite à les catégoriser de manière appropriée. Pour cela, il doit savoir différencier les informations acquises et reconnaître les caractères optiques/images/entrées binaires. La classification est utilisée pour faire des prévisions météorologiques, identifier des objets dans une image, déterminer si un courrier est un spam ou non, etc.
La source
- Apprentissage non supervisé
Contrairement à l'approche d'apprentissage supervisé qui utilise des données étiquetées pour faire des prédictions de sortie, l'apprentissage non supervisé alimente et forme des algorithmes exclusivement sur des données non étiquetées. L'approche d'apprentissage non supervisé est utilisée pour explorer la structure interne des données et en extraire des informations précieuses. En détectant les modèles cachés dans les données non étiquetées, cette technique vise à découvrir de telles informations qui peuvent conduire à de meilleurs résultats. Il peut être utilisé comme étape préliminaire pour un apprentissage supervisé.
L'apprentissage non supervisé est utilisé par les entreprises pour extraire des informations significatives à partir de données brutes afin d'améliorer l'efficacité opérationnelle et d'autres mesures commerciales. Il est couramment utilisé dans les domaines du marketing numérique et de la publicité. Certains des algorithmes non supervisés les plus populaires sont K-means Clustering, Association Rule, t-SNE (t-Distributed Stochastic Neighbor Embedding) et PCA (Principal Component Analysis).
Il existe deux techniques d'apprentissage non supervisé :
Clustering – Le clustering est une technique d'exploration utilisée pour catégoriser les données en groupes significatifs ou "clusters" sans aucune information préalable sur les informations d'identification du cluster (elle est donc uniquement basée sur leurs modèles internes). Les informations d'identification du cluster sont déterminées par les similitudes des objets de données individuels et leurs différences par rapport au reste des objets. Le clustering est utilisé pour regrouper les tweets présentant un contenu similaire, séparer les différents types de segments d'actualités, etc.
Réduction de la dimensionnalité - La réduction de la dimensionnalité est utilisée pour trouver une représentation meilleure et éventuellement plus simple des données d'entrée. Grâce à cette méthode, les données d'entrée sont nettoyées des informations redondantes (ou du moins minimisent les informations inutiles) tout en conservant tous les bits essentiels. De cette façon, il permet la compression des données, réduisant ainsi les besoins en espace de stockage des données. L'un des cas d'utilisation les plus courants de la réduction de la dimensionnalité est la ségrégation et l'identification des e-mails en tant que spam ou e-mail important.

- Apprentissage semi-supervisé
L'apprentissage semi-supervisé est à la frontière entre l'apprentissage supervisé et l'apprentissage non supervisé. Il juxtapose le meilleur des deux mondes pour créer un ensemble unique d'algorithmes. Dans l'apprentissage semi-supervisé, un ensemble limité d'échantillons de données étiquetés est utilisé pour former les algorithmes afin de produire les résultats souhaités. Puisqu'il n'utilise qu'un ensemble limité de données étiquetées, il crée un modèle partiellement formé qui attribue des étiquettes à l'ensemble de données non étiqueté. Ainsi, le résultat final est un algorithme unique - une fusion d'ensembles de données étiquetés et d'ensembles de données pseudo-étiquetés. L'algorithme est un mélange des attributs descriptifs et prédictifs de l'apprentissage supervisé et non supervisé.
Les algorithmes d'apprentissage semi-supervisé sont largement utilisés dans les secteurs juridique et de la santé, l'analyse d'images et de la parole et la classification de contenu Web, pour n'en nommer que quelques-uns. L'apprentissage semi-supervisé est devenu de plus en plus populaire ces dernières années en raison de la quantité croissante de données non étiquetées et non structurées et de la grande variété de problèmes spécifiques à l'industrie.
- Apprentissage par renforcement
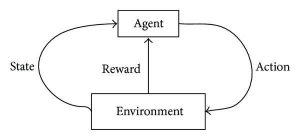
L'apprentissage par renforcement cherche à développer des algorithmes auto-entretenus et auto-apprenants qui peuvent s'améliorer grâce à un cycle continu d'essais et d'erreurs basés sur la combinaison et les interactions entre les données étiquetées et les données entrantes. L'apprentissage par renforcement utilise la méthode d'exploration et d'exploitation dans laquelle une action se produit; les conséquences de l'action sont observées et sur la base de ces conséquences, l'action suivante suit - tout en essayant d'améliorer le résultat.
Pendant le processus de formation, une fois que l'algorithme peut effectuer une tâche spécifique/souhaitée, des signaux de récompense sont déclenchés. Ces signaux de récompense agissent comme des outils de navigation pour les algorithmes de renforcement, indiquant l'accomplissement de résultats particuliers et déterminant le prochain plan d'action. Naturellement, il existe deux signaux de récompense :
Positif - Il se déclenche lorsqu'une séquence d'action spécifique doit être poursuivie.
Négatif - Ce signal pénalise l'exécution de certaines activités et exige la correction de l'algorithme avant d'aller de l'avant.
La source
L'apprentissage par renforcement convient mieux aux situations dans lesquelles seules des informations limitées ou incohérentes sont disponibles. Il est le plus couramment utilisé dans les jeux vidéo, les PNJ modernes, les voitures autonomes et même dans les opérations Ad Tech. Des exemples d'algorithmes d'apprentissage par renforcement sont Q-Learning, Deep Adversarial Networks, Monte-Carlo Tree Search (MCTS), Temporal Difference (TD) et Asynchronous Actor-Critic Agents (A3C).
Alors, que déduisons-nous alors de tout cela ?
Les algorithmes d'apprentissage automatique sont utilisés pour révéler et identifier les modèles cachés dans des ensembles de données massifs. Ces informations sont ensuite utilisées pour influencer positivement les décisions commerciales et trouver des solutions à un large éventail de problèmes réels. Grâce aux avancées de la science des données et de l'apprentissage automatique, nous disposons désormais d'algorithmes ML sur mesure pour résoudre des problèmes et des problèmes spécifiques. Les algorithmes ML ont transformé les applications et les processus de soins de santé, ainsi que la façon dont les entreprises sont menées aujourd'hui.
Quels sont les différents algorithmes en machine learning ?
Il existe de nombreux algorithmes d'apprentissage automatique, mais les suivants sont particulièrement populaires : Régression linéaire : Peut être utilisé lorsque la relation entre les éléments est linéaire. Régression logistique : utilisée lorsque la relation entre les éléments n'est pas linéaire. Réseau de neurones : met en œuvre un ensemble de neurones interconnectés et propage leur activation dans tout le réseau pour générer une sortie. k-Nearest Neighbors : recherche et enregistre un ensemble d'objets intéressants voisins de celui qui est considéré. Support Vector Machines : recherche un hyperplan qui classe au mieux les données d'entraînement. Naive Bayes : utilise le théorème de Bayes pour calculer la probabilité qu'un événement donné se produise.
Quelles sont les applications de l'apprentissage automatique ?
L'apprentissage automatique est un sous-domaine de l'informatique qui a évolué à partir de l'étude de la reconnaissance des formes et de la théorie de l'apprentissage informatique dans l'intelligence artificielle. Il est lié aux statistiques computationnelles, qui se concentrent également sur la réalisation de prévisions grâce à l'utilisation d'ordinateurs. L'apprentissage automatique se concentre sur les méthodes automatisées qui modifient le logiciel qui accomplit la prédiction afin que le logiciel s'améliore sans instructions explicites.
Quelles sont les différences entre l'apprentissage supervisé et non supervisé ?
Apprentissage supervisé : vous recevez un ensemble X d'échantillons et les étiquettes correspondantes Y. Votre objectif est de créer un modèle d'apprentissage qui mappe de X à Y. Ce mappage est représenté par un algorithme d'apprentissage. Un modèle d'apprentissage courant est la régression linéaire. L'algorithme est l'algorithme mathématique d'ajustement d'une ligne aux données. Apprentissage non supervisé : vous recevez un ensemble X d'échantillons non étiquetés uniquement. Votre objectif est de trouver des modèles ou une structure dans les données sans aucune aide. Vous pouvez utiliser des algorithmes de clustering pour cela. Un modèle d'apprentissage courant est le clustering k-means. L'algorithme est intégré à l'algorithme de cluster.