
Sebuah Intuisi Dibalik Analisis Sentimen: Bagaimana Melakukan Analisis Sentimen Dari Awal?
Diterbitkan: 2020-12-07Daftar isi
pengantar
Teks adalah sarana yang paling penting untuk memahami informasi bagi manusia. Sebagian besar kecerdasan yang diperoleh manusia adalah melalui belajar dan memahami makna teks dan kalimat di sekitar mereka.
Setelah usia tertentu, manusia mengembangkan refleks intrinsik untuk memahami kesimpulan dari kata/teks apa pun tanpa mengetahuinya. Untuk mesin, tugas ini sangat berbeda. Untuk mengasimilasi makna teks dan kalimat, mesin mengandalkan dasar-dasar Natural Language Processing (NLP).
Pembelajaran mendalam untuk pemrosesan bahasa alami adalah pengenalan pola yang diterapkan pada kata, kalimat, dan paragraf, dengan cara yang hampir sama seperti visi komputer adalah pengenalan pola yang diterapkan pada piksel gambar.
Tak satu pun dari model pembelajaran mendalam ini benar-benar memahami teks dalam arti manusia; melainkan, model ini dapat memetakan struktur statistik bahasa tertulis, yang cukup untuk menyelesaikan banyak tugas tekstual sederhana. Analisis sentimen adalah salah satu tugas tersebut, misalnya: mengklasifikasikan sentimen string atau ulasan film sebagai positif atau negatif.
Ini memiliki aplikasi skala besar di industri juga. Sebagai contoh: sebuah perusahaan barang dan jasa ingin mengumpulkan data dari jumlah review positif dan negatif yang telah diterima untuk produk tertentu untuk bekerja pada siklus hidup produk dan meningkatkan angka penjualan dan mengumpulkan umpan balik pelanggan.
Pra-pemrosesan
Tugas analisis sentimen dapat dipecah menjadi algoritma pembelajaran mesin terawasi sederhana, di mana kita biasanya memiliki input X , yang masuk ke fungsi prediktor untuk mendapatkan Kami kemudian membandingkan prediksi kami dengan nilai sebenarnya Y , Ini memberi kami biaya yang kemudian kami gunakan untuk memperbarui parameter Untuk mengatasi tugas mengekstrak sentimen dari aliran teks yang sebelumnya tidak terlihat, langkah primitif adalah mengumpulkan kumpulan data berlabel dengan sentimen positif dan negatif yang terpisah. Sentimen ini bisa berupa: ulasan baik atau ulasan buruk, komentar sarkastik atau komentar non-sarkastis, dll.
Langkah selanjutnya adalah membuat vektor dimensi V , di mana Vektor kosakata ini akan berisi setiap kata (tidak ada kata yang diulang) yang ada dalam kumpulan data kami dan akan bertindak sebagai leksikon untuk mesin kami yang dapat dirujuk. Sekarang kita melakukan preprocess vektor kosakata untuk menghilangkan redundansi. Langkah-langkah berikut dilakukan:
- Menghilangkan URL dan informasi non-sepele lainnya (yang tidak membantu menentukan arti kalimat)
- Tokenisasi string menjadi kata-kata: misalkan kita memiliki string “I love machine learning”, sekarang dengan tokenizing kita cukup memecah kalimat menjadi kata-kata tunggal dan menyimpannya dalam daftar sebagai [I, love, machine, learning]
- Menghapus stopword seperti “and”, “am”, “or”, “I”, dll.
- Stemming: kami mengubah setiap kata ke bentuk induknya. Kata-kata seperti “tune”, “tuning” dan “tuned” memiliki arti yang sama secara semantik, sehingga menguranginya ke bentuk induknya yaitu “tun” akan mengurangi ukuran kosakata
- Mengubah semua kata menjadi huruf kecil
Untuk meringkas langkah prapemrosesan, mari kita lihat sebuah contoh: katakanlah kita memiliki string positif “Saya menyukai produk baru di upGrad.com” . String akhir yang telah diproses sebelumnya diperoleh dengan menghapus URL, tokenizing kalimat menjadi satu daftar kata, menghapus stop words seperti “I, am, the, at”, kemudian stemming kata “loving” menjadi “lov” dan “product” menjadi “produ” dan akhirnya mengonversi semuanya menjadi huruf kecil yang menghasilkan daftar [lov, new, produ] .
