
Tipos de algoritmos de aprendizaje automático con ejemplos de casos de uso
Publicado: 2019-07-23Todas las ventajas innovadoras que disfruta hoy en día, desde los asistentes inteligentes de IA y los motores de recomendación hasta los sofisticados dispositivos IoT, son fruto de la ciencia de datos o, más específicamente, del aprendizaje automático.
Las aplicaciones de Machine Learning han permeado en casi todos los aspectos de nuestra vida diaria, sin que nos demos cuenta. Hoy en día, los algoritmos de ML se han convertido en una parte integral de varias industrias, incluidas las empresas, las finanzas y la atención médica. Si bien es posible que haya oído hablar del término "algoritmos ML" más veces de las que puede contar, ¿sabe qué son?
En esencia, los algoritmos de Machine Learning son programas avanzados de autoaprendizaje: no solo pueden aprender de los datos, sino que también pueden mejorar a partir de la experiencia. Aquí "aprendizaje" denota que con el tiempo, estos algoritmos siguen cambiando la forma en que procesan los datos, sin estar programados explícitamente para ello.
El aprendizaje puede incluir la comprensión de una función específica que asigna la entrada a la salida, o descubrir y comprender los patrones ocultos de los datos sin procesar. Otra forma en que aprenden los algoritmos de ML es a través del "aprendizaje basado en instancias" o el aprendizaje basado en la memoria, pero hablaremos de eso en otro momento.
Hoy, nuestro enfoque será comprender los diferentes tipos de algoritmos de aprendizaje automático y su propósito específico.
- Aprendizaje supervisado
Como sugiere el nombre, en el enfoque de aprendizaje supervisado, los algoritmos se entrenan explícitamente a través de la supervisión humana directa. Entonces, el desarrollador selecciona el tipo de salida de información para alimentar un algoritmo y también determina el tipo de resultados deseados. El proceso comienza algo así: el algoritmo recibe los datos de entrada y salida. Luego, el algoritmo comienza a crear reglas que asignan la entrada a la salida. Este proceso de entrenamiento continúa hasta que se alcanza el nivel más alto de rendimiento. Entonces, al final, el desarrollador puede elegir el modelo que mejor predice el resultado deseado. El objetivo aquí es entrenar un algoritmo para asignar o predecir objetos de salida con los que no ha interactuado durante el proceso de entrenamiento.

El objetivo principal aquí es escalar el alcance de los datos y hacer predicciones sobre resultados futuros al procesar y analizar los datos de muestra etiquetados.
Los casos de uso más comunes del aprendizaje supervisado son la predicción de tendencias futuras en precios, ventas y operaciones bursátiles. Los ejemplos de algoritmos supervisados incluyen la regresión lineal, la regresión logística, las redes neuronales, los árboles de decisión, los bosques aleatorios, las máquinas de vectores de soporte (SVM) y Naive Bayes.
Hay dos tipos de técnicas de aprendizaje supervisado:
Regresión : esta técnica primero identifica los patrones en los datos de muestra y luego calcula o reproduce las predicciones de resultados continuos. Para hacer eso, tiene que entender los números, sus valores, sus correlaciones o agrupaciones, etc. La regresión se puede utilizar para la predicción del orgullo de productos y existencias.
Clasificación : en esta técnica, los datos de entrada se etiquetan de acuerdo con las muestras de datos históricos y luego se entrenan manualmente para identificar tipos particulares de objetos. Una vez que aprende a reconocer los objetos deseados, aprende a categorizarlos apropiadamente. Para ello, tiene que saber diferenciar la información adquirida y reconocer caracteres ópticos/imágenes/entradas binarias. La clasificación se utiliza para hacer previsiones meteorológicas, identificar objetos en una imagen, determinar si un correo es spam o no, etc.
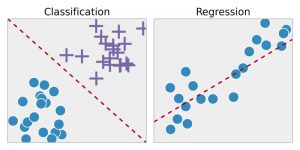
Fuente
- Aprendizaje sin supervisión
A diferencia del enfoque de aprendizaje supervisado que utiliza datos etiquetados para hacer predicciones de salida, el aprendizaje no supervisado alimenta y entrena algoritmos exclusivamente con datos no etiquetados. El enfoque de aprendizaje no supervisado se utiliza para explorar la estructura interna de los datos y extraer información valiosa de ellos. Al detectar los patrones ocultos en los datos sin etiquetar, esta técnica tiene como objetivo descubrir esos conocimientos que pueden conducir a mejores resultados. Puede ser utilizado como un paso preliminar para el aprendizaje supervisado.
Las empresas utilizan el aprendizaje no supervisado para extraer información significativa de los datos sin procesar para mejorar la eficiencia operativa y otras métricas comerciales. Es comúnmente utilizado en los campos de Marketing Digital y Publicidad. Algunos de los algoritmos no supervisados más populares son la agrupación en clústeres de K-means, la regla de asociación, t-SNE (incrustación de vecinos estocásticos distribuidos en t) y PCA (análisis de componentes principales).
Existen dos técnicas de aprendizaje no supervisado:
Agrupamiento: el agrupamiento es una técnica de exploración utilizada para categorizar datos en grupos significativos o "clústeres" sin ninguna información previa sobre las credenciales del clúster (por lo tanto, se basa únicamente en sus patrones internos). Las credenciales del clúster están determinadas por las similitudes de los objetos de datos individuales y sus diferencias con el resto de los objetos. La agrupación se utiliza para agrupar tweets con contenido similar, segregar los diferentes tipos de segmentos de noticias, etc.
Reducción de dimensionalidad : la reducción de dimensionalidad se utiliza para encontrar una representación mejor y posiblemente más simple de los datos de entrada. A través de este método, los datos de entrada se limpian de la información redundante (o al menos minimizan la información innecesaria) mientras se retienen todos los bits esenciales. De esta manera, permite la compresión de datos, reduciendo así los requisitos de espacio de almacenamiento de los datos. Uno de los casos de uso más comunes de la reducción de la dimensionalidad es la segregación y la identificación del correo como spam o correo importante.

- Aprendizaje semisupervisado
El aprendizaje semisupervisado limita entre el aprendizaje supervisado y el no supervisado. Yuxtapone lo mejor de ambos mundos para crear un conjunto único de algoritmos. En el aprendizaje semisupervisado, se utiliza un conjunto limitado de datos de muestra etiquetados para entrenar los algoritmos para producir los resultados deseados. Dado que utiliza solo un conjunto limitado de datos etiquetados, crea un modelo parcialmente entrenado que asigna etiquetas al conjunto de datos sin etiquetar. Entonces, el resultado final es un algoritmo único: una fusión de conjuntos de datos etiquetados y conjuntos de datos pseudo-etiquetados. El algoritmo es una combinación de los atributos descriptivos y predictivos del aprendizaje supervisado y no supervisado.
Los algoritmos de aprendizaje semisupervisados se usan ampliamente en las industrias legal y de salud, análisis de imagen y voz y clasificación de contenido web, por nombrar algunos. El aprendizaje semisupervisado se ha vuelto cada vez más popular en los últimos años debido al rápido crecimiento de la cantidad de datos no estructurados y sin etiquetar y la amplia variedad de problemas específicos de la industria.
- Aprendizaje reforzado
El aprendizaje por refuerzo busca desarrollar algoritmos autosostenidos y de autoaprendizaje que puedan mejorarse a sí mismos a través de un ciclo continuo de ensayos y errores basados en la combinación e interacciones entre los datos etiquetados y los datos entrantes. El aprendizaje por refuerzo utiliza el método de exploración y explotación en el que se produce una acción; se observan las consecuencias de la acción y, en función de esas consecuencias, sigue la siguiente acción, mientras se intenta mejorar el resultado.
Durante el proceso de entrenamiento, una vez que el algoritmo puede realizar una tarea específica o deseada, se activan las señales de recompensa. Estas señales de recompensa actúan como herramientas de navegación para los algoritmos de refuerzo, lo que indica el logro de resultados particulares y determina el siguiente curso de acción. Naturalmente, hay dos señales de recompensa:
Positivo : se activa cuando se debe continuar una secuencia específica de acción.
Negativo : esta señal penaliza por realizar ciertas actividades y exige la corrección del algoritmo antes de seguir adelante.
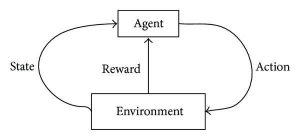
Fuente
El aprendizaje por refuerzo es más adecuado para situaciones en las que solo se dispone de información limitada o inconsistente. Se usa más comúnmente en videojuegos, NPC modernos, automóviles autónomos e incluso en operaciones de tecnología publicitaria. Ejemplos de algoritmos de aprendizaje por refuerzo son Q-Learning, Deep Adversarial Networks, Monte-Carlo Tree Search (MCTS), Temporal Difference (TD) y Asynchronous Actor-Critic Agents (A3C).
Entonces, ¿qué inferimos entonces de todo esto?
Los algoritmos de aprendizaje automático se utilizan para revelar e identificar los patrones ocultos en conjuntos de datos masivos. Estos conocimientos se utilizan luego para influir positivamente en las decisiones comerciales y encontrar soluciones a una amplia gama de problemas del mundo real. Gracias a los avances en ciencia de datos y aprendizaje automático, ahora tenemos algoritmos de ML hechos a medida para abordar cuestiones y problemas específicos. Los algoritmos de ML han transformado las aplicaciones y los procesos de atención médica y también la forma en que se llevan a cabo los negocios en la actualidad.
¿Cuáles son los diferentes algoritmos en el aprendizaje automático?
Hay muchos algoritmos en el aprendizaje automático, pero especialmente populares son los siguientes: Regresión lineal: se puede usar cuando la relación entre elementos es lineal. Regresión Logística: Se utiliza cuando la relación entre elementos no es lineal. Red neuronal: implementa un conjunto de neuronas interconectadas y propaga su activación por toda la red para generar una salida. k-Vecinos más cercanos: encuentra y registra un conjunto de objetos interesantes que son vecinos del que se está considerando. Support Vector Machines: busca un hiperplano que clasifique mejor los datos de entrenamiento. Naive Bayes: utiliza el teorema de Bayes para calcular la probabilidad de que ocurra un evento determinado.
¿Cuáles son las aplicaciones del aprendizaje automático?
El aprendizaje automático es un subcampo de la informática que evolucionó a partir del estudio del reconocimiento de patrones y la teoría del aprendizaje computacional en inteligencia artificial. Está relacionado con la estadística computacional, que también se enfoca en la elaboración de predicciones mediante el uso de computadoras. El aprendizaje automático se centra en métodos automatizados que modifican el software que logra la predicción para que el software mejore sin instrucciones explícitas.
¿Cuáles son las diferencias entre el aprendizaje supervisado y no supervisado?
Aprendizaje supervisado: se le proporciona un conjunto X de muestras y las etiquetas correspondientes Y. Su objetivo es construir un modelo de aprendizaje que mapee de X a Y. Ese mapeo está representado por un algoritmo de aprendizaje. Un modelo de aprendizaje común es la regresión lineal. El algoritmo es el algoritmo matemático de ajustar una línea a los datos. Aprendizaje no supervisado: se le proporciona un conjunto X de muestras sin etiquetar únicamente. Su objetivo es encontrar patrones o estructura en los datos sin ninguna guía. Puede usar algoritmos de agrupamiento para esto. Un modelo de aprendizaje común es el agrupamiento de k-medias. El algoritmo está integrado en el algoritmo de clúster.