
Arten von Algorithmen für maschinelles Lernen mit Beispielen für Anwendungsfälle
Veröffentlicht: 2019-07-23Alle innovativen Vorteile, die Sie heute genießen – von intelligenten KI-Assistenten und Empfehlungsmaschinen bis hin zu den ausgeklügelten IoT-Geräten – sind das Ergebnis von Data Science, oder genauer gesagt, maschinellem Lernen.
Die Anwendungen des maschinellen Lernens haben fast jeden Aspekt unseres täglichen Lebens durchdrungen, ohne dass wir uns dessen überhaupt bewusst sind. Heutzutage sind ML-Algorithmen zu einem festen Bestandteil verschiedener Branchen geworden, darunter Wirtschaft, Finanzen und Gesundheitswesen. Auch wenn Sie den Begriff „ML-Algorithmen“ vielleicht öfter gehört haben, als Sie zählen können, wissen Sie, was sie sind?
Im Wesentlichen sind Algorithmen des maschinellen Lernens fortschrittliche selbstlernende Programme – sie können nicht nur aus Daten lernen, sondern sich auch aus Erfahrung verbessern. „Lernen“ bedeutet hier, dass diese Algorithmen mit der Zeit die Art und Weise, wie sie Daten verarbeiten, immer wieder ändern, ohne explizit dafür programmiert zu sein.
Das Lernen kann das Verstehen einer bestimmten Funktion umfassen, die die Eingabe der Ausgabe zuordnet, oder das Aufdecken und Verstehen der verborgenen Muster von Rohdaten. Eine andere Art, wie ML-Algorithmen lernen, ist „instanzbasiertes Lernen“ oder gedächtnisbasiertes Lernen, aber dazu ein anderes Mal mehr.
Heute werden wir uns darauf konzentrieren, die verschiedenen Arten von Algorithmen für maschinelles Lernen und ihren spezifischen Zweck zu verstehen.
- Überwachtes Lernen
Wie der Name schon sagt, werden beim Supervised-Learning-Ansatz Algorithmen explizit durch direkte menschliche Supervision trainiert. Der Entwickler wählt also die Art der Informationsausgabe aus, die in einen Algorithmus eingespeist werden soll, und bestimmt auch die Art der gewünschten Ergebnisse. Der Prozess beginnt ungefähr so – der Algorithmus erhält sowohl die Eingabe- als auch die Ausgabedaten. Der Algorithmus beginnt dann mit der Erstellung von Regeln, die die Eingabe der Ausgabe zuordnen. Dieser Trainingsprozess wird fortgesetzt, bis das höchste Leistungsniveau erreicht ist. So kann der Entwickler am Ende aus dem Modell auswählen, das die gewünschte Ausgabe am besten vorhersagt. Das Ziel hier ist es, einen Algorithmus zu trainieren, Ausgabeobjekte zuzuweisen oder vorherzusagen, mit denen er während des Trainingsprozesses nicht interagiert hat.

Das primäre Ziel hierbei ist es, den Umfang der Daten zu skalieren und Vorhersagen über zukünftige Ergebnisse zu treffen, indem die gekennzeichneten Beispieldaten verarbeitet und analysiert werden.
Die häufigsten Anwendungsfälle des überwachten Lernens sind die Vorhersage zukünftiger Trends bei Preisen, Verkäufen und Aktienhandel. Beispiele für überwachte Algorithmen sind lineare Regression, logistische Regression, neuronale Netze, Entscheidungsbäume, Random Forest, Support Vector Machines (SVM) und Naive Bayes.
Es gibt zwei Arten von überwachten Lerntechniken:
Regression – Diese Technik identifiziert zuerst die Muster in den Beispieldaten und berechnet oder reproduziert dann die Vorhersagen kontinuierlicher Ergebnisse. Dazu muss es die Zahlen verstehen, ihre Werte, ihre Korrelationen oder Gruppierungen und so weiter. Die Regression kann für die Pride-Vorhersage von Produkten und Aktien verwendet werden.
Klassifizierung – Bei dieser Technik werden die Eingabedaten gemäß den historischen Datenmustern gekennzeichnet und dann manuell trainiert, um bestimmte Arten von Objekten zu identifizieren. Sobald es gelernt hat, gewünschte Objekte zu erkennen, lernt es, sie entsprechend zu kategorisieren. Dazu muss es die erfassten Informationen unterscheiden und optische Zeichen/Bilder/binäre Eingaben erkennen können. Die Klassifizierung wird verwendet, um Wettervorhersagen zu erstellen, Objekte in einem Bild zu identifizieren, festzustellen, ob eine E-Mail Spam ist oder nicht usw.
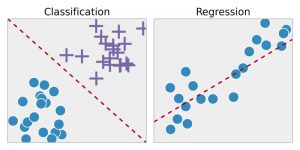
Quelle
- Unbeaufsichtigtes Lernen
Im Gegensatz zum Ansatz des überwachten Lernens, der beschriftete Daten verwendet, um Ausgabevorhersagen zu treffen, werden beim unbeaufsichtigten Lernen Algorithmen ausschließlich mit unbeschrifteten Daten gefüttert und trainiert. Der Ansatz des unüberwachten Lernens wird verwendet, um die interne Struktur von Daten zu erforschen und daraus wertvolle Erkenntnisse zu gewinnen. Durch die Erkennung der verborgenen Muster in unbeschrifteten Daten zielt diese Technik darauf ab, solche Erkenntnisse aufzudecken, die zu besseren Ergebnissen führen können. Es kann als vorbereitender Schritt für überwachtes Lernen verwendet werden.
Unüberwachtes Lernen wird von Unternehmen genutzt, um aus Rohdaten aussagekräftige Erkenntnisse zu gewinnen, um die betriebliche Effizienz und andere Geschäftskennzahlen zu verbessern. Es wird häufig in den Bereichen digitales Marketing und Werbung verwendet. Einige der beliebtesten nicht überwachten Algorithmen sind K-means Clustering, Association Rule, t-SNE (t-Distributed Stochastic Neighbor Embedding) und PCA (Principal Component Analysis).
Es gibt zwei unüberwachte Lerntechniken:
Clustering – Clustering ist eine Untersuchungstechnik, die verwendet wird, um Daten ohne vorherige Informationen über die Cluster-Anmeldeinformationen in aussagekräftige Gruppen oder „Cluster“ zu kategorisieren (es basiert also ausschließlich auf ihren internen Mustern). Die Cluster-Credentials werden durch Ähnlichkeiten einzelner Datenobjekte und ihre Unterschiede zu den übrigen Objekten bestimmt. Clustering wird verwendet, um Tweets mit ähnlichen Inhalten zu gruppieren, die verschiedenen Arten von Nachrichtensegmenten zu trennen usw.
Dimensionalitätsreduktion – Die Dimensionalitätsreduktion wird verwendet, um eine bessere und möglicherweise einfachere Darstellung der Eingabedaten zu finden. Durch dieses Verfahren werden die Eingabedaten von redundanten Informationen bereinigt (oder zumindest die unnötigen Informationen minimiert), während alle wesentlichen Bits erhalten bleiben. Auf diese Weise ermöglicht es eine Datenkomprimierung und reduziert damit den Speicherplatzbedarf der Daten. Einer der häufigsten Anwendungsfälle von Dimensionality Reduction ist die Trennung und Identifizierung von E-Mails als Spam oder wichtige E-Mails.

- Halbüberwachtes Lernen
Halbüberwachtes Lernen grenzt zwischen überwachtem und unüberwachtem Lernen ab. Es stellt das Beste aus beiden Welten gegenüber, um einen einzigartigen Satz von Algorithmen zu erstellen. Beim halbüberwachten Lernen wird ein begrenzter Satz markierter Beispieldaten verwendet, um die Algorithmen zu trainieren, um die gewünschten Ergebnisse zu erzielen. Da es nur einen begrenzten Satz an beschrifteten Daten verwendet, erstellt es ein teilweise trainiertes Modell, das dem unbeschrifteten Datensatz Beschriftungen zuweist. Das Endergebnis ist also ein einzigartiger Algorithmus – eine Verschmelzung von beschrifteten Datensätzen und pseudobeschrifteten Datensätzen. Der Algorithmus ist eine Mischung aus den beschreibenden und prädiktiven Attributen des überwachten und nicht überwachten Lernens.
Halbüberwachte Lernalgorithmen werden häufig in der Rechts- und Gesundheitsbranche, bei der Bild- und Sprachanalyse und der Klassifizierung von Webinhalten eingesetzt, um nur einige zu nennen. Semi-überwachtes Lernen ist in den letzten Jahren aufgrund der schnell wachsenden Menge an unbeschrifteten und unstrukturierten Daten und der Vielzahl branchenspezifischer Probleme immer beliebter geworden.
- Verstärkungslernen
Reinforcement Learning zielt darauf ab, selbsttragende und selbstlernende Algorithmen zu entwickeln, die sich durch einen kontinuierlichen Zyklus von Versuchen und Fehlern basierend auf der Kombination und Wechselwirkung zwischen den gekennzeichneten Daten und den eingehenden Daten verbessern können. Reinforcement Learning verwendet die Exploration- und Exploitation-Methode, bei der eine Aktion stattfindet; Die Konsequenzen der Aktion werden beobachtet und basierend auf diesen Konsequenzen folgt die nächste Aktion – während versucht wird, das Ergebnis zu verbessern.
Sobald der Algorithmus während des Trainingsprozesses eine bestimmte/gewünschte Aufgabe ausführen kann, werden Belohnungssignale ausgelöst. Diese Belohnungssignale fungieren wie Navigationswerkzeuge für die Verstärkungsalgorithmen, die das Erreichen bestimmter Ergebnisse anzeigen und die nächste Vorgehensweise bestimmen. Natürlich gibt es zwei Belohnungssignale:
Positiv – Wird ausgelöst, wenn eine bestimmte Aktionssequenz fortgesetzt werden soll.
Negativ – Dieses Signal bestraft die Ausführung bestimmter Aktivitäten und fordert die Korrektur des Algorithmus, bevor es weitergeht.
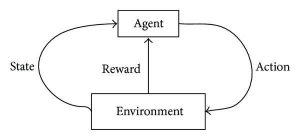
Quelle
Reinforcement Learning eignet sich am besten für Situationen, in denen nur begrenzte oder widersprüchliche Informationen verfügbar sind. Es wird am häufigsten in Videospielen, modernen NPCs, selbstfahrenden Autos und sogar in Ad-Tech-Operationen verwendet. Beispiele für Reinforcement-Learning-Algorithmen sind Q-Learning, Deep Adversarial Networks, Monte-Carlo Tree Search (MCTS), Temporal Difference (TD) und Asynchronous Actor-Critic Agents (A3C).
Was folgern wir dann aus all dem?
Algorithmen des maschinellen Lernens werden verwendet, um die in riesigen Datensätzen verborgenen Muster aufzudecken und zu identifizieren. Diese Erkenntnisse werden dann verwendet, um Geschäftsentscheidungen positiv zu beeinflussen und Lösungen für eine Vielzahl von Problemen aus der Praxis zu finden. Dank der Fortschritte in Data Science und maschinellem Lernen verfügen wir jetzt über ML-Algorithmen, die maßgeschneidert sind, um bestimmte Probleme und Probleme zu lösen. ML-Algorithmen haben Anwendungen und Prozesse im Gesundheitswesen sowie die Art und Weise, wie Unternehmen heute geführt werden, verändert.
Was sind die verschiedenen Algorithmen beim maschinellen Lernen?
Es gibt viele Algorithmen für maschinelles Lernen, aber besonders beliebt sind die folgenden: Lineare Regression: Kann verwendet werden, wenn die Beziehung zwischen Elementen linear ist. Logistische Regression: Wird verwendet, wenn die Beziehung zwischen Elementen nichtlinear ist. Neuronales Netzwerk: Implementiert eine Reihe miteinander verbundener Neuronen und verbreitet ihre Aktivierung im gesamten Netzwerk, um eine Ausgabe zu erzeugen. k-Nächste Nachbarn: Findet und zeichnet eine Reihe interessanter Objekte auf, die dem betrachteten benachbart sind. Support Vector Machines: Sucht nach einer Hyperebene, die die Trainingsdaten am besten klassifiziert. Naive Bayes: Verwendet das Theorem von Bayes, um die Wahrscheinlichkeit zu berechnen, dass ein bestimmtes Ereignis eintritt.
Was sind die Anwendungen des maschinellen Lernens?
Maschinelles Lernen ist ein Teilgebiet der Informatik, das sich aus dem Studium der Mustererkennung und der Theorie des computergestützten Lernens in der künstlichen Intelligenz entwickelt hat. Es ist verwandt mit Computerstatistiken, die sich auch auf Vorhersagen durch den Einsatz von Computern konzentrieren. Maschinelles Lernen konzentriert sich auf automatisierte Methoden, die die Software, die die Vorhersage durchführt, so modifizieren, dass sich die Software ohne explizite Anweisungen verbessert.
Was sind die Unterschiede zwischen überwachtem und unüberwachtem Lernen?
Überwachtes Lernen: Sie erhalten einen Satz X von Beispielen und die entsprechenden Labels Y. Ihr Ziel ist es, ein Lernmodell zu erstellen, das X auf Y abbildet. Diese Zuordnung wird durch einen Lernalgorithmus dargestellt. Ein gängiges Lernmodell ist die lineare Regression. Der Algorithmus ist der mathematische Algorithmus zum Anpassen einer Linie an die Daten. Unüberwachtes Lernen: Sie erhalten nur einen Satz X unbeschrifteter Proben. Ihr Ziel ist es, ohne Anleitung Muster oder Strukturen in den Daten zu finden. Sie können dafür Clustering-Algorithmen verwenden. Ein gängiges Lernmodell ist k-Means-Clustering. Der Algorithmus ist in den Cluster-Algorithmus eingebaut.