Ekstraksi Fitur
Setelah corpus diproses, langkah selanjutnya adalah mengekstrak fitur dari daftar kalimat. Seperti semua jaringan saraf lainnya, model pembelajaran mendalam tidak mengambil teks mentah sebagai input: mereka hanya bekerja dengan tensor numerik. Daftar kata yang telah diproses sebelumnya perlu diubah menjadi nilai numerik. Ini dapat dilakukan dengan cara berikut. Asumsikan bahwa diberikan kompilasi string dengan string positif dan negatif seperti (anggap ini sebagai kumpulan data) :
| String positif | String negatif |
|
|
Sekarang untuk mengubah setiap string ini menjadi vektor numerik dimensi 3, kita membuat kamus untuk memetakan kata, dan kelas kemunculannya (positif atau negatif) ke berapa kali kata itu muncul di kelas yang sesuai.
| Kosakata | frekuensi positif | frekuensi negatif |
| saya | 3 | 3 |
| saya | 3 | 3 |
| senang | 2 | 0 |
| karena | 1 | 0 |
| sedang belajar | 1 | 1 |
| NLP | 1 | 1 |
| sedih | 0 | 2 |
| bukan | 0 | 1 |
Setelah membuat kamus yang disebutkan di atas, kami melihat masing-masing string secara individual, dan kemudian menjumlahkan angka frekuensi positif dan negatif dari kata-kata yang muncul dalam string meninggalkan kata-kata yang tidak muncul dalam string. Mari kita ambil string '"Saya sedih, saya tidak belajar NLP" dan menghasilkan vektor dimensi 3.

“Saya sedih, saya tidak belajar NLP”
| Kosakata | frekuensi positif | frekuensi negatif |
| saya | 3 | 3 |
| saya | 3 | 3 |
| senang | 2 | 0 |
| karena | 1 | 0 |
| sedang belajar | 1 | 1 |
| NLP | 1 | 1 |
| sedih | 0 | 2 |
| bukan | 0 | 1 |
| Jumlah = 8 | Jumlah = 11 |
Kami melihat bahwa untuk string "Saya sedih, saya tidak belajar NLP", hanya dua kata "senang, karena" tidak terkandung dalam kosakata, sekarang untuk mengekstrak fitur dan membuat vektor tersebut, kami menjumlahkan frekuensi positif dan negatif kolom secara terpisah meninggalkan nomor frekuensi kata-kata yang tidak ada dalam string, dalam hal ini kami meninggalkan "senang, karena". Kami memperoleh jumlah sebagai 8 untuk frekuensi positif dan 9 untuk frekuensi negatif.
Oleh karena itu, string "Saya sedih, saya tidak belajar NLP" dapat direpresentasikan sebagai vektor Angka "1" yang ada dalam indeks 0 adalah unit bias yang akan tetap "1" untuk semua string yang akan datang dan angka "8", "11" masing-masing mewakili jumlah frekuensi positif dan negatif.
Dengan cara yang sama, semua string dalam kumpulan data dapat dikonversi ke vektor dimensi 3 dengan nyaman.
Baca selengkapnya: Analisis Sentimen Menggunakan Python: Panduan Praktis
Menerapkan Regresi Logistik
Ekstraksi fitur memudahkan untuk memahami esensi kalimat tetapi mesin masih membutuhkan cara yang lebih tajam untuk menandai string yang tidak terlihat menjadi positif atau negatif. Di sini regresi logistik berperan yang memanfaatkan fungsi sigmoid yang menghasilkan probabilitas antara 0 dan 1 untuk setiap string yang divektorkan.

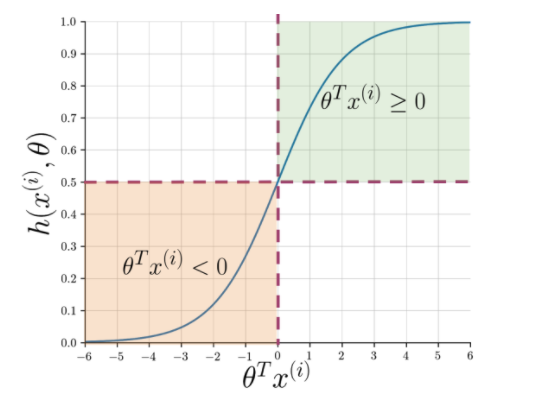
Gambar 1: Notasi grafis dari fungsi sigmoid
Gambar 1 menunjukkan bahwa setiap kali produk titik theta dan Baca Juga: 4 Ide Proyek Analisis Data Teratas: Tingkat Pemula hingga Ahli
Apa selanjutnya?
Analisis Sentimen adalah topik penting dalam pembelajaran mesin. Ini memiliki banyak aplikasi di berbagai bidang. Jika Anda ingin mempelajari lebih lanjut tentang topik ini, Anda dapat mengunjungi blog kami dan menemukan banyak sumber daya baru.
Di sisi lain, jika Anda ingin mendapatkan pengalaman belajar yang komprehensif dan terstruktur, juga jika Anda tertarik untuk mempelajari lebih lanjut tentang pembelajaran mesin, lihat Diploma PG IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk profesional yang bekerja dan menawarkan 450+ jam pelatihan yang ketat, 30+ studi kasus & tugas, status Alumni IIIT-B, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Q1. Mengapa Algoritma Hutan Acak terbaik untuk pembelajaran mesin?
Algoritma Random Forest termasuk dalam kategori algoritma pembelajaran yang diawasi, yang banyak digunakan dalam mengembangkan model pembelajaran mesin yang berbeda. Algoritme hutan acak dapat diterapkan untuk model klasifikasi dan regresi. Apa yang membuat algoritme ini paling cocok untuk pembelajaran mesin adalah kenyataan bahwa ia bekerja dengan sangat baik dengan informasi berdimensi tinggi karena pembelajaran mesin sebagian besar berkaitan dengan subset data. Menariknya, algoritma random forest diturunkan dari algoritma pohon keputusan. Namun, Anda dapat berlatih menggunakan algoritme ini dalam rentang waktu yang jauh lebih singkat daripada menggunakan pohon keputusan karena hanya menggunakan fitur tertentu. Ini menawarkan efisiensi yang lebih besar dalam model pembelajaran mesin dan karenanya lebih disukai.
Q2. Bagaimana pembelajaran mesin berbeda dari pembelajaran mendalam?
Pembelajaran mendalam dan pembelajaran mesin adalah subbidang dari keseluruhan payung yang kami sebut kecerdasan buatan. Namun, kedua subbidang ini memiliki perbedaan masing-masing. Pembelajaran mendalam pada dasarnya adalah bagian dari pembelajaran mesin. Namun, dengan menggunakan deep learning, mesin dapat menganalisis video, gambar, dan bentuk data tidak terstruktur lainnya, yang mungkin sulit dicapai hanya dengan menggunakan pembelajaran mesin. Pembelajaran mesin adalah tentang memungkinkan komputer untuk berpikir dan bertindak sendiri, dengan campur tangan manusia yang minimal. Sebaliknya, pembelajaran mendalam digunakan untuk membantu mesin berpikir berdasarkan struktur yang menyerupai otak manusia.
Q3. Mengapa ilmuwan data lebih memilih algoritma hutan acak?
Ada banyak manfaat menggunakan algoritme hutan acak, yang menjadikannya pilihan yang lebih disukai di antara para ilmuwan data. Pertama, ini memberikan hasil yang sangat akurat jika dibandingkan dengan algoritma linier lainnya seperti logistik dan regresi linier. Meskipun algoritme ini sulit untuk dijelaskan, lebih mudah untuk memeriksa dan menginterpretasikan hasil berdasarkan pohon keputusan yang mendasarinya. Anda dapat menggunakan algoritme ini dengan kemudahan yang sama bahkan ketika sampel dan fitur baru ditambahkan ke dalamnya. Mudah digunakan bahkan ketika beberapa data hilang